코드의 효율성을 따질 때 우리는 시간 복잡도와 공간 복잡도를 생각한다.
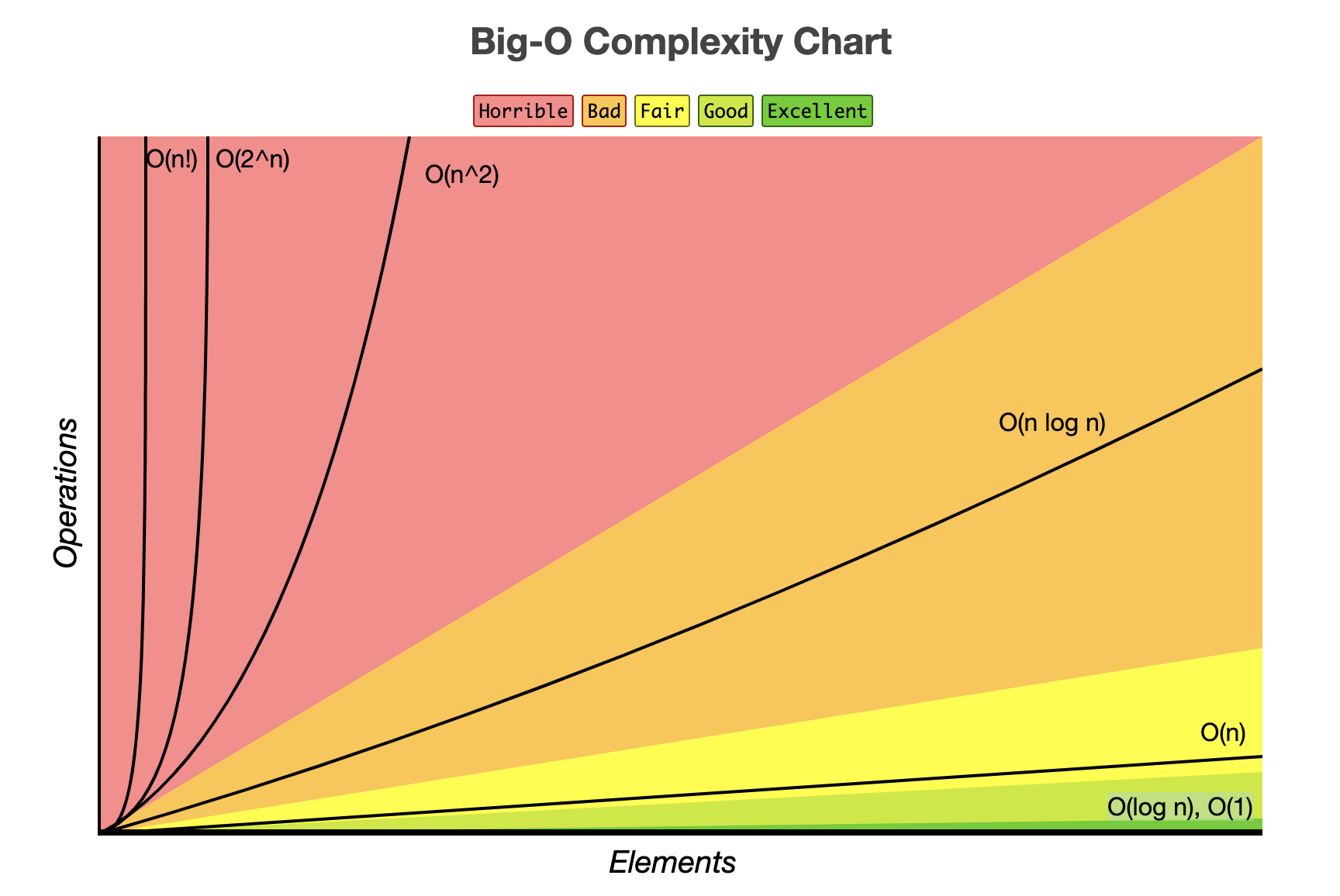
시간복잡도
입력값과 연산 수행 시간의 상관관계를 나타낸 것
입력값이 커짐에 따라, 연산 수행 시간이 얼마나 증가하는지?
시간 복잡도를 표기하는 방식에는 3가지가 있는데, 그 중 Big-O 표기법을 가장 많이 사용한다.
Big-O
최악인 경우의, 시간 복잡도(코드를 실행하는데 얼마나 걸리는지)
- 빅-오 표기법은 계수와 낮은 차수의 항은 제외한다.
