ElasticSearch 8.xx
Stcokey프로젝트를 마무리하고 아쉬운 부분에 대한 리팩토링을 진행!
Express
기존 검색 방법
기존에는 검색어에 따른 결과를 SQL의 "LIKE"를 사용하여 검색결과를 반환하도록 API를 설계했다.
이는 LIKE 연산이 인덱스를 효과적으로 활용하지 못하여 성능저하가 일어난다.
exports.getSearchByKeyword = async (keywordName) => {
try {
const keywords = await Keyword.findAll({
where: {
keyword: {
[Sequelize.Op.like]: `${keywordName}%` // 'keyword' 컬럼에서 'keywordName'으로 시작하는 값을 찾기
}
},
attributes: [
[Sequelize.fn('MAX', Sequelize.col('id')), 'id'],
'keyword', // keyword 컬럼
[Sequelize.fn('SUM', Sequelize.col('weight')), 'totalWeight'] // weight 값을 합산하여 totalWeight로 반환
],
group: ['keyword'], // keyword 기준으로 그룹화
order: [
[Sequelize.fn('SUM', Sequelize.col('weight')), 'DESC'] // totalWeight가 높은 순서대로 정렬
],
limit: 10 // 최대 10개만 반환
});
return keywords
} catch (err) {
throw new Error(err)
}
}변경된 검색 방법
ElasticSearch 인덱스에 DB에 저장되어있는 데이터를 인덱싱하고 데이터를 가져올 수 있도록 변경하였다.
과정은 아래와 같다.
1. ElasticSearch 이미지 가져오기
docker pull elasticsearch:8.12.12. 이미지를 통해 컨테이너 실행
docker run -d --name stockey-elasticsearch \
-p 9200:9200 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
elasticsearch:8.12.1elasticsearch 8.x 버전부터는 보안 기능이 추가되어 HTTPS 환경에서만 사용할 수 있다.
현재는 개발서버이고 배포한 웹사이트에 SSL/TLS를 적용하지않았다.
위와 같은 이유로 보안기능은 비활성화해두었다.
3. Node.js에 ElasticSearch 설치
npm install @elastic/elasticsearch4. elasticSearch.js 정의
- ElasticSearch 클라이언트를 초기화
const { Client } = require('@elastic/elasticsearch');
const Keyword = require('./models/Keyword')
const client = new Client({
node: 'http://localhost:9200'
});- 인덱스 생성
// 인덱스를 생성하는 함수 -> DB로 따지면 테이블 생성 + 컬럼
async function createIndex() {
try {
const exists = await client.indices.exists({ index: 'keywords'})
if (!exists) {
const response = await client.indices.create({
index: 'keywords',
body: {
settings: {
analysis: {
tokenizer: {
nori_tokenizer: {
type: 'nori'
}
},
filter: {
nori_filter: {
type: 'nori'
}
},
analyzer: {
nori_analyzer: {
type: 'custom',
tokenizer: 'nori_tokenizer',
filter: ['nori_filter']
}
}
}
},
mappings: {
properties: {
keyword: {
type: 'text',
analyzer: 'nori_tokenizer'
},
weight: {type: 'float'},
stock_id: {type: 'long'}
}
}
}
})
console.log("Elasticsearch 인덱스 생성 완료: ", response);
} else {
console.log("Elasticsearch 인덱스가 이미 존재합니다.")
}
} catch (error) {
console.log("ElasticSearch 인덱스 생성 중 오류 발생: ", error.message)
}
}const exists = await client.indices.exists({ index: 'keywords'})해당 코드를 통해 인덱스의 존재 유무를 파악하고 존재한다면 생성하지않는다.
Elasticsearch은
Tokenizer를 통해 문서를 작은 단위로 분할하고 분할된 텍스트를Token이라고 합니다
또한 Elasticsearch의 기본 분석기는 영어 기반으로 설계되었습니다.
한글을 분석하기 위해서는 한글 형태소 분석기를 사용해야한다.
- 대표적으로
nori가 있다. 카카오에서 개발한거라고 하니 믿고 사용하자..nori는 Elasticsearch에서 공식적으로 지원된다.
=> 믿고 사용하자👍
Elasticsearch를 사용하면서 여러개의 데이터를 넣을때 매번 하나씩 데이터를 넣는 일은 네트워크의 잦은 IO의 발생으로 성능을 저하 시킬 수 있는 요인.
=>bulk API사용
bulk: 여러 개의 처리를 모아 두었다가 한번에 처리하는 Batch 처리 기능.
- DB에서 데이터를 가져와서 인덱싱.
