Recurrent Neural Network
💡 Core Idea of RNN
- Handling Variable-Length Sequences
- Image-to-Label은 고정된 크기의 input을 가지지만 Sequence-to-Label은 input size가 다양하게 변할 수 있다.
✔️ Bag-of-Words
- Classic way to handle variable-length sentences/documents
- 각 단어가 문장에서 등장하는 횟수를 센다.
- Vocab size가 50k이라고 하면, 모든 text, document, paragraph가 다 50k vector로 표현된다.
- 해당 50k vector는 거의 모든 것이 0이고, 몇몇의 component만 non-zero일 것이다.
- 문제 : 다른 meaning인데 같은 representation을 가질 수 있다.
➡️ Bag-of-Words로 represent하는 것은 optimal한 방법이 아니다.
✔️ Classical NLP
- 다양한 level의 분석을 할 때 각각에 서로 다른 방법을 써야했다. 이를 통해 다양한 level의 분석을 하고 이것을 기반으로 기계가 respond/generate with text하였다.
현재는 이러한 분석 없이 단지 human language를 거대한 model에 넣어 figure out할 수 있다.
Vanilla RNN
-
다양한 길이의 input/sequence를 represent할 수 있다.
-
h : hidden layer or memory
- 지금까지의 모든 input을 memorize한다.
-
Variable-length sequence를 다루기 위해 각 timestep에서 동일한 weight를 사용한다.
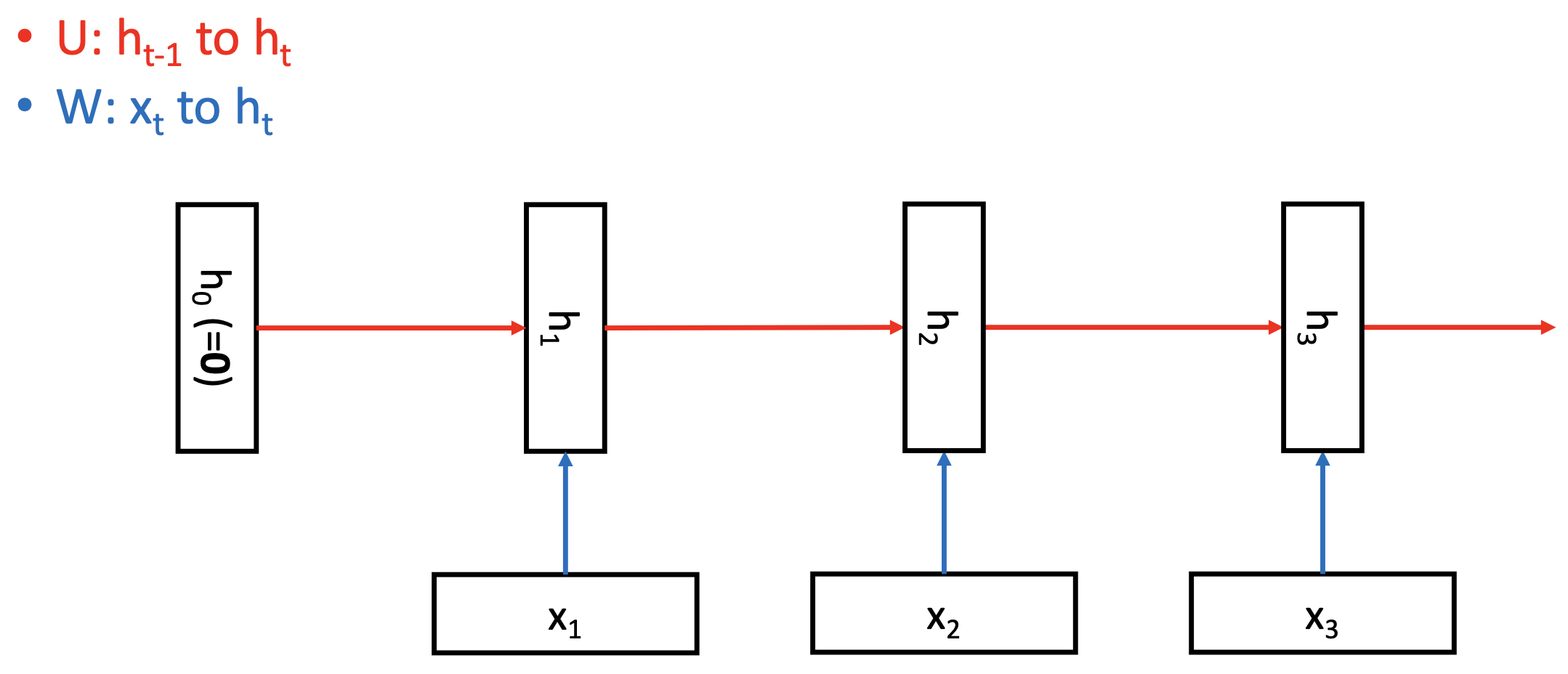
- U : Transforming previous memory into current memory
- W : Transforming current input to current memory
-
각 timestep마다 새로운 정보가 들어오고, 반복적으로 같은 weight를 사용하는 feedforwar neural network라고 볼 수 있다.
