DB- 인덱스
인덱스 테스트 하기 전 준비
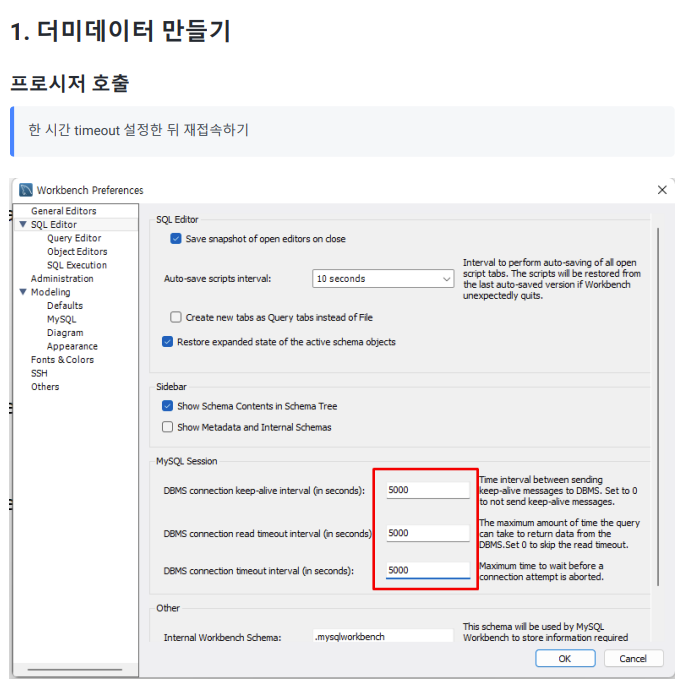
설정 후
drop table if exists member_tb;
create table member_tb(
id int primary key auto_increment,
gender char(1),
nickname varchar(20),
age int,
money int
);
member_tb를 하나 만든다.
혹시라도 생성된게 있을 수도 있으니 만들기 전에
drop 한번 해준다.
DELIMITER
CREATE PROCEDURE insertDummyData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
IF mod(i,2) = 1 THEN
INSERT INTO member_tb(gender, nickname, age, money)
VALUES('M', concat('닉네임', i), FLOOR(1 + RAND() 60),FLOOR(10000 + RAND()
100000));
ELSE
INSERT INTO member_tb(gender, nickname, age, money)
VALUES('F', concat('닉네임', i), FLOOR(1 + RAND() 60),FLOOR(10000 + RAND()
100000));
END IF;
SET i = i + 1;
END WHILE;
END$DELIMITER $
테이블이 잘 생성되었으면 함수를 넣어준다.
전체 선택을 해서 위에 번개 모양을 눌려주면 한번에 다 들어간다.
CALL insertDummyData;
이건 마지막에 따로 번개 누른다.
그럼 더미 데이터가 들어가게 된다.
인덱스 거는 법
CREATE INDEX <인덱스명> ON <테이블명> ( 칼럼명1, 칼럼명2, ... );
CREATE INDEX nickname_idx ON member_tb ( nickname );
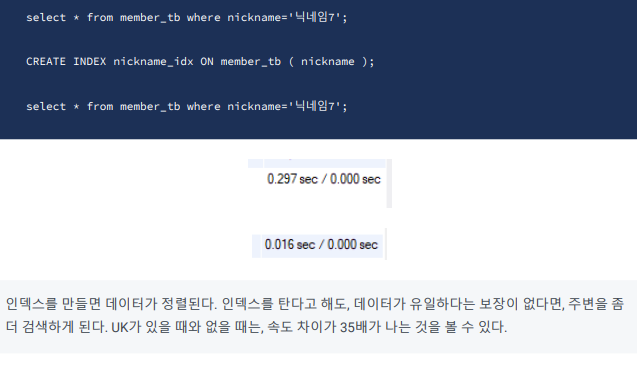
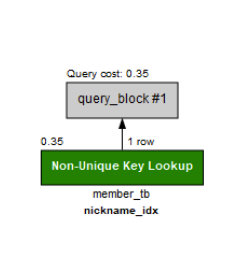
인덱스는 왜 필요한가?
책을 찾아볼때 목차가 있으면 찾는게 쉽듯이
데이터를 찾을때도 목차가 있으면 찾기 쉽다.
인덱스를 하게 되면 비슷한 데이터끼리 모여있게 되어서
스캔을 할때 시간 단축이 된다.
