메서드
‘어떤 기능을 수행하기 위한 코드들을 묶어놓은 것’
main 메서드
Java 소스 코드 파일을 실행했을 때, 가장 먼저 실행되는 메서드
따라서 반드시 main 메서드가 존재해야 한다!
함수와 메서드의 차이점
이전까지 함수와 메서드는 동일한 개념이라고 생각해왔는데 약간의 차이점이 존재했다.
- 함수 : 특정 기능을 수행하는 코드들을 묶은 것
- 메서드 : 클래스 내에 포함되어 있는 함수
즉 함수가 메서드보다 큰 범위이고, Java에서는 모든 코드를 class 내에 작성하기 때문에 보통 함수보다는 메서드라는 용어를 사용한다.
변수
메모리 저장 과정
메모리는 1 byte(8 bits) 크기의 메모리셀들로 구성되어 있다.
각 메모리셀은 고유 주소를 갖고 있다.
- 필요한 메모리 공간을 파악 ->
타입 - 메모리 공간만큼 확보
- 메모리 공간에 이름을 붙임 ->
변수명 - 메모리 공간에 값을 저장
- 1~3번 과정) 변수를
선언 - 4번 과정) 변수에 값을
할당
Java 네이밍 규칙
파스칼 표기법(PascalCase)과 카멜 표기법(camelCase)를 사용한다.
PascalCase : 모든 단어에서 첫 번째 문자는 대문자이며 나머지는 소문자이다.
ex) HelloWorld
camelCase : 최초에 사용된 단어를 제외한 첫 번째 문자가 대문자이며 나머지는 소문자이다.
ex) helloWorld
- 패키지 : 모두 소문자
- 상수(final) : 모두 대문자, 단어 간 구분은 언더바(_)로
static final int MIN_WIDTH = 4;- 변수 : 소문자 or 카멜
- 변수는 의미를 잘 나타내야 한다.(니모닉)
int a;
float myWidth;- 메소드 : 카멜
- 메소드명은
동사로 시작
- 메소드명은
run();
runFast();
getBackground();- 클래스 : 파스칼
- 클래스명은
명사
- 클래스명은
** 니모닉: 어떤 것을 기억하는 데 쉽게 하도록 도움을 주는 것(회상을 돕는 모든 장치)
상수
재할당이 금지된 변수
final키워드를 사용- 값을 변경할 수 없다.(정확히 말하자면, 주소를 변경할 수 없다.)
-> 원시 타입인 경우는 값을 아예 변경할 수 없다
-> 객체인 경우에는 새로운 객체로 재할당은 불가능하지만, 객체 내 원소를 바꿀 순 있다.
상수를 사용하는 이유
- 프로그램이 실행되면서 값이 변하면 안되는 경우 - 에러 방지
- 코드 가독성을 높이고 싶은 경우
- 코드 유지 관리를 손쉽게 하고자 하는 경우
-> 자주 사용되는 상수가 있다면, 상수를 선언하여 유지 관리에 도움을 줄 수 있다.
타입
기본 타입 vs 참조 타입
- 기본 타입:
실제 값이 저장- 정수 타입(byte, short, int, long), 실수 타입(float, double), 문자 타입(char), 논리 타입(boolean)
- 참조 타입:
주소값이 저장- 객체, 기본 타입을 제외한 나머지 타입
정수 타입
- byte, short, int, long은 차지하는 메모리의 크기가 다르다.
- 과거에는 메모리 용량이 부족했기 때문에, 다양한 메모리 크기가 존재했고 필요에 따라 메모리의 크기를 선택해서 사용했다.
- long 타입에는 리터럴 뒤에
L을 붙여야 한다.

표현 범위
- 1 byte = 8 bit
- 1 bit는 부호를 표현하는데 사용(양수, 음수)
우선 byte형으로 예시를 들어보자.
byte 형은 8 bit이므로 8자리의 이진수로 표현된다.
정수 타입은 양수, 음수를 모두 표현해야 하므로, 1 bit는 부호를 표현한다.
따라서 나머지 7 bit로 숫자를 표현할 수 있고, 양수에는 0이 포함되기 때문에 byte 형의 표현 범위는 -2⁷ ~ (2⁷-1)이 된다.
정수형의 오버플로우, 언더플로우
- 타입의 최대 표현 범위를 넘어서면 오버플로우, 최소 표현 범위를 넘어서면 언더플로우라고 한다.
- 오버/언더플로우가 발생하는 경우에는 표현 범위 내에서 순환한다.
byte 형 변수에 128을 주면, 오버플로우가 발생 -> -128로 이동
byte 형 변수에 -129를 주면, 언더플로우가 발생 -> 127로 이동
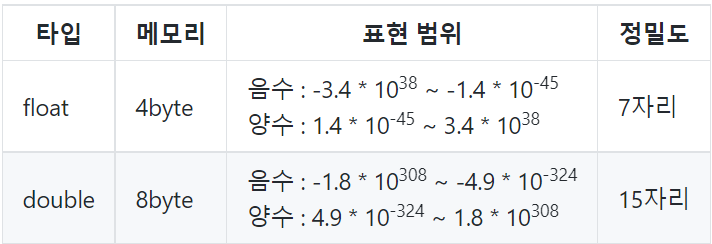
실수 타입
- float, double 형
- float형 리터럴 뒤에
f를 붙여야 한다. - double형 리터럴 뒤에는 붙이지 않아도 된다.