🔗 Sequence prediction with RNN
- Sentiment classification: Positive or Negative
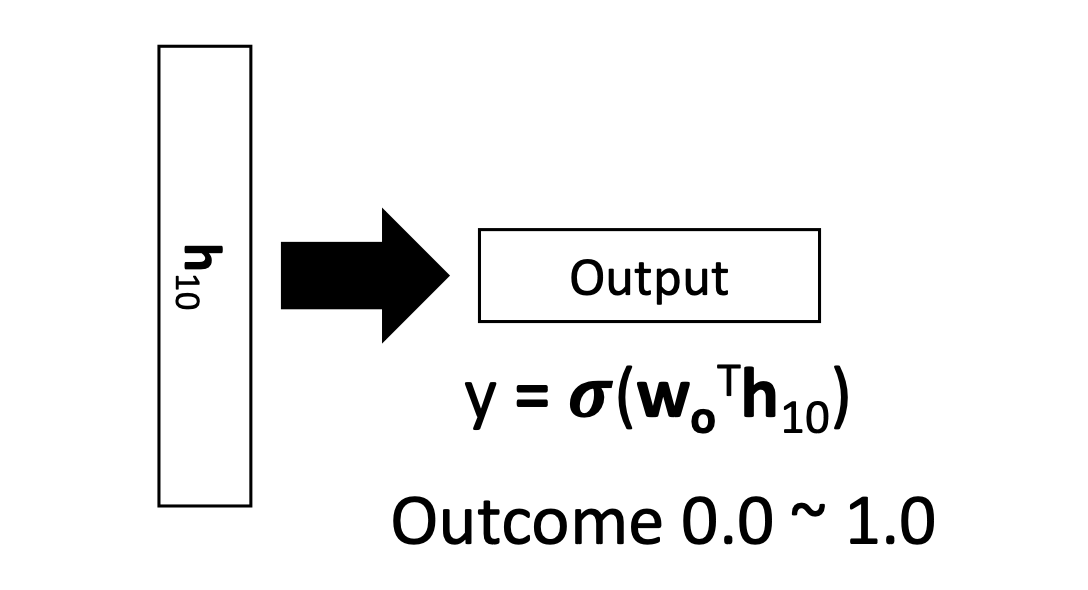
- h_10은 이론적으로 지금까지 나왔던 전체 sentence를 기억하는 sentence representation이다.
- h_10으로 logistic regression을 통해 classification을 한다.
- Optimize 해야하는 parameter : , , , b
Bag-of-Words에서는 sparse한 dimensional vector(ex. 50k)였는데 이제는 더 compact한 sentence representation을 얻을 수 있다.
Language Modeling
Language Modeling은 text를 generate하는 용도로 쓰이지만, academic 의미로는 전체 sentence중에서 주어진 sentence가 나올 확률을 quantify/calculate하고자 하는 것이다. (그리고 그 확률은 매우 작다.)

p(|,,...,w_(t-1)) 이 확률을 modeling할 수 있으면, text probability/likelihood를 계산할 수 있다.
이것이 Language Modeling이다.
🔗 Classical approach of doing Language Modeling
- n-gram
- bigram이라고 하면, 현재 word의 probability를 계산할 때, 그 전 1개의 word만 봐도 된다고 가정하고 그 전 1개의 word만 본다.
- 문제: p(|w_(t-1)) conditional probability를 모두 계산해놔야 한다. 시간이 많이 소요되어, 확장이 어렵다.
