컬렉션 프레임워크
- 컬렉션 : 데이터들의 집합 =>
자료구조 - 컬렉션 프레임워크 : 컬렉션을 다루기 위한 메서드들을 정의해둔 것
- 추가, 삭제, 수정, 검색 등의 메서드
✅ 컬렉션 프레임워크는 자주 사용되는 자료구조를 편리하게 사용할 수 있도록, 자료구조 및 관련된 메서드들을 미리 구현해둔 것이다.
장점
- 일관된 API 사용 가능
- 직접 코드를 작성할 필요 없이, 이미 구현된 컬렉션 프레임워크를 사용하면 된다.(시간 save)
- 프로그램 품질 향상 - 제공되는 API들은 이미 검증되었으며, 고도로 최적화되었기 때문에 프로그램의 품질을 향상시킬 것이다.
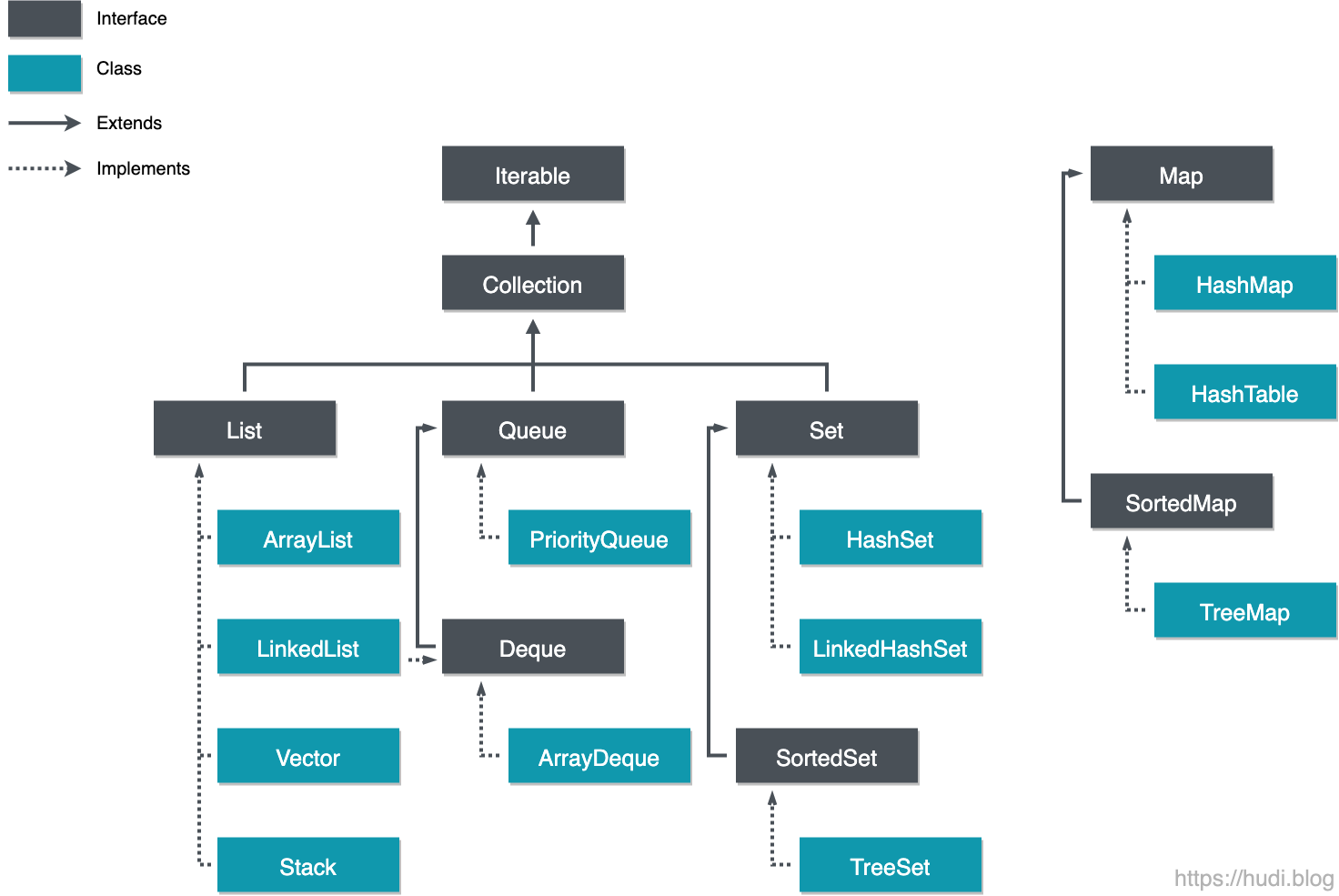
구성요소
1. 인터페이스: 각 컬렉션을 나타내는 추상 데이터에 대한 인터페이스
- List
- Queue
- Set
- Map
2. 클래스: 인터페이스를 구현한 클래스
- 같은 List 컬렉션이라도, 목적에 따라 ArrayList, LinkedList 등으로 구현이 가능하다.