- 빠른 순서대로
O(1)>O(log n)>O(√n)>O(n)>O(n log n)>O(n²)>O(2ⁿ)>O(n!)
O(1)
- constant complexity(상수)
- 입력값이 증가해도, 시간은 늘어나지 않음
- 즉시 출력값을 얻어낼 수 있다.
ex) 배열에서 특정 index에 접근해서 요소 가져오기
O(n)
-
linear complexity(선형)
-
입력값이 증가함에 따라, 같은 비율로 시간도 증가
-
입력값이 1일 때 1초가 걸렸다면, 입력값이 100배 증가하면 시간도 100배가 늘어난 100초가 걸린다.
-
시간이 2배, 3배로 늘어나는 O(2n), O(3n)도 모두 O(n)으로 작성한다.
ex) 단일 for문/while문
O(log n)
-
logarithmic complexity
-
log base가 2가 될 수도 10이 될 수도 있다. -> 모두
O(log n)으로 표기
(log base는 보통2이다.)
참고 -
BST나 이진 탐색처럼, 한 번 실행할 때마다 경우의 수가 반 씩 줄어들면 복잡도가 O(log n)이다.
ex) BST, 이진 탐색
BST의 트리가 2ⁿ개 일 때, n번 탐색을 하면 원하는 값을 찾을 수 있다.
(log 2(2ⁿ) = n)
왜 log n의 시간복잡도인가?
[예시]
- 아래의 코드는 시간 복잡도가
O(log k n)이다. 보통 log base를 생략하고O(log n)라고 작성한다.
for(int i=0; i<n ;i++){
i*=k;
}- i가 k 배씩 커지면, 시간 복잡도는 O(log k n)이 된다.
O(n²)
- quadratic complexity
- 입력값이 증가함에 따라, 시간이 n의 제곱수의 비율로 증가
- O(n³), O(n⁴)도 모두 O(n²)으로 작성한다.
ex) 중첩된 for문/while문
O(2ⁿ)
- exponential complexity
ex) 피보나치 수열
public int fibonacci(int n) {
if(n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci (n - 2);
}코딩 테스트
코딩 테스트에는 시간 제한이 있다.
따라서 문제에 주어진 데이터의 크기에 따라, 시간복잡도를 어림잡아 어떤 알고리즘을 사용해야할지 예측하는 것도 중요하다!
- 입력 데이터의 크기가 큰 경우: 시간 복잡도가 작은 알고리즘을 사용해야함
- 입력 데이터의 크기가 작은 경우: 시간 복잡도가 커도 상관없지만 문제를 푸는 것에 집중해야 한다.
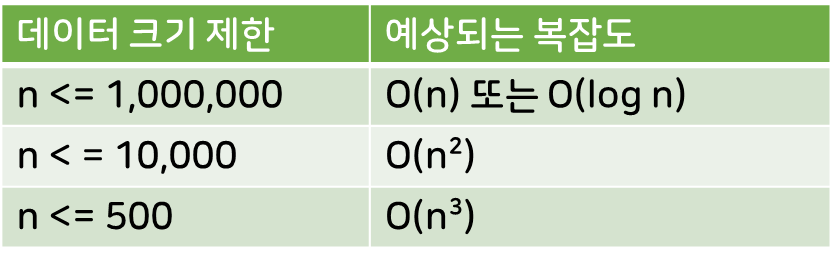
데이터가 1,000,000 정도의 크기를 갖는다면, 중첩 반복문을 사용하는 것은 아예 배제하고 다른 방법을 생각해봐야 한다.
정렬 알고리즘의 시간복잡도
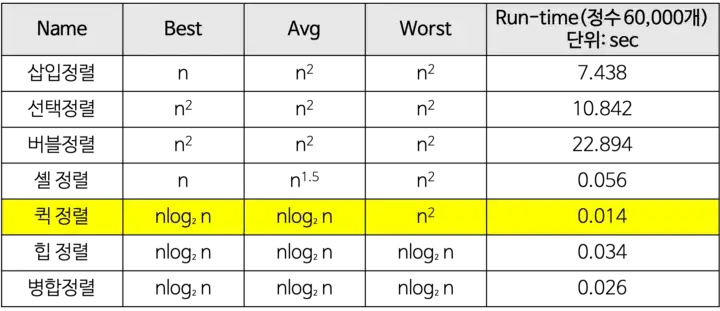
[출처] : https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