🔗 Language Modeling with RNN
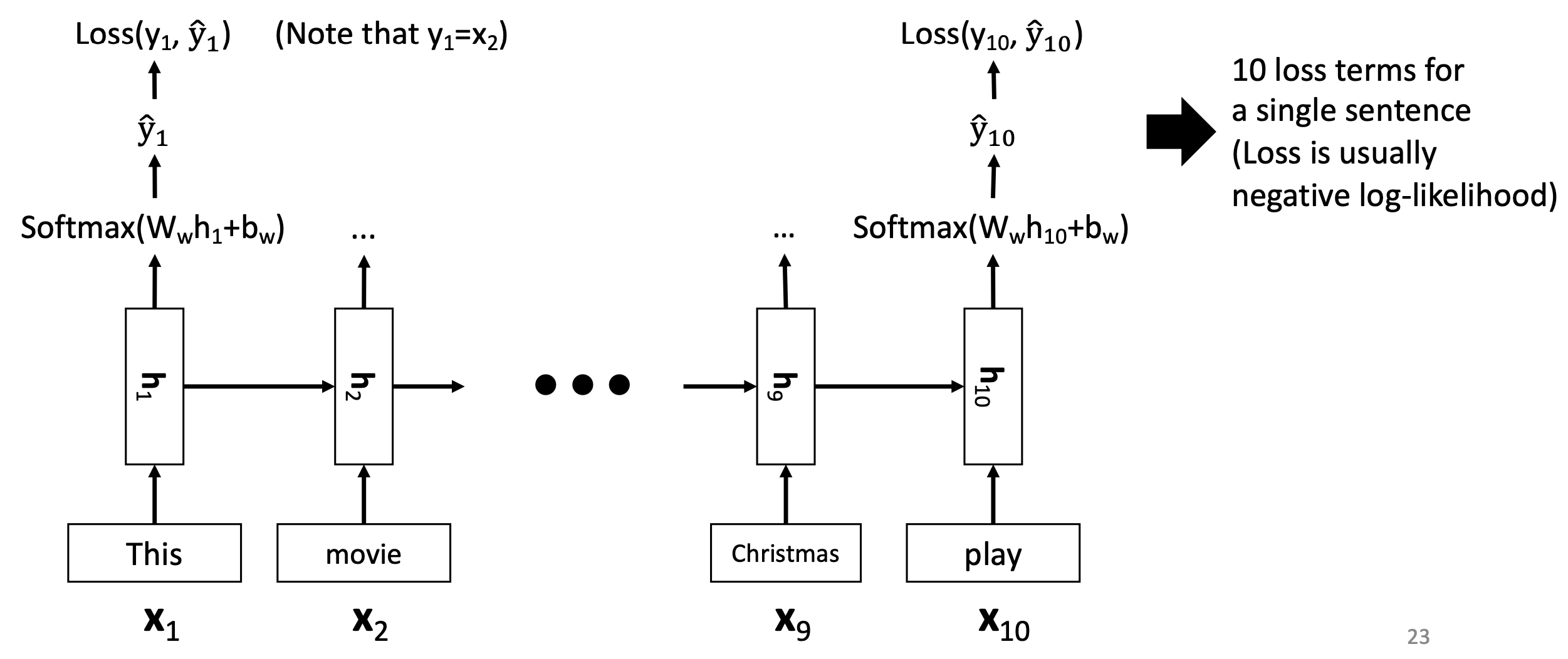
RNN을 잘 train하여 p(|,,...,w_(t-1))를 정확하게 계산할 수 있으면
1. calculate probability of sentence
2. Use probability to sample new sentence
- Autoregressive sampling
- EOS에 도달할 때까지
이 두 가지를 다 할 수 있다.
Bidirectional RNN
💡 Motivation
- 문장이 너무 길어지면 h_50이나 h_49는 h_1이나 h_2를 잊어버릴 수 있다.
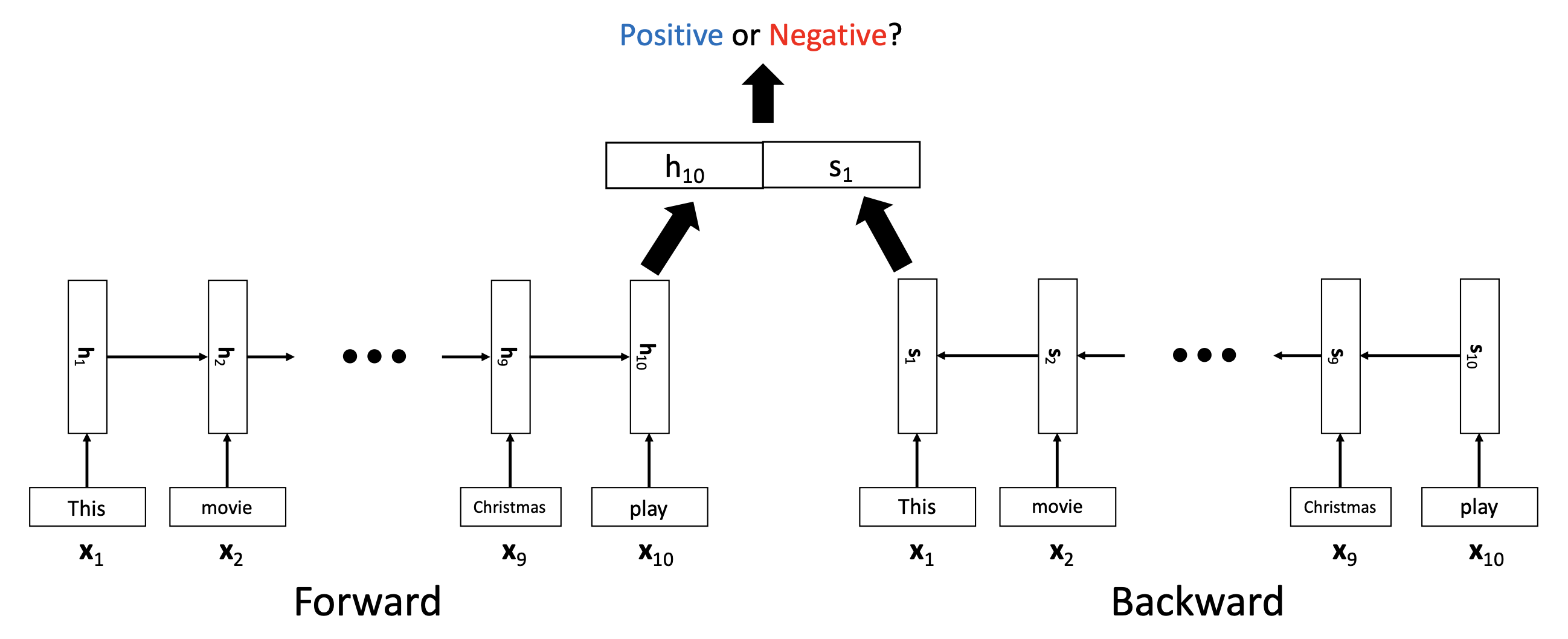
- Forward로 가는 RNN, backward로 가는 RNN 이렇게 2개를 동시에 사용한다.