// 인덱싱하는 함수 -> DB로 따지면 테이블에 값을 주입
async function indexingKeywords() {
const keywords = await Keyword.findAll();
const BATCH_SIZE = 1000;
const body = [];
for (let i = 0; i < keywords.length; i++) {
body.push({ index: {_index: 'keywords', _id: keywords[i].id}});
body.push({stock_id: keywords[i].stock_id, keyword: keywords[i].keyword, weight: keywords[i].weight})
if (body.length >= BATCH_SIZE * 2) {
await sendBulkRequest(body);
body.length = 0;
}
}
if (body.length > 0) {
await sendBulkRequest(body)
}
console.log("ElasticSearch 인덱싱 완료")
}
// bulk 요청을 보내는 함수
async function sendBulkRequest(body) {
try {
const response = await client.bulk({ body });
const failedDocuments = response.items.filter(item => item.index.error);
if (failedDocuments.length > 0) {
console.log('실패한 문서:', failedDocuments);
}
} catch (error) {
console.error("ElasticSearch 인덱싱 중 오류 발생:", error.message);
}
}
async function init() {
await createIndex();
await indexingKeywords();
}
init();init()을 통해 ElasticSearch.js 모듈을 불러오기만해도 실행되도록 설정하였다.
5. elasticSearchService.js 정의
const { client } = require('../elasticSearch')
// 키워드 검색 함수
exports.searchKeywordsByES = async (keywordName) => {
const response = await client.search({
index: 'keywords',
query: {
wildcard: {
keyword: {
value: `*${keywordName}*`
},
}
},
aggs: {
grouped_keywords: {
terms: {
field: 'keyword.keyword',
size: 10,
order: { "totalWeight" : "desc"}
},
aggs: {
totalWeight: {
sum: {
field: 'weight'
}
},
first_id: {
top_hits: {
size: 1,
_source: []
}
}
}
}
},
size: 0
})
const results = response.aggregations.grouped_keywords.buckets.map(bucket => ({
keyword: bucket.key,
totalWeight: bucket.totalWeight.value,
id: bucket.first_id.hits.hits[0]._id
}))
console.log(results)
return results
}// 상위 키워드 TOP 1 반환
exports.topKeywordByES = async () => {
const response = await client.search({
index: 'keywords',
query: {
match_all: {}
},
aggs: {
top_keyword: {
terms: {
field: 'keyword.keyword',
size: 1,
order: {"totalWeight": "desc"}
},
aggs: {
totalWeight: {
sum: {
field: "weight"
}
},
first_id: {
top_hits: {
size: 1,
_source: []
}
}
}
}
},
size: 0
})
const topKeyword = response.aggregations.top_keyword.buckets[0];
const result = [{
keyword: topKeyword.key,
keyword_id: topKeyword.first_id.hits.hits[0]._id,
totalWeight: topKeyword.totalWeight.value,
}]
return result;
}[옵션 정리]
| 용어 | 설명 |
|---|---|
| index | Elasticsearch에서 데이터를 저장하는 논리적인 저장소. DB와 유사한 개념 |
| query | 검색 시 사용되는 조건을 정의하는 부분. Elasticsearch의 쿼리 DSL을 사용하여 다양한 검색 조건을 설정할 수 있습니다. |
| wildcard | 와일드카드 문자를 사용하여 패턴 매칭을 수행하는 쿼리. *는 0개 이상의 문자와 일치하며, ?는 정확히 하나의 문자와 일치합니다. |
| match | 주어진 텍스트를 분석하여 토큰화한 후, 해당 토큰이 포함된 문서를 찾는 쿼리. |
| keyword | Elasticsearch에서 분석되지 않은 텍스트 필드로, 정확한 값 검색에 사용됩니다. 예: 이메일 주소나 국가 코드와 같은 필드 |
| value | 검색할 값을 지정하는 부분. 예를 들어, *${keywordName}*은 keywordName 변수를 포함하는 모든 값을 검색합니다. |
| grouped_keywords | 집계의 이름. 결과를 그룹화하는 기준을 정의 |
| terms | 주어진 필드의 고유한 값들을 기준으로 문서를 그룹화하는 집계. 예시에서는 keyword.keyword 필드를 기준으로 그룹화 |
| field | 집계나 쿼리에 사용할 필드를 지정 |
| size | 검색 결과에 반환할 문서의 수 |
| order | 집계 결과를 정렬하는 기준을 정의 |
| sum | 지정된 필드의 값을 모두 합산하는 집계 |
| first_id | 각 그룹에서 첫 번째 문서의 정보를 가져오는 집계의 이름 |
| top_hits | 각 그룹의 상위 N개의 문서를 가져오는 집계. 예시에서는 size: 1로 설정하여 각 그룹의 첫 번째 문서만 가져옵니다. |
| _source | 문서의 원본 데이터를 포함하는 부분 |
Aggregations (agg옵션)
데이터를 집계하고 분석하는 강력한 기능을 제공하며, 이를 통해 대규모 데이터를 효율적으로 처리하고, 다양한 통계나 인사이트를 얻을 수 있습니다. Aggregation은 주로
Bucket, Metrics, Pipeline으로 구분되며, 각 유형은 서로 다른 방식으로 데이터를 처리합니다.
