LAZY 설정
- @XXXToOne(@ManyToOne, @OneToOne): default가 즉시 로딩(EAGER)
- @XXXToMany(@OneToMany, @ManyToMany): default가 지연 로딩(LAZY)
블로그를 보다보면, 보통 실무에서는 연관관계는 모두 LAZY로 설정해두라고 하는데 연관관계 되어있는 모든 것들을 LAZY로 바꾸는 것이 맞는가?라는 궁금증이 생겼다.
우선 실무에서 LAZY를 사용하는 이유는 N+1 이슈나 성능 개선, 예상하지 못한 쿼리를 발생할 수 있기 때문이다.
이론상으로는 같이 자주 사용되는 연관관계인 경우에는 EAGER를, 아닌 경우에는 LAZY를 선택하라고 하지만 위와 같은 이슈들을 피하기 위해서 자주 사용되더라도 LAZY를 사용하는 것이 좋다고 한다.
우선 모두 LAZY로 바꿔두고, 상황에 따라 성능에 따라 EAGER로 수정해주는 것이 좋다고 하여 @XXXToOne의 fetchType을 모두 LAZY로 수정했다.
[참고]
https://ict-nroo.tistory.com/132
https://zzang9ha.tistory.com/347
N+1 이슈
@XXXToOne의 fetchType을 모두 LAZY로 수정하고 나서 API를 호출하며 쿼리문을 살펴보는데 N+1 이슈가 발생하는 것을 확인했다.
LAZY로 설정한다고 N+1 이슈가 발생하지 않는 것은 아니였다.
N+1 이슈는 PrfPost와 Urls 사이에 발생한다.
- PrfPost과 Urls은 일대다 연관 관계를 맺고 있다.
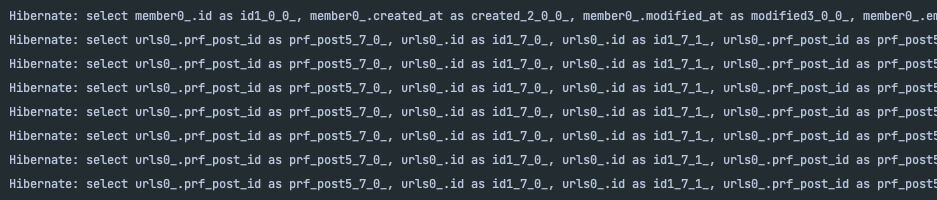
findAll()을 하게 되면, "select * from prfpost"이 호출되기 때문에 Urls에 대한 값을 가져올 수 없다.- Urls 테이블에 대한 값을 가져오기 위해서 아래 그림처럼 "select * from urls where urls.prf_post_id=?"를 여러 번 호출하게 된다.
(?에는 PrfPost의 id값이 들어감) - 따라서 게시글이 100개 존재한다면, prfpost 전체를 가져오는 쿼리문 1개와 해당 게시글의 urls을 가져오는 100개의 쿼리문이 발생할 것이다.(N+1 이슈)
N+1 이슈 해결
join fetch 사용하기
join fetch을 사용해서 N+1 문제를 해결하려고 했다.
join fetch는 N+1 이슈의 근본적인 문제를 해결할 수 있지만 3가지 단점이 있었다.
join fetch의 단점
-
Fetch Type을 개발자가 선택할 수 없음
-> EAGER 타입으로 설정됨(LAZY 불가) -
페이징 쿼리를 사용할 수 없다.
-
join fetch(inner join) 시 발생하는 중복 문제
-> 해당 중복 문제는 해결 가능한 문제이다.(아래에서 정리해두었다)
🚨 join fetch 시 발생하는 중복 문제
1개의 게시글과 그 게시글에 3개의 url이 존재한다고 가정해보자.(일대다 관계)
아래의 예시는 쉽게 설명하기 위해서 column을 간소화한 것이다.