- h는 last part를 명료하게 기억할 것이고, s는 first part를 명료하게 기억할 것이므로 서로를 보완할 수 있다.
- 그리고 h_10과 s_1을 horizontally concatenate하여 이것을 logistic regression이나 softmax classification에 사용한다.
🔗 Limitation
- Vanishing gradient problem
- Input from a distant past is forgotten
- Exploding gradient problem
- Popular remedy: gradient clipping
GRU
💡 Core idea
- Update gate와 Reset gate를 두어 어떤 정보를 future로 보내고 어떤 정보를 future로 보내지 않을 지 컨트롤한다. 이를 통해 더 긴 time step을 기억할 수 있다.
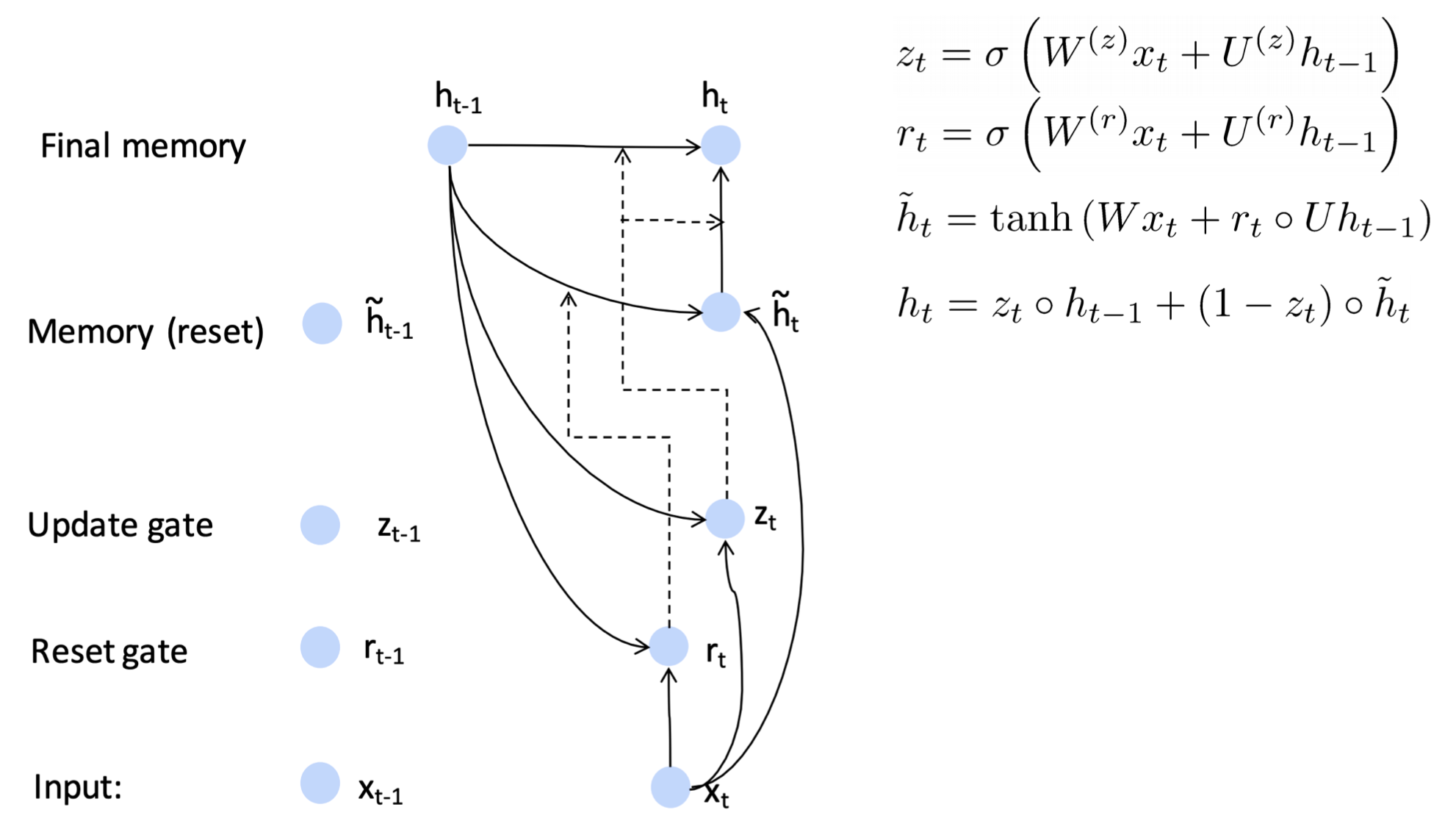
- Reset gate : 이전 hidden layer가 얼마나 h tilda에 영향을 줄지를 컨트롤 한다.