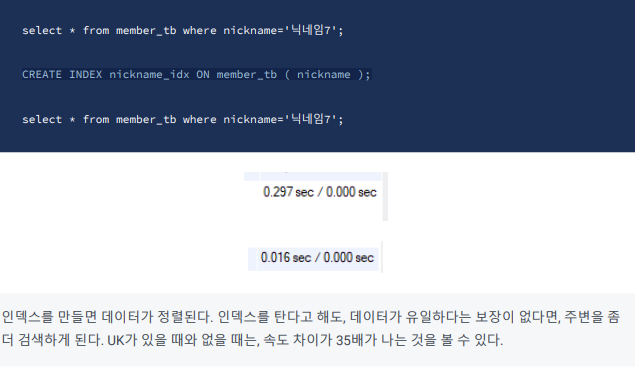
UK
unique key(고유 키)란
고유 키는 테이블의 하나 이상의 열로 구성될 수 있습니다. 열의 조합으로 구성된 고유 키는 여러 열의 조합이 고유해야 함을 의미합니다. 고유 키는 PRIMARY KEY와 유사하지만, PRIMARY KEY는 테이블의 주요 식별자로 사용되며 반드시 고유하고 NULL 값을 가질 수 없습니다. Unique Key는 PRIMARY KEY로 사용할 수 없는 열 또는 열의 조합에 적용됩니다.
UK에는 인덱스 거는게 무조건 유리하다
UK를 걸면 인덱스가 자동으로 생긴다.
UK에 인덱스를 거는게 무조건 유리하다.
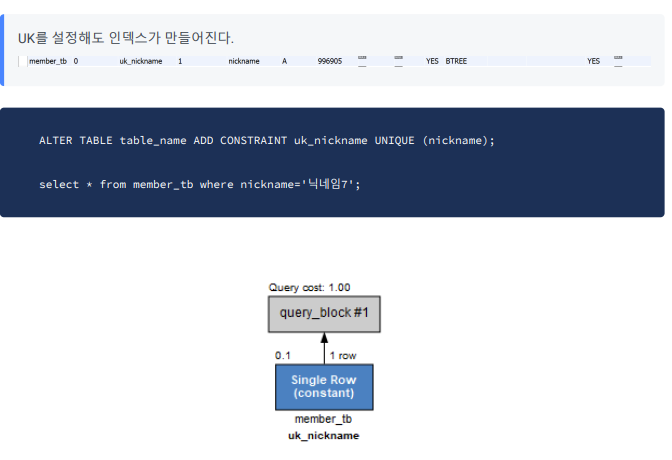
singlerow는 한 행을 스캔하는거라 가장 빠르다.
데이터의 양에 따라
인덱스를 거는것이 무조건 이득은 아니다.
where절에 걸리는 column에 내가 찾는 데이터가 15%이내면 인덱스 하는게 좋다.
그러면 빨라진다.
예를 들어 데이터를 남,여 중 남자만 찾는다고 하면
남자의 데이터 양은 전체의 50%이기 때문에
남자끼리 여자끼리 이렇게 도메인끼리 놔둘수가있다
mysql 체험판에서 이건 지원되지 않는다.
범위 검색도 가능
인덱스를 걸게 되면 데이터의 정렬이 된다.
그래서 범위 검색도 가능하다.

인덱스 전에는 풀스캔을 하겠지만
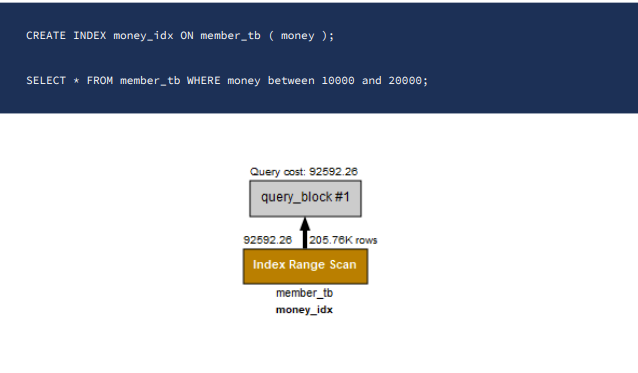
인덱스가 걸리게 되면 데이터 정렬로 인한 인덱스 스캔을 하게 된다.