- float형보다 double형이 더 큰 실수를 저장하며, 정확도(정밀도)도 높다.
논리 타입
- boolean 형(true, false)
- 1 bit만으로 표현 가능하지만, JVM의 데이터 최소 단위가 1 byte이기 때문에
1 byte의 크기를 갖는다.
문자 타입
❗ 문자열과 다르다.(큰 따옴표(") 사용)
- char 형
작은 따옴표(')사용- Java는 문자에 유니코드를 저장한다.
타입 변환
자동 타입 변환
- 메모리 크키가 작은 타입 -> 큰 타입
- 덜 정밀한 타입 -> 정밀한 타입
메모리가 작은 변수를 큰 변수에 넣는 것은 어렵지 않아 자동 타입 변환이 이루어 진다.
byte(1) -> short(2)/char(2) -> int(4) -> long(8) -> float(4) -> double(8)
수동 타입 변환(casting)
- 메모리 크키가 큰 타입 -> 작은 타입
메모리가 큰 변수를 작은 변수에 넣을 때는, 메모리를 줄여야 하는 것이므로 casting이 필요하다.
int intValue = 128;
byte byteValue = (byte)intValue;
System.out.println(byteValue); // -128char, int 변환
// char -> int
int result = char - '0';
// int -> char
// 메모리가 큰 타입을 작은 타입으로 바꾸는 것이므로 casting이 필요
char result = (char)(num + '0');문자열(String)
- String은 클래스(Class)이다.
- 클래스는 그 자체로 타입으로 사용될 수 있으며, 연관된 기능들을 묶을 수도 있다.
String 클래스는 문자열 타입으로 사용되며, 문자열과 관련된 유용한 메서드들을 가지고 있다.
String 변수에 문자열을 할당하는 방법은 2가지가 있다.
// 1. 문자열 리터럴을 String 타입의 변수에 할당하는 방법
String name1 = "Kim Coding";
// 2. String 클래스의 인스턴스를 생성하는 방법
String name2 = new String("Kim Coding");이때 String은 참조 타입이므로, name1과 name2에는 문자열이 존재하는 메모리의 주소값이 저장되어 있다.
하지만 name1과 name2를 출력해봤을 때, 주소값이 출력되는 것이 아니라 문자열 값이 출력된다.
이는 String 클래스의 toString() 메서드가 호출되었기 때문이다.
System.out.print(name1); // "Kim Coding"
System.out.print(name2); // "Kim Coding"equals vs ==
equals(): 문자열이 일치하는지 확인==: 저장된 값이 일치하는지 확인
// 동일한 문자열 리터럴이 할당되었으므로, 두 변수는 같은 참조(주소)값을 갖는다.
String name1 = "Kim Coding";
String name2 = "Kim Coding";
// 별개의 인스턴스를 생성하였으므로, 두 변수는 다른 주소값을 저장하고 있다.
String name3 = new String("Kim Coding");
String name4 = new String("Kim Coding");
boolean comparison1 = name1 == "Kim Coding"; // true
boolean comparison2 = name1 == name2; // true
boolean comparison3 = name1 == name3; // false
boolean comparison4 = name3 == name4; // false
boolean comparison5 = name1.equals("Kim Coding"); // true
boolean comparison6 = name1.equals(name3); // true
boolean comparison7 = name3.equals(name4); // trueStringTokenizer, StringBuilder, StringBuffer
StringTokenizer
StringTokenizer 클래스는 문자열을 우리가 지정한 구분자로 쪼개준다.
- 이때 쪼개진 문자열들을 토큰(Token)이라고 한다.
import java.util.StringTokenizer;
public static void main(String[] args){
String str = "This is a string example using StringTokenizer";
StringTokenizer tokenizer = new StringTokenizer(str);
// 현재 남아있는 토큰의 개수를 출력
System.out.println("total tokens:"+tokenizer.countTokens());
while(tokenizer.hasMoreTokens()){ // 하나 이상의 토큰이 남아있다면 true 반환
System.out.println(tokenizer.nextToken()); // 다음 토큰을 반환
}
System.out.println("total tokens:"+tokenizer.countTokens());
}StringBuiler와 StringBuffer를 사용하는 이유
String 객체는 한 번 생성되면 변경할 수 없다.
따라서 String 객체끼리 더하게 되면, 새로운 String 객체를 생성하고 이전 객체는 가비지 컬렉터로 들어간다.
즉 메모리 할당과 해제를 발생시킨다.
문자열을 수정할 때마다 새로운 객체를 생성하게 되니 공간적, 성능적으로 좋지 않다.
StringBuiler, StringBuffer를 사용하면, String 객체를 새로 생성하지 않고 문자열만 수정할 수 있기 때문에 공간적, 성능적으로도 효율적이다.
'+' 연산자를 지양해야 하는 이유 (1)
'+' 연산자를 지양해야 하는 이유 (2)
StringBuffer vs StringBuiler
StringBuffer와 StringBuiler가 제공하는 메서드는 동일하다.
하지만 아래와 같은 차이점이 있다.
- StringBuffer는 멀티 쓰레드 환경에서 사용하기 좋으며 동기화를 지원한다.
- StringBuiler는 단일 쓰레드 환경에서 사용하기 좋다.