- : convex combination between new memory and previous memory
LSTM
💡 Core idea
- 핵심 철학은 GRU와 같다. 어떤 정보를 future로 보내고 어떤 정보를 future로 보내지 않을 지 컨트롤한다. GRU보다 한 개의 gate를 더 가지고 있다.

Sequence-to-sequence
- Given variable-length sequence input,
Predict (Generate) variable-length sequence output - 그 전과 다른점: Require zero-domain knowledge
🔗 Machine Translation
- Encoder의 마지막 hidden layer가 Decoder의 initial state가 된다.
- : input sentence representation
- Decoder에는 start token을 input으로 넣고 시작한다.
- At training phase
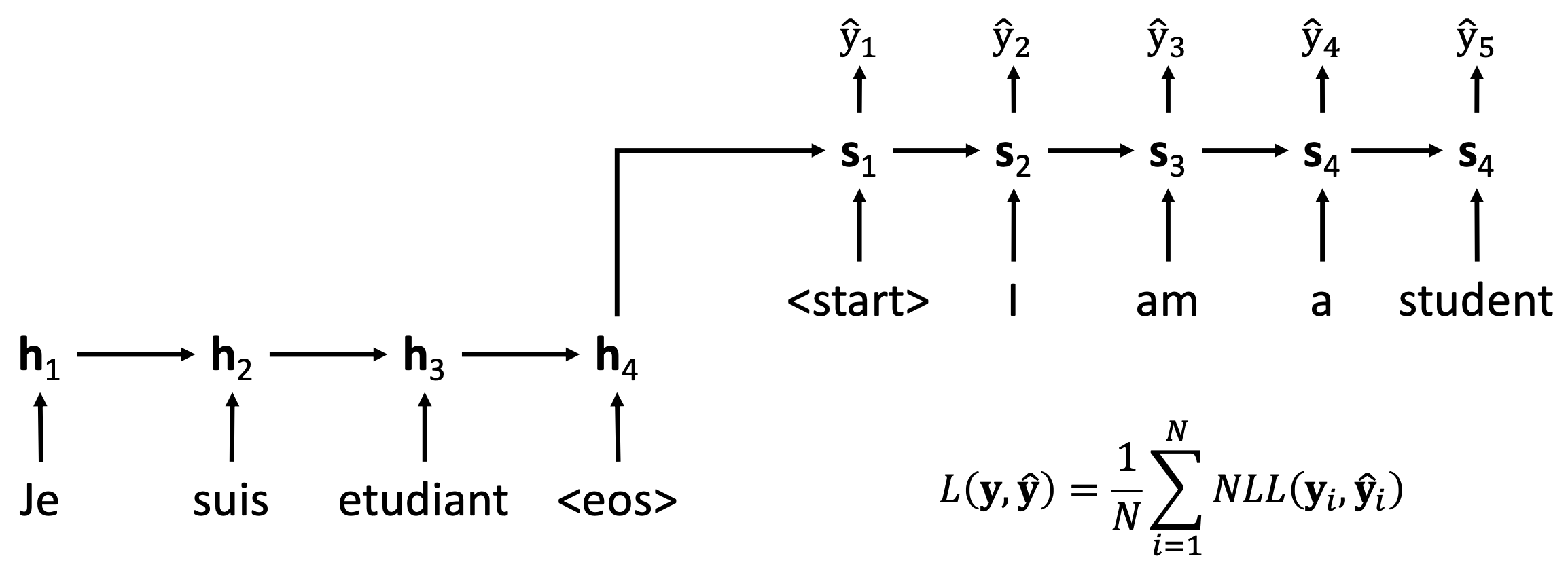
- Decoder input은 ground true tokens (Teacher Forcing)
- Predicted outputs에 negative log-likelihood 적용
- End-to-end train
- At test phase
- Decoder input은 previous predicted token (Autoregressive input)
- EOS token이 predicted될 때까지 반복, EOS token 만나면 translation 종료
Attention
Machine translations의 성능을 높이기 위해 제안되었다.
