2장에서는 캘리포니아 주택 가격 데이터셋을 활용해 머신러닝 프로젝트를 처음부터 끝까지 직접 진행해보면서 배우는 것을 목표로 한다.
큰 그림 보기
문제 정의
풀고자 하는 문제가 무엇인지 먼저 정의하는 것이 필요함. 그렇게 하여 문제 상황을 정확히 파악하고, 해당 문제에 적합한 시스템을 설계하게 됨.
지금 문제는 레이블된 훈련 샘플이 있고, 여러 특성을 통해 한 개의 값을 예측하므로 지도 학습, 단변량 회귀 문제가 됨.
성능 측정 지표 선택
회귀 문제에서는 일반적으로 평균 제곱근 오차, RMSE를 사용한다.
하지만, 이상치로 보이는 구역이 많은 경우, 평균 절대 오차, MAE를 사용하기도 한다.
둘 모두 예측값의 벡터와 타깃값의 벡터 사이의 거리를 재는 방식이다. 거리 측정에는 여러 방식을 사용할 수 있다.
- 유클리드 노름 :
RMSE계산과 같다. 노름이라고도 부른다. - 맨해튼 노름 : 절댓값의 합을 계산한다. 노름이라고도 부른다.
- 노름 =
가정 검사
시스템에서 요구로 출력을 하고 있는 출력이 현재 개발하고자 하는 모델의 출력과 일치한지 (ex: 가정에서는 수치형을 출력하고자 하는데 범주형을 요구한다던가) 확인해야한다.
데이터 가져오기
데이터 다운로드
아래 코드를 실행하면 데이터를 다운로드 할 수 있다.
from pathlib import Path
import pandas as pd
import tarfile
import urllib.request
def load_housing_data():
tarball_path = Path("datasets/housing.tgz")
if not tarball_path.is_file():
Path("datasets").mkdir(parents=True, exist_ok=True)
url = "https://github.com/ageron/data/raw/main/housing.tgz"
urllib.request.urlretrieve(url, tarball_path)
with tarfile.open(tarball_path) as housing_tarball:
housing_tarball.extractall(path="datasets")
return pd.read_csv("datasets/housing/housing.csv")
housing = load_housing_data()tarball_path에 있는 파일이 있는지 확인한다.
1-1. 만약 파일이 없다면,datasets폴더를 만들고 그 폴더에tgz파일을 다운로드받은 뒤, 압축 해제를 한다.- 파일을 pandas DataFrame으로 읽어온 결과를 리턴한다.
데이터 구조 훑어보기
head() 메서드를 사용하면 데이터의 첫 다섯 행을 읽어올 수 있다.

info() 메서드는 데이터에 관한 간략한 설명을 보여준다.
특히, 전체 행 수, 각 특성의 데이터 타입, 널이 아닌 값의 개수를 확인하는 데 유용하다.
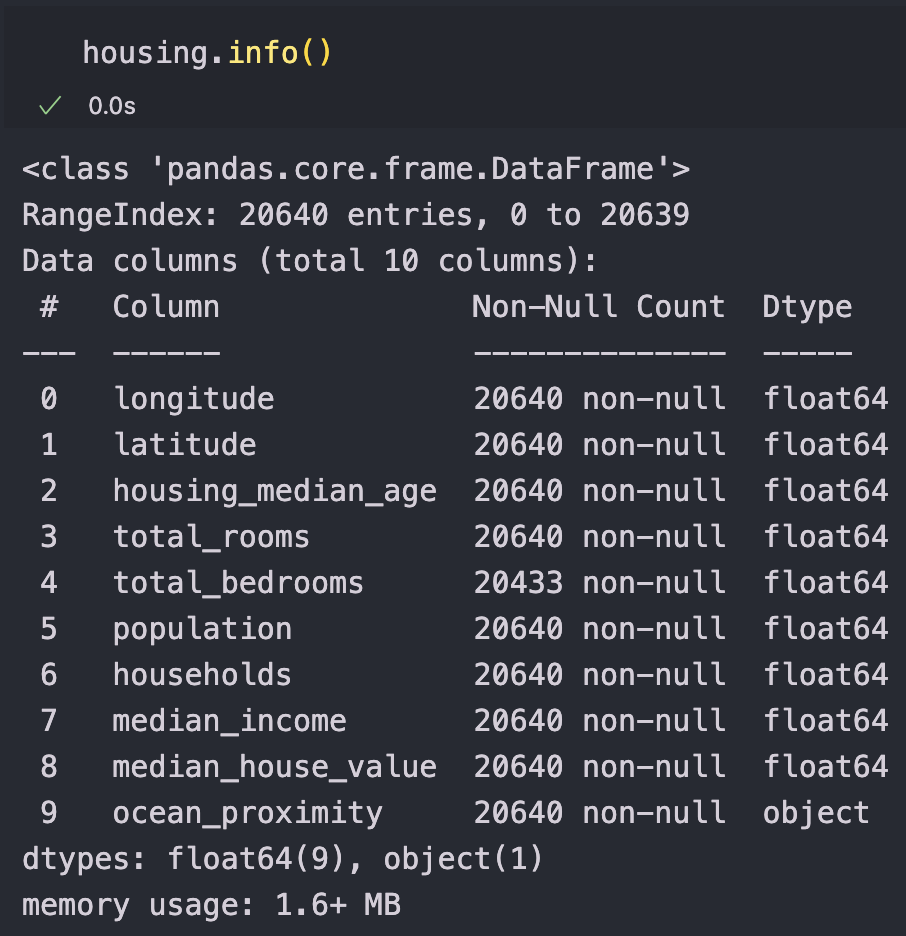
다음과 같은 정보를 알 수 있다.
- 전체 샘플 개수는 20640개이다.
total_bedrooms는 20433개만 널값이 아니다. 즉, 나머지 207개는 이 특성을 가지고 있지 않다.ocean_proximity필드를 제외한 모든 특성이 숫자형이다.
value_counts() 메서드는 어떤 카테고리가 있고, 각 카테고리마다 얼마나 많은 구역이 있는지 확인할 수 있다.
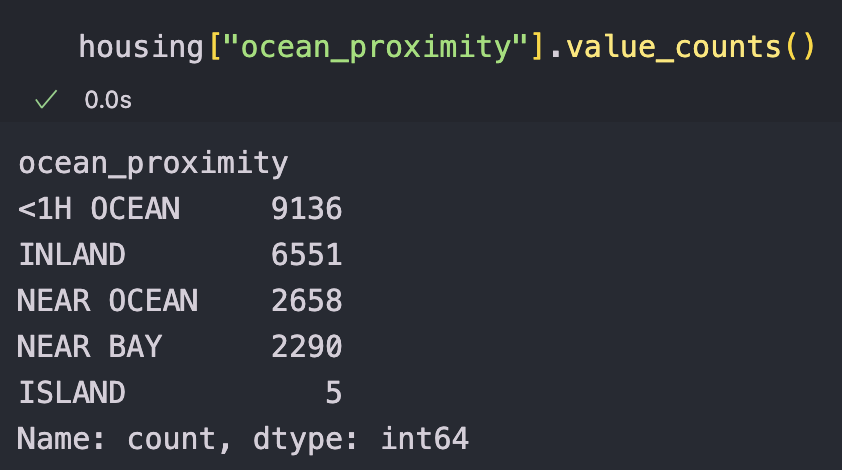

학부생