select * from prfpost;| id | title | content |
|---|---|---|
| 1 | 제목1 | 내용1 |
select * from urls;| id | url | prfpost_id |
|---|---|---|
| 1 | url1 | 1 |
| 2 | url2 | 1 |
| 3 | url3 | 1 |
✔️ 일(prfpost)의 기준으로 fetch(inner) join이 발생하는 경우
select * from prfpost inner join urls on prfpost.id = urls.prfpost_id;| prfpost.id | prfpost.title | prfpost.content | urls.id | urls.url | urls.prfpost_id |
|---|---|---|---|---|---|
| 1 | 제목1 | 내용1 | 1 | url1 | 1 |
| 1 | 제목1 | 내용1 | 2 | url2 | 1 |
| 1 | 제목1 | 내용1 | 3 | url3 | 1 |
일(prfpost)의 기준으로 inner join을 하면, 오히려 하나였던 행이 3개로 늘어났고 중복이 발생한다.
게시글이 10개, Url이 각각 100개가 있다면 행은 1000개가 될 것이다.(카테시안 곱)
❗️ 엔티티의 데이터 수 != join한 데이터의 수
(데이터 수가 달라지게 되어 페이징이 불가능해진다. 자세한 건 아래에서 설명할 것)
✔️ 다(url)의 기준으로 fetch(inner) join이 발생하는 경우
select * from urls inner join prfpost on prfpost.id = urls.prfpost_id;| urls.id | urls.url | urls.prfpost_id | prfpost.id | prfpost.title | prfpost.content |
|---|---|---|---|---|---|
| 1 | url1 | 1 | 1 | 제목1 | 내용1 |
| 2 | url2 | 1 | 1 | 제목1 | 내용1 |
| 3 | url3 | 1 | 1 | 제목1 | 내용1 |
❗️ 엔티티의 데이터 수 == join한 데이터의 수
테스트
@Query(value = "SELECT p FROM PrfPost p JOIN FETCH p.urls")
List<PrfPost> findListFetchJoin();- 이 경우는
일(prfpost)을 기준으로 fetch join한 것 - prfPost 2개와 urls 3개를 입력하고 호출
=> 중복 발생 - 위의 표와 다르게, 완전히 동일한 urls id값들을 가지고 있는 이유는 PrfPost의
List<Urls> urls이기 때문이다.
[
{
"id": 1,
"urls": [
{ "id": 1 },
{ "id": 2 },
{ "id": 3 },
],
},
{
"id": 1,
"urls": [
{ "id": 1 },
{ "id": 2 },
{ "id": 3 }
],
},
{
"id": 1,
"urls": [
{ "id": 1 },
{ "id": 2 },
{ "id": 3 }
],
},
{
"id": 2,
"urls": [
{ "id": 4 },
{ "id": 5 },
{ "id": 6 }
],
},
{
"id": 2,
"urls": [
{ "id": 4 },
{ "id": 5 },
{ "id": 6 }
],
},
{
"id": 2,
"urls": [
{ "id": 4 },
{ "id": 5 },
{ "id": 6 }
],
},
]
즉, 중복 문제를 해결하기 위해서 DISTINCT 키워드를 추가하거나 리턴 타입을 SET으로 설정해야 한다.
@Query(value = "SELECT DISTINCT p FROM PrfPost p JOIN FETCH p.urls")
List<PrfPost> findDistinctFetchJoin();
@Query(value = "SELECT p FROM PrfPost p JOIN FETCH p.urls")
Set<PrfPost> findSetFetchJoin();[
{
"id": 1,
"urls": [
{ "id": 1 },
{ "id": 2 },
{ "id": 3 },
],
},
{
"id": 2,
"urls": [
{ "id": 4 },
{ "id": 5 },
{ "id": 6 }
]
]
🚨 fetch join과 페이징 쿼리는 같이 사용할 수 없음
- 페이징 처리가 모든 경우에 불가능한 것은 아니다!
❗️ 인프런에 있는 답변 (김영한 님)
@XXXToOne애너테이션을 통해 형성된 관계인 경우 테이블 조인에 따라 데이터 수가 변경되지 않으므로 페이징 처리가 잘됩니다.@XXXToMany애너테이션을 통해 형성된 관계인 경우 테이블 조인에 따라 데이터가 변경되어 페이징 처리와 페치 조인이 동시에 불가능합니다.