3. 메서드: 자료 구조에 데이터를 추가, 삭제, 수정, 검색하는 메서드를 제공
출처: https://hudi.blog/java-collection-framework-1/
종류
컬렉션 프레임워크는 4가지 인터페이스로 분류할 수 있다.
위 그림처럼 Map은 Collection에 포함되지는 않지만, Collection으로 분류한다.
- List: 데이터의 순서 유지, 중복 허용
- Queue
- Set: 데이터의 순서 유지 X, 중복 허용 X
- Map
- 키와 값의 쌍으로 이루어지는 데이터를 저장
- 키는 중복 허용 X, 값은 중복 O
- 데이터의 순서가 유지 X
List
인덱스가 있다
= 데이터에 순서가 있다.
= 중복이 있어도 인덱스로 식별할 수 있기 때문에 중복이 허용된다.
ArrayList
- ArrayList는 가변적인 배열이다.
- 스택 영역에 생성
- 데이터가 연속적으로 존재한다.(물리적)
효율적인 경우
-
검색(탐색)
- 데이터가 물리적으로 인접해있기 때문에, 원하는 index로 바로 접근할 수 있다.
- 인덱스 n 일때의 주소값 =
배열의 주소+ (n *데이터의 타입 크기)
-
리스트의 시작과 끝에 데이터를 추가하거나 삭제하는 경우
비효율적인 경우
- 중간에 데이터를 추가하거나 삭제할 때
- 추가/삭제 시, 해당 데이터의 뒤에 위치한 값들을 한 칸씩 뒤로 밀거나 당겨야 한다.(shift 연산)
- 빈번한 삭제, 삽입이 일어나는 경우에는 ArrayList보다 LinkedList를 사용하는 것이 좋다.
배열 vs ArrayList
- 공통점 : 객체가 인덱스로 관리된다.
- 차이점 : 배열은 생성될 때 크기가 고정되어 크기를 변경할 수 없지만, ArrayList는 저장 용량을 초과하여 객체들이 추가되면 자동으로 저장용량이 늘어난다.
배열과 ArrayList의 용량이 모두 꽉 차 있는 상태에서 하나의 데이터를 추가하는 상황을 생각해보자.
- 배열은 크기가 고정되어 있기 때문에
(1) (현재 배열의 크기+1) 크기의 새로운 배열을 생성하고,
(2) arraycopy로 기존 배열을 복사해서 새로운 배열에 넣어주고,
(3) 새로운 데이터를 추가해준다.
(1)~(3) 과정을 우리가 직접 해줘야함- 이에 비해 ArrayList는 크기를 자동으로 관리해준다.
(자동으로 관리할 뿐이지 실제 add 메소드 내부에서도 (1)~(3) 과정이 일어남)
LinkedList
- 데이터가 불연속적으로 존재 (물리적)
- 노드의 prev, next가 이전, 이후의 노드의 주소값을 가지고 있다.
효율적인 경우
- 데이터를 추가하거나 삭제할 때
- 추가/삭제할 노드와 그 전후 노드의 prev, next 값만 바꿔주면 된다.
- 배열처럼 데이터를 생성하고 복사할 필요가 없기 때문에 속도가 훨씬 빠르다.
