Phase Structure?(= context-free grammars)
organizes words into nested constituents.
Dependency Structure?
어떤 단어가 다른 어떤 단어에 의존하는지 나타냄
sentence structure가 필요한 이유?
- 모델은 언어를 정확하게 해석하기 위해 문장의 구조, sentence structure를 이해하고 있어야 한다.
Dependency syntax은 syntactic structure가 단어들간의 관계를 포함한다고 가정한다.
depencency = arrows = binary asymmetric relations
= commonly typed with the name of grammatical relations(subject, prepositional object, apposition, etc)
Language Model
language modeling
- 다음에 나타나는 단어를 예측하는 모델
- 혹은, 텍스트 조각에 확률을 부여하는 시스템이라고도 볼 수 있다.
the students open their _?___ ->(books, laptops, exams, minds)
- can be used to generate text
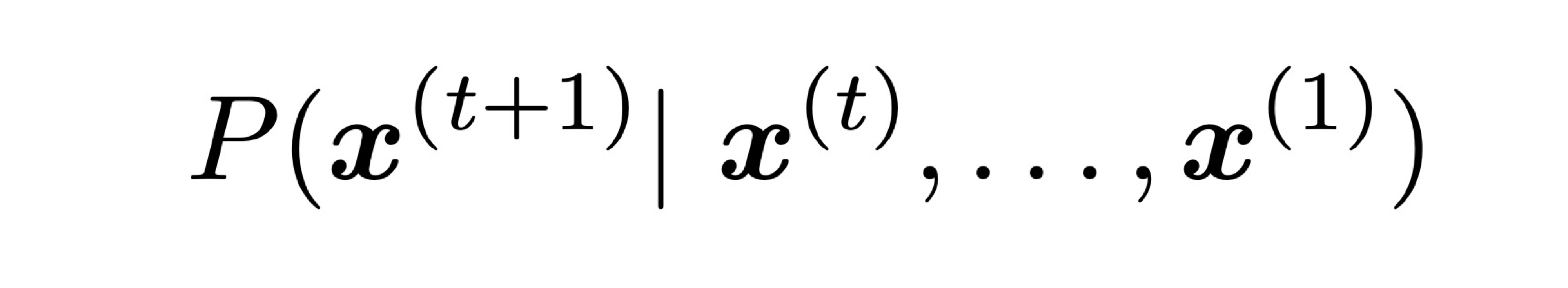
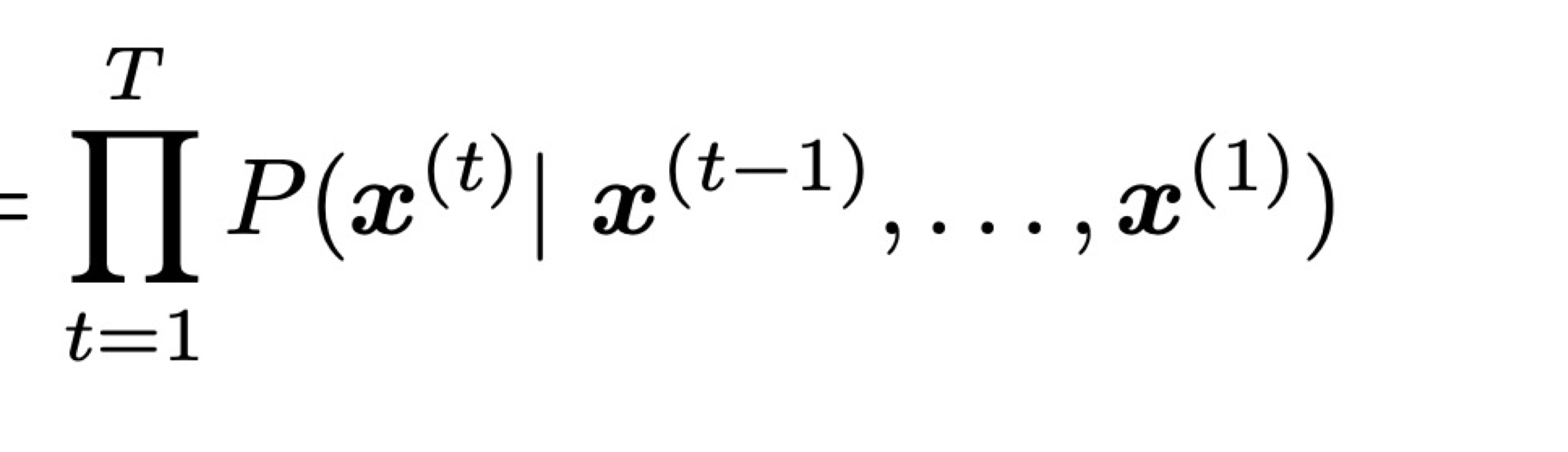
n-gram language model
Q. how to learn an LM?
A. (딥러닝 출현 전): learn ann-gram Language Model!!
n-gram: chunk of n consecutive words(n개의 연속적인 단어 뭉치)
- Markov assumption: x(t+1) depends only on the preceding n-1 words

- Then how do we get n, n-1 gram probabilities?
-> by counting them in some large corpus of text! (statistical approximation)count(x(t+1), x(t), ..., x(t-n+2))/count(x(t), ..., x(t-n+2))
EXAMPLE
"students opened their" occurred 1000times
- "students opened their books" occurred 400 times -> 0.4
- "students opened their exams" occurred 100 times -> 0.1
PROBLEMS
- sparsity problem: 분모/분자가 0이 될 때(경우의 수/사례가 존재하지 않는 경우)
- n이 커질수록 sparsity problem은 커진다. 보통 n < 5.
- Storage Problem: 말뭉치에서 세어지는 n-gram개수들을 모두 저장해야 함.
- n 또는 corpus가 커지는 경우 모델 사이트가 커진다.
RNN Language Models
Advantage:
- can process any length input
- step t의 계산에 여러 step전의 정보를 사용할 수 있다.(이론적으로)
- input context가 길어진다고 모델 사이즈가 커지지는 않는다.
- 같은 weight이 모든 timestep에 적용되기 때문에 input이 처리되는 과정에 symmetry가 존재한다.
Disadvantage:
- Recurrent computation: 느리다.
- many steps back info: difficult to access.

NLP