즉, 다(url)의 기준으로 fetch join이 발생하는 경우는 페이징이 가능하지만 일(prfpost) 기준은 페이징이 불가능하다는 것이다!
@Query(value = "SELECT DISTINCT p FROM PrfPost p JOIN FETCH p.urls")
Page<PrfPost> findDistinctFetchJoin(Pageable pageable);- fetch join 쿼리에 Pageable 인자를 주어 페이징 처리를 하면, 쿼리에 들어가야할
limit키워드가 들어가지 않는다.
-> 모든 데이터를 가져오게 되는 것! - 그럼 데이터들을 가져와서 그 다음에 페이징하는 것은 어떨까?라고 생각했는데 그렇게 되면 OOM 문제가 발생할 수 있다.
- 조회된 결과가 10만건이면 10만건을 그대로 메모리에 가져오게 되므로 OOM(Out Of Memory) 문제를 유발할 수 있다.
- 10만건의 데이터를 메모리에 가져와서 페이징 처리하는 것은 말도 안되는 것!
❓ fetch join 대신에 inner join을 사용하면?
inner join과 페이징은 같이 사용 가능하다!
하지만 N+1 이슈를 해결하기 위해서는 고려해야할 사항들이 있다.
1. inner join을 사용했기 때문에 중복 처리가 필요하다.
2. N+1 문제를 해결하기 위해서 결국 Batch Size를 설정해야 한다.
JPA Fetch join과 Paging(limit) 처리 시 발생하는 문제 및 해결
JPA Fetch join과 페이징(paging) 처리
@EntityGraph 사용하기
- EAGER 타입만 가능하다.
- Fetch join과는 다르게 join 문이 outer join으로 실행된다.
=> Inner join과 Outer join의 차이점 - Fetch join과 마찬가지로 중복에 주의해야 한다!
- Fetch join과 마찬가지로
@XXXToOne만 페이징 적용 가능하다. (@XXXToMany은 불가)
@NamedEntityGraphs 사용하기
https://www.baeldung.com/spring-data-jpa-named-entity-graphs
FetchMode.SUBSELECT
https://stackoverflow.com/questions/32984799/fetchmode-join-vs-subselect
- 페이징 쿼리가 적용 가능한지 확인해봐야한다!
Batch Size
Batch Size는 N+1 이슈를 해결하진 못하지만 성능을 개선해줄 수 있는 방법이다.
yml에 batchsize를 작성해주거나, @BatchSize 어노테이션을 사용해서 설정할 수 있다.
application.yml
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000- N+1을 완전히 해결해주진 않지만, 성능을 향상시킬 순 있다.
- 페이징 쿼리 적용 가능(
@XXXToOne,@XXXToMany에 상관없이)
N+1 이슈 결론
처음에는 N+1 이슈를 근본적으로 해결할 수 있는 fetch join을 사용하려고 했다.
하지만 @OneToMany 애너테이션으로 형성된 관계에서 fetch join과 페이징을 동시에 할 수 없고, 현재 구현 중인 서비스에서는 페이지네이션이 꼭 필요했기 때문에 fetch join 말고 다른 방법을 찾아보기로 하였다.
(잠깐 fetch join으로 데이터를 모두 받아와 페이징해볼까하고 생각했었는데 어리석은 생각임을 깨닫고 바로 접었다.)
여러 블로그들을 보면서 어떤 방법이 효율적일지 고민하다가 지금 내가 개발하고 있는 서비스에서는 Batch Size를 사용하는 것이 베스트일 것이라는 생각이 들었다.
서비스는 페이징을 통해 항상 10개씩 게시글을 가져오고 있기 때문에 BatchSize = 10로 설정해두면 N+1 이슈를 쿼리를 2번 호출하는 것으로 해결할 수 있다.
[참고]
N+1 이슈
N+1 이슈
N+1 이슈
N+1 이슈
N+1 이슈
fetch join과 inner join의 차이점
JPA에서 Fetch Join과 Pagination을 함께 사용할때 주의하자