비효율적인 경우
- 검색(탐색)
- 시작부터 link를 타고, 원하는 데이터까지 순차적으로 접근해야 하므로 상대적으로 시간이 오래 걸린다.
✔️ 데이터의 잦은 변경이 예상된다면 LinkedList를, 데이터의 개수가 변하지 않는다면 ArrayList를 사용!
Iterator
- 컬렉션에 저장된 요소들을 순차적으로 읽어오는 역할
- 반복자라고 불림
- Iterator의 컬렉션 순회 기능은 Iterator 인터페이스에 정의되어 있다.
- Collection 인터페이스에 iterator() 메서드가 있고, iterator() 메서드는 Iterator 인터페이스를 구현한 클래스의 인스턴스를 반환한다.
- List와 Set 인터페이스를 구현한 클래스에서 사용 가능하다.
Set
중복 허용 X => 중복 검사가 필요하다!
순서 유지 X
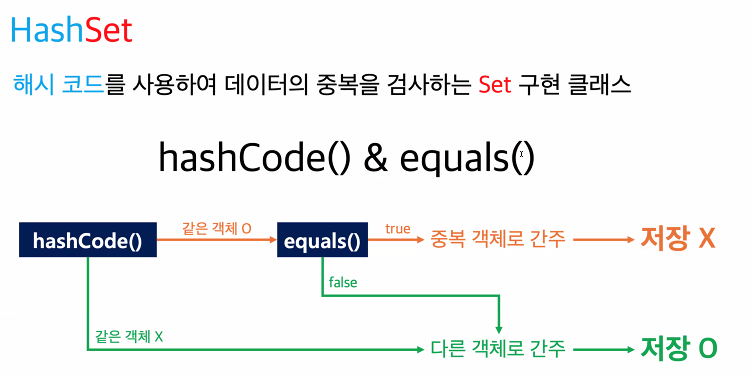
HashSet
- 해시 코드(hashCode)를 사용해서 데이터의 중복을 검사하는 Set 구현 클래스
- hashCode()와 equals()를 사용해서 중복을 검사한다.
- 해시코드: 객체의 주소값을 암호화한 것
TreeSet
- 이진 탐색 트리 형태로 데이터를 저장
- 데이터 중복 저장 X, 순서 유지 X => 대신 순서를 오름차순으로 정렬한다!
❓ 이진 탐색 트리란?
하나의 부모 노드에 두 개의 자식 노드가 연결되어 있는 자료 구조이다.
왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 큰 값을 갖는다.
=> 정렬과 검색에 특화된 자료 구조!
Map
- Key 객체와 Value 객체로 구성된 Entry 객체를 저장하는 자료 구조
- Key: Entry 객체를 식별하는 값, 중복 허용 X(고유값)
- Value: 중복 허용 O
HashMap
- Key 객체를 해싱하여 저장될 메모리 주소를 결정하며, 해당 메모리 주소에 Value 객체를 저장한다.
- 사용자는 그 주소를 알 수 없다.
- 검색에 특화된 자료 구조
- Collection을 구현하지 않기 때문에, iterator()를 직접 호출할 수 없다.
->keySet()이나entrySet()메서드를 사용해서 Set 형태로 변환한 다음에 iterator()를 호출한다.
keySet()/entrySet()/values()
keySet()과entrySet()은 Set 타입을 리턴한다.values()는 Collection 타입을 리턴한다.
Q) hashMap의 key만 가져오는 keySet()은 Key 객체의 값을 Set에 담아준다. 그 이유는 무엇인가?
A) key 객체는 중복을 허용하지 않기 때문에
Q) hashMap의 value만 가져오는 values()는 반환 타입이 Set이 아닌 Collection 타입이다. 그 이유는 무엇인가?
A) value 객체는 중복을 허용하기 때문에 set으로 담지 않는다. 다형성을 위해 Collection 타입으로 반환한다.
[참고]
https://hudi.blog/java-collection-framework-1/
https://catsbi.oopy.io/8f0f5192-3a06-405e-8076-dbc5ff9f2dfb