이전까지의 모든 RNN based architecture는 아무래도 과거 정보를 까먹는 경향이 있다. 그래서 마지막 hidden layer가 이전 word들을 잘 기억한다는 보장이 없다.
💡 Core Concept
- Prediction을 할 때 모든 timestep의 hidden layer를 사용한다.
🔗 Attention mechanism in sequence-level classification
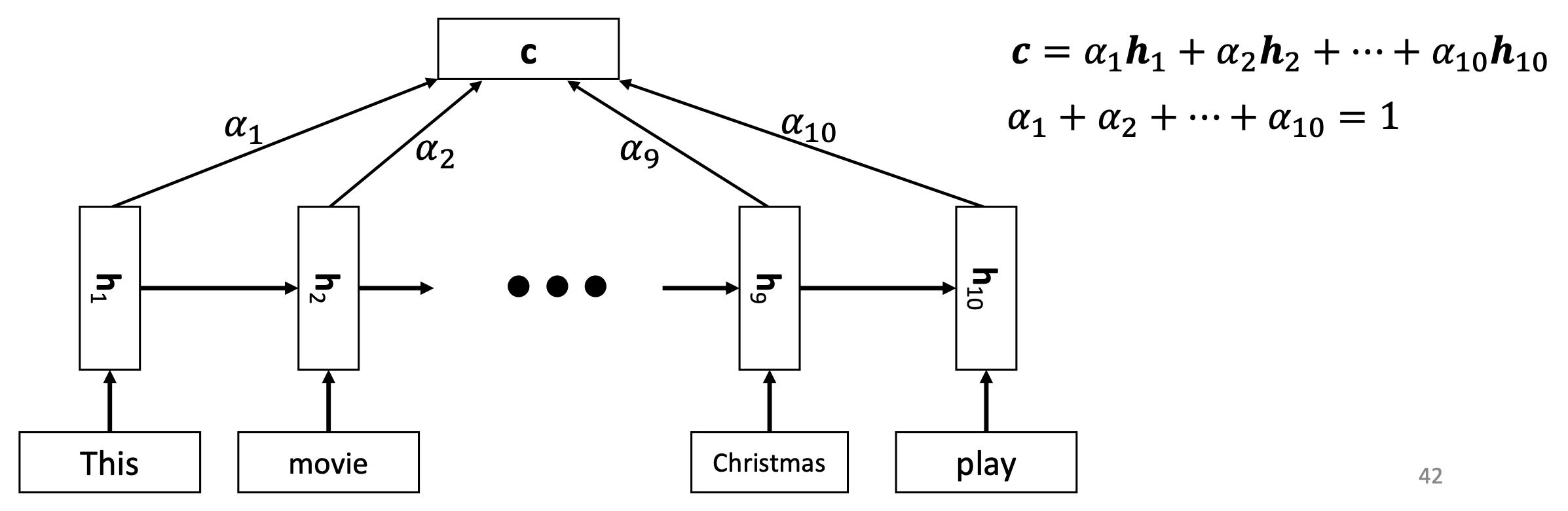
- 모든 time step에서의 hidden layer를 가져와 weighted sum을 하고 그것을 logistic regression에 사용한다.
- c is convex sum of hs.
🔗 Attention이 중요한 2가지 이유
1. Increasing performance
2. Enabling/facilitating interpretation
- c는 explicit combination of all past information이다.
- output을 predict할 때, 어떤 word가 가장 많이/적게 사용되었는지, 중요했는지 알 수 있다.
- Model의 내부 동작을 interpret할 수 있다.
🔗 How to generate the attentions ?
또다른 (2-layer) feedforward neural network model을 사용한다.
