1. 구글 스프레드 시트란?
MS의 엑셀처럼 스프레드 시트의 한종류이다. 구글 드라이브에서 구동되며, javascript 기반으로 제작 되어 스크립트 사용으로 작업 자동화 등 강력한 기능을 만들어 사용이 가능하다.
2. 웹 스크래핑 함수 사용법
웹에서 간단한 내용을 긁어 오려면 대표적으로 IMPORTXML 함수를 사용할 수 있다.
- IMPORTXML
XML 등 여러 구조화된 데이터로부터 원하는 데이터를 추출해내는 함수이다.
사용법은=IMPORTXML(url, xpath)이다.
✔ 네이버 스포츠 뉴스 첫 페이지의 기사 타이틀을 예시로 한번 함수를 사용해보겠다.
xpath는 원하는 element를 오른쪽 클릭하여 복사할 수 있다.
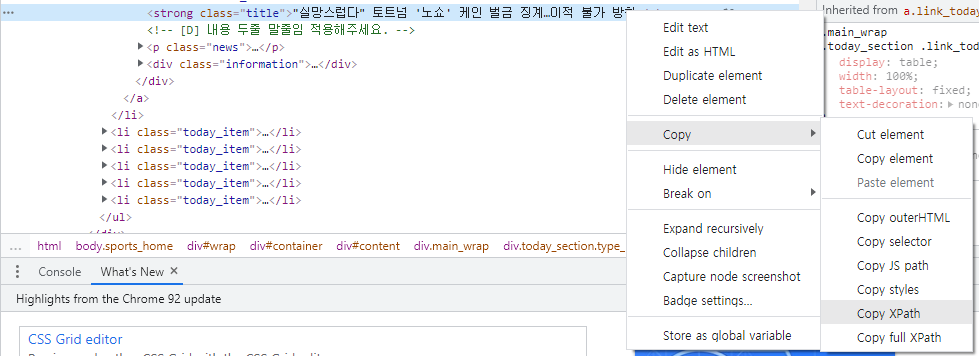
저렇게 그대로 복사해와서 IMPORTXML을 사용한다면 아래처럼 수식 오류가 발생할 것이다.
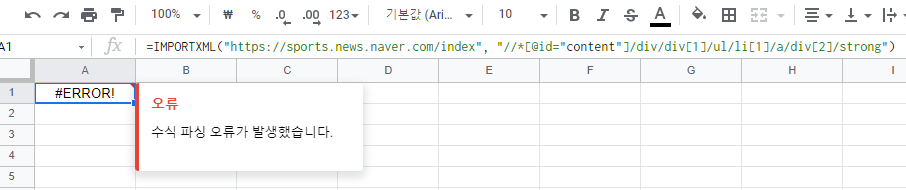
그 이유는 xpath부분이 ""로 감싸지고, 그 내부의 content도 ""로 감싸지기 때문이다. 다들 알다시피 간단하게 content를 ''로 감싸면 해결된다.

🛑 기사 타이틀 여러개를 가져오려면 IMPORTXML 여러개를 쓰면 되겠지만, 이 방법에는 문제가 있다.
- ❌ IMPORTXML에는 시간 당 호출 제한이있다. 따라서 가져올 데이터가 많아진다면 어느순간 작동이 멈출 것이다.
- ❌ IMPORTXML의 실행속도 자체가 아주 빠르지는 않다. 여러개 로딩 시 다소 느린면이 있다.
✅ 그래서 IMPORTXML 함수 호출 한 번에 여러개의 데이터를 불러오면 해결이 된다!
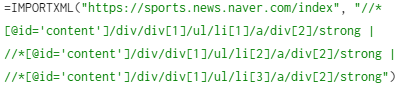
- ✔ 각 xpath를 | 를 사용하여 한번에 작성하면 된다!
총 3개의 기사 타이틀을 한번에 가져오는 예시이다.

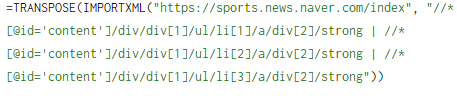
🤔 세로말고 가로로 데이터를 받고 싶은데 어떻게 하죠?
- 😀 TRANSPOSE 함수를 이용하면 됩니다!

3. 마무리
구글 시트에서 간단하지만 유용하게 쓸 수 있는 IMPORTXML 함수의 사용방법에 대해서 알아봤다. 하지만 몇몇 제약으로 인해 사용이 어려울 때도 있다. 다음에는 더욱 강력한 기능인 apps script의 사용법에 대해서 알아보겠다.

여러가지를 시도하는 학생입니다
https://bcres.paragonrels.com/publink/default.aspx?GUID=0c710365-6ed3-4d0d-83a9-31b9dc6e4db7&Report=Yes
위 사이트에서 각 값들을 좀 가져오고 싶은데 (예를들면, bedroom 개수나 bathroom 개수)
어떻게 해야할까요? 저는 아래처럼 사용했는데... 안되더라구요..
=index(IMPORTXML("https://bcres.paragonrels.com/publink/default.aspx?GUID=0c710365-6ed3-4d0d-83a9-31b9dc6e4db7&Report=Yes","//*[@id="divHtmlReport"]/div/div[177]"),1,1)