현재 구현 상태
항상 페이지네이션을 적용하는 키워드 검색(제목/태그), 카테고리 검색 기능을 구현했다.
- 카테고리, 키워드 검색 X -> 페이징된 전체 리스트 가져오기
- 카테고리 O, 키워드 X/O -> findByCategoryAndKeyword()
(키워드가 입력되지 않으면 빈 문자열로 처리하기 때문에 키워드 검색은 일어나지 않음) - 카테고리 X, 키워드 O -> findByTagsContainingOrTitleContaining()
// 전체 리스트 가져오기
Page<PrfPost> findAll(Pageable pageable);
// 키워드 검색 (태그/제목)
Page<PrfPost> findByTagsContainingOrTitleContaining(Pageable pageable, String keyword1, String keyword2);
// 카테고리 + 키워드 검색
@Query("select p from PrfPost p where p.category=:category and (p.tags like %:keyword% or p.title like %:keyword%)")
Page<PrfPost> findByCategoryAndKeyword(Pageable pageable, String category, String keyword);- 게시글(PrfPost) Entity은 INDEX가 설정되지 않았다.
- 따라서 모든 검색이 풀 테이블 스캔이 될 것이다.
- 지금은 데이터를 적게 넣어서 문제가 없지만, 데이터가 점점 많아질수록 성능이 떨어질 것이다.
💡 INDEX를 설정해서 성능을 높여보자!
더미데이터
인텔리제이 설정
현재는 H2를 사용하고 있었는데 더미데이터를 넣기 전에 MySQL로 변경해주었다.
JPA ddl-auto 시, 더미데이터 생성 방법
H2의 종류
더미데이터 생성하는 방법
더미데이터를 생성하는 방법은 찾아보니까 여러 방법이 있다.
- Mysql 프로시저
- 직접 for문을 통해서 쿼리 생성
- 더미데이터를 생성해주는 프로그램/라이브러리 사용
Mysql 프로시저와 mockaroo를 사용해서 더미데이터를 넣기로 결정했다.
mockaroo에서 무료는 최대 1000건까지 생성할 수 있기 때문에 약간의 노가다는 필요하나 여러 데이터 타입이 있어 email이나 전화번호 이런 format을 굳이 내가 설정할 필요가 없었고 랜덤으로 값을 잘 넣어주기 때문에 사용하기에 유의미한 값들을 넣어주기에 좋다고 생각했다.
나와 비슷한 선택을 한 블로그도 보았다.
더미데이터 설계
구현해놓은 검색이나 카테고리 기능도 테스트해봐야 하기 때문에 더미데이터의 값도 어느정도는 설계하고 가야겠다고 생각했다.
prf_post
- category, tags, title -> 검색에서 사용되는 column
- id, like_count -> 검색, 정렬에서 사용되는 column
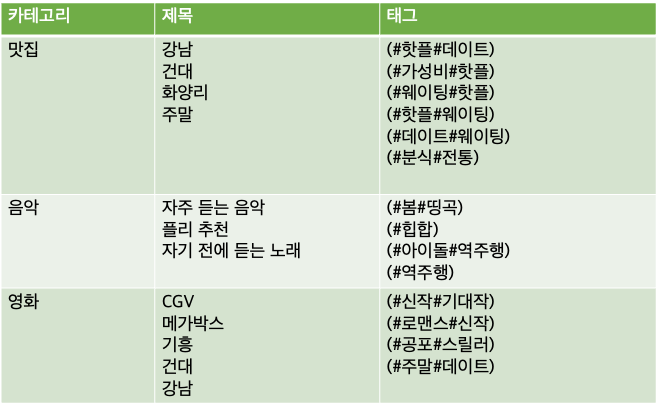
따라서 category, tags, title, like_count에 의미있는 값을 주어야 한다.
like_count은 0과 10 사이의 랜덤한 정수값으로 category, tags, title은 다음과 같은 키워드들이 들어가도록 더미데이터를 설계했다.
3만건들은 검색과 정렬 기능을 테스트할 수 있도록 유의미한 데이터를, 나머지 700만건은 dummy data를 넣어줄 것이다.