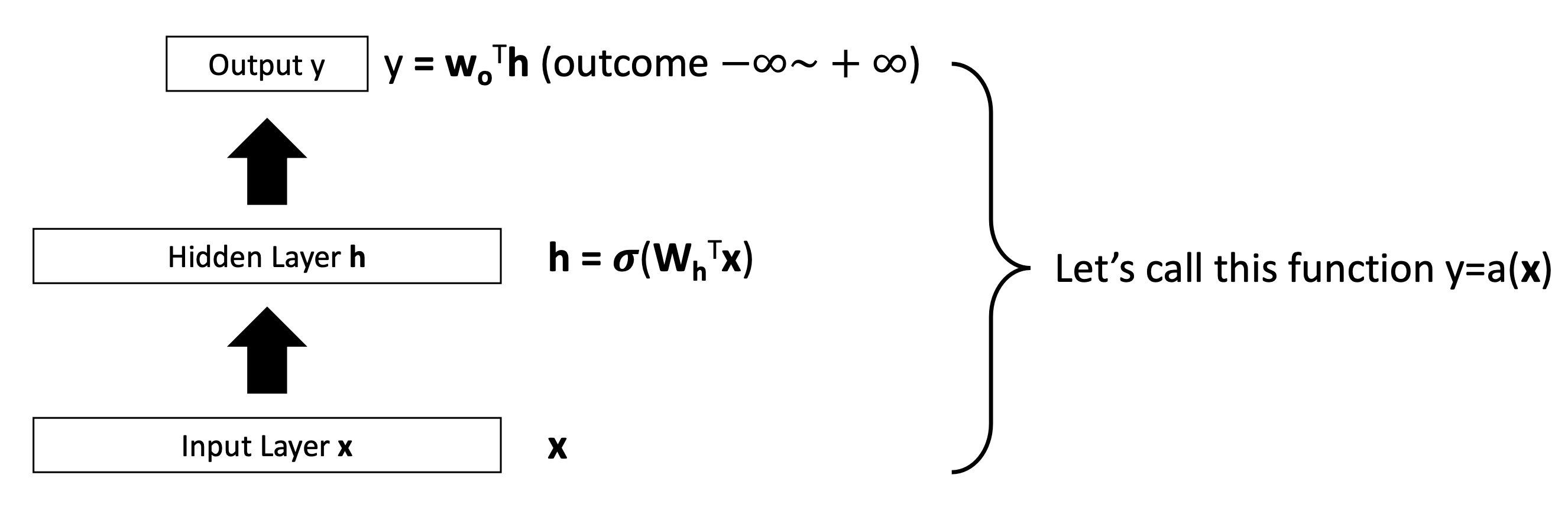
그리고 output score를 softmax function에 feed한다.
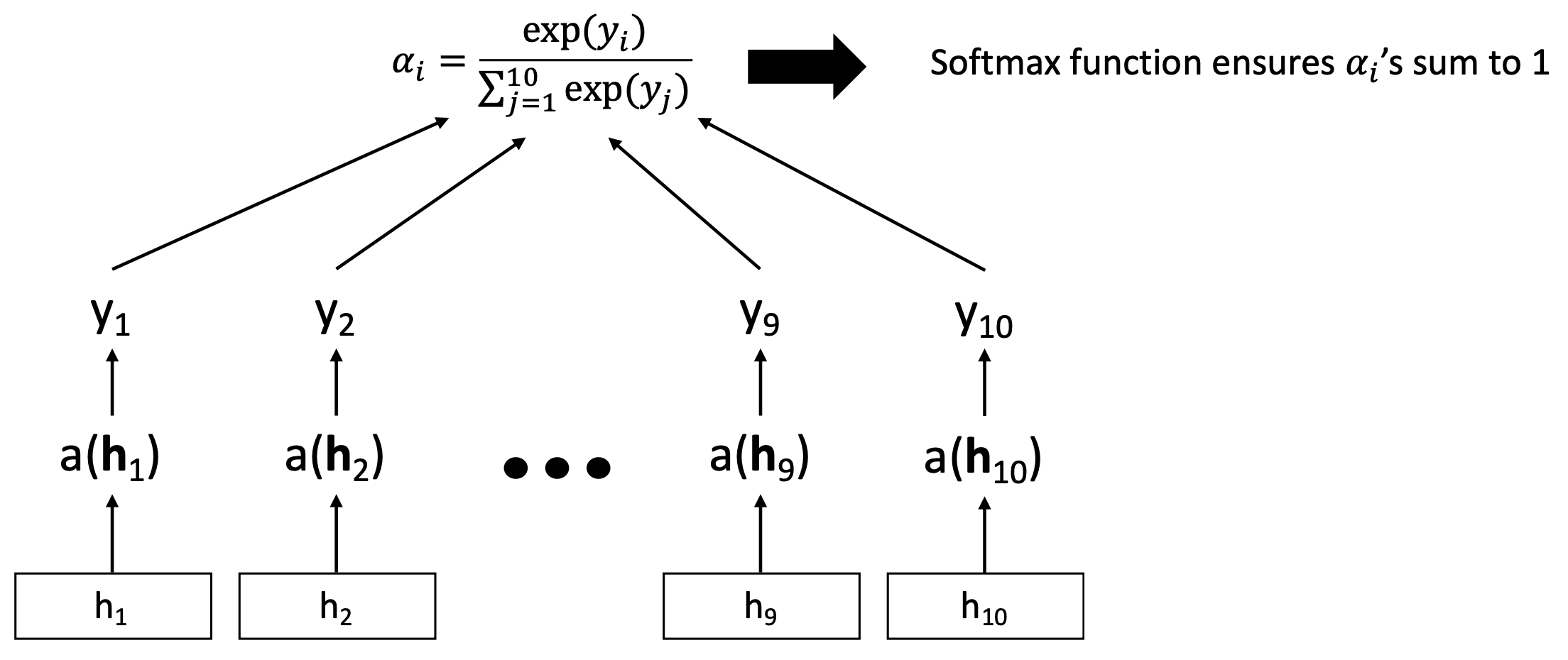
🔗 Attention mechanism in Seq2Seq
✔️ Attentionless Seq2Seq architecture
- 가 fixed되어있고, 를 predict할 때 가 계속 재사용된다.