1. Bucket Aggregation (버킷 집계)
Bucket Aggregation은 데이터를 특정 기준으로 그룹화하는 방식입니다. 이 집계는 입력 데이터를 여러 그룹으로 나누고, 각 그룹에 대해 추가적인 집계를 수행할 수 있게 합니다. 각 그룹은 버킷(bucket)이라 불리며, 각 버킷은 문서의 집합을 나타냅니다.
2. Metrics Aggregation (메트릭스 집계)
Metrics Aggregation은 숫자 기반의 계산을 수행하는 데 사용됩니다. 이 집계는 각 그룹이나 전체 데이터에 대해 합계, 평균, 최댓값, 최솟값, 표준편차 등을 계산할 수 있습니다.
3. Pipeline Aggregation (파이프라인 집계)
Pipeline Aggregation은 다른 집계의 결과를 후처리하여 새로운 결과를 계산하는 집계입니다. 예를 들어, 여러 집계의 결과를 이용해 비율 계산, 누적 합 등을 구할 수 있습니다. 이 집계는 주로 버킷 집계나 메트릭스 집계의 결과를 기반으로 합니다.
결과
Node.js의 라이브러리 Artillery를 통해 요청을 보낸 결과 성능이 크게 향상된 것을 확인할 수 있었습니다.
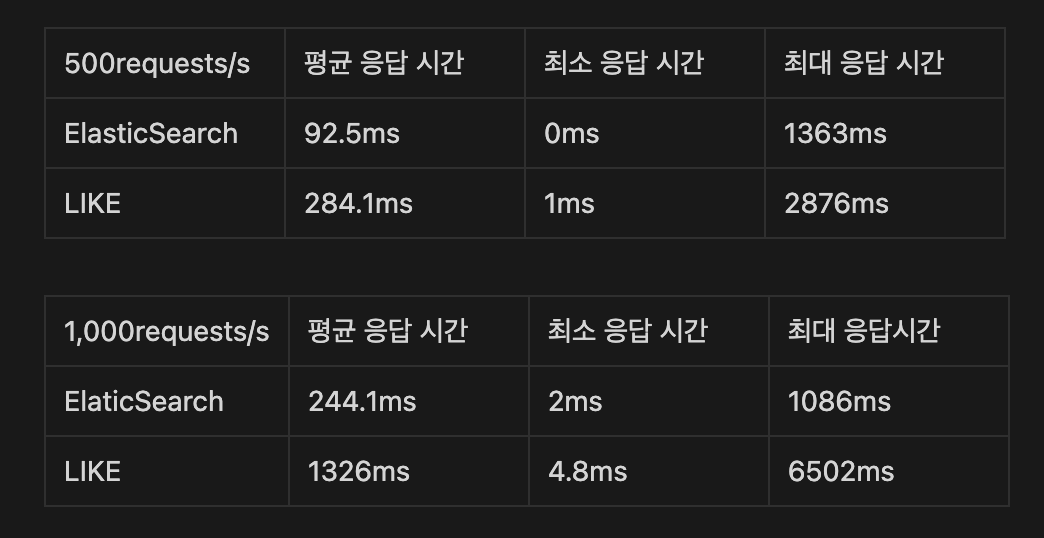
트러블 슈팅
1. 보안
elasticsearch 8.x버전은 보안이 강화되어 기본 보안(X-Pack 보안 기능)이 활성화되어 있기 때문에 HTTPS와 인증을 요구하는 설정이 기본값.
HTTP만 사용하고싶으면 보안기능을 비활성화해야함.
-e "xpack.security.enabled=false"도커를 실행시킬 때 해당 부분을 추가하면 해결된다!
2. 인덱싱 데이터 처리
bulk에 한번에 모아두었다가 저장을 하려고하니 데이터 양이 너무 많아 정상적으로 작동하지않음
1️⃣ bulk를 나누어 저장하는 것이 성능적으로 더 우수. 너무 많은 데이터를 넣으려고할 시 네트워크가 끊기는 경우가 있음.
const keywords = await Keyword.findAll();
const BATCH_SIZE = 1000;
const body = [];
for (let i = 0; i < keywords.length; i++) {
body.push({ index: {_index: 'keywords', _id: keywords[i].id}});
body.push({stock_id: keywords[i].stock_id, keyword: keywords[i].keyword, weight: keywords[i].weight})
if (body.length >= BATCH_SIZE * 2) {
await sendBulkRequest(body);
body.length = 0;
}
}
if (body.length > 0) {
await sendBulkRequest(body)
}3. 한글 형태소 분석기
ElasticSearch는 영어를 기반으로 제작되어 기본 Tokenizer는 한글을 제대로 분석하지 못한다.
이를 해결하기 위해 nori_tokenizer를 통해 토큰화!
settings: {
analysis: {
tokenizer: {
nori_tokenizer: {
type: 'nori'
}
},
filter: {
nori_filter: {
type: 'nori'
}
},
analyzer: {
nori_analyzer: {
type: 'custom',
tokenizer: 'nori_tokenizer',
filter: ['nori_filter']
}
}
}
},