더미데이터 넣기
✔️ member 프로시저
DELIMITER $$
DROP PROCEDURE IF EXISTS memberInsert$$
CREATE PROCEDURE memberInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
insert into member (CREATED_AT, MODIFIED_AT, email, member_status, nick_name, password) values (now(), now(), concat('userid@',i,'naver.com'), 'ACTIVE', concat('nickname',i), 'password');
SET i = i + 1;
END WHILE;
END$$
DELIMITER $$
CALL memberInsert; $$✔️ prf_post 프로시저
DELIMITER $$
DROP PROCEDURE IF EXISTS loopInsert$$
CREATE PROCEDURE loopInsert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
insert into prf_post (CREATED_AT, MODIFIED_AT, CATEGORY, CONTENT, like_count, TAGS, TITLE , MEMBER_ID) values (now(), now(), '맛집', '내용', 0, '#검색#인덱스#잘되나', '맛집 게시글입니다.', 2);
insert into prf_post (CREATED_AT, MODIFIED_AT, CATEGORY, CONTENT, like_count, TAGS, TITLE , MEMBER_ID) values (now(), now(), '영화', '내용', 0, '#검색#인덱스#잘되나', '영화 게시글', 2);
insert into prf_post (CREATED_AT, MODIFIED_AT, CATEGORY, CONTENT, like_count, TAGS, TITLE , MEMBER_ID) values (now(), now(), '음악', '내용', 0, '#검색#인덱스#잘되나', '음악 게시글', 2);
SET i = i + 1;
END WHILE;
END$$
DELIMITER $$
CALL loopInsert; $$- 주의)
DELIMITER $$에서 DELIMITER과 $$ 사이에 공백이 필요하다!
성능 테스트
- 가져오는 row는 1000으로 고정
- 데이터는 9149012개 (914만)
select * from prf_post order by id DESC;
// 0.0023 sec
select * from prf_post order by like_count DESC, id DESC;
// 11.439 sec- 인기순 정렬을 하면 11초라는 어마무시한 시간이 걸렸다.
- 인기순 정렬 시에 검색 성능을 높이려면 어떻게 해야할까?
인덱스
hibernate, mysql 등은 기본적으로 기본키를 활용한 인덱스 테이블을 자동으로 만든다.
인덱스를 적용할 곳은 정렬과 검색이다.
인덱스를 설정해둔다고 해서 무조건 인덱스를 다 타는 것이 아니다. 오히려 안 타는 경우가 많다!
- 인덱스를 타는지 안 타는지 확인하는 법
- explain을 붙여 select문을 작성했을 때 출력값을 확인
- type 칼럼이 ALL인 경우에는 index를 타지 않은 것
- key 칼럼에는 사용한 index를 나타내줌
- NULL이면 인덱스를 타지 않은 것
- key 칼럼에 값이 있어야 index를 탄 것
정렬
https://jmkim.tistory.com/66
https://weicomes.tistory.com/191
https://jojoldu.tistory.com/481
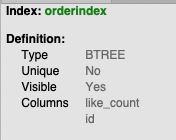
- 최신순 정렬 : id가 index로 설정되어 있기 때문에 index를 탄다.
- 인기순 정렬 : (like_count, id) index를 생성했다.
- ORDER BY에서 작성하는 칼럼 순서와 index의 컬럼 순서가 동일해야한다고 해서 위와 같이 설정했다.
- 인덱스를 (like_count, id)로 설정했으나 ORDER BY 말고 WHERE에 조건 대상이 없기 때문에 index를 타지 않는다. (index는 검색인데 정렬만 한다면 index를 탈 필요가 없을 것 같음)
검색
- 검색에 사용되는 tag, title, category는 인덱스로 설정할 수 있다.
like와 인덱스
- like는 % 위치에 따라 INDEX를 탈 수도 있고 안 탈수도 있다. (참고)
- abc%: 인덱스 탐
- %abc: 인덱스 안 탐
- %abc%: 인덱스 안 탐
테스트
- 태그(tags)에 인덱스를 설정
#검색#인덱스#잘되나라는 태그가 9120000개 있다.#성수#화양라는 태그는 6개 있다.
1. select * from prf_post where tags like "#검색%";
-> 인덱스를 타지 않는다!
원래 마지막에 %를 붙이면 인덱스를 타야하는데, 인덱스는 결과값이 1/3 미만일 경우에만 인덱스를 타기 때문에 인덱스를 타지 않는 것이다.
2. select count(*) from prf_post where tags like "%#검색%";
-> 인덱스를 안 탄다.
3. select * from prf_post where tags like "#성수%";
-> 인덱스를 탄다.
[참고]
https://jojoldu.tistory.com/476
https://choicode.tistory.com/27
https://k3068.tistory.com/106
https://jojoldu.tistory.com/243
https://jaehoney.tistory.com/98#:~:text=%EC%9D%B8%EB%8D%B1%EC%8A%A4%EB%A5%BC%20%ED%83%80%EB%8A%94%20%EC%A7%80%20%ED%99%95%EC%9D%B8,explain%EC%9D%84%20%EB%B6%99%EC%97%AC%EC%A3%BC%EB%A9%B4%20%EB%90%A9%EB%8B%88%EB%8B%A4.
https://velog.io/@ljinsk3/JPA%EB%A1%9C-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0
https://wrkbr.tistory.com/559
https://zorba91.tistory.com/292
http://www.gurubee.net/article/58340