매 time step마다 를 predict할 때, hs를 mix하여 context vector를 만든다.
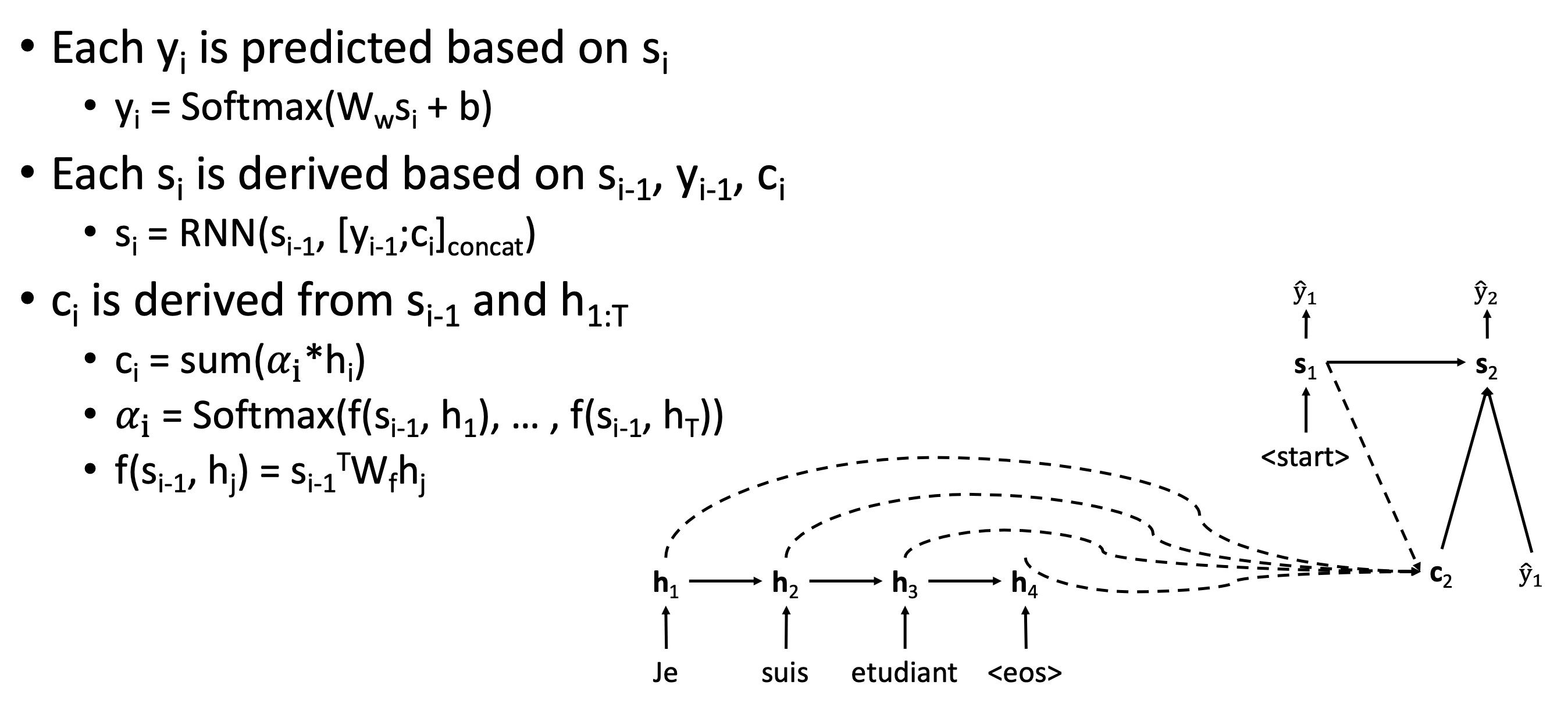
- 항상 s_(i-1)과 hs간의 compatibility를 계산한다.
Reference
- AI504: Programming for AI Lecture at KAIST AI
