내용 정리
Chapter 1
컴퓨터 구조 지식은 크게 '컴퓨터가 이해하는 정보'와 '컴퓨터의 4가지 핵심 부품'으로 나뉨
컴퓨터가 이해하는 정보
: 데이터와 명령어
컴퓨터는 0과 1로 표현된 정보만 이해하는데, 이러한 정보의 종류는 데이터와 명령어 두가지가 있다
- 데이터: 정적인 정보
- 컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상
- 명령어를 위해 존재하는 일종의 재료
- 명령어: 데이터를 움직이고 컴퓨터를 작동시키는 정보
- 명령어 없이 데이터는 정보 덩어리일 뿐
- 명령어는 컴퓨터를 작동시키는 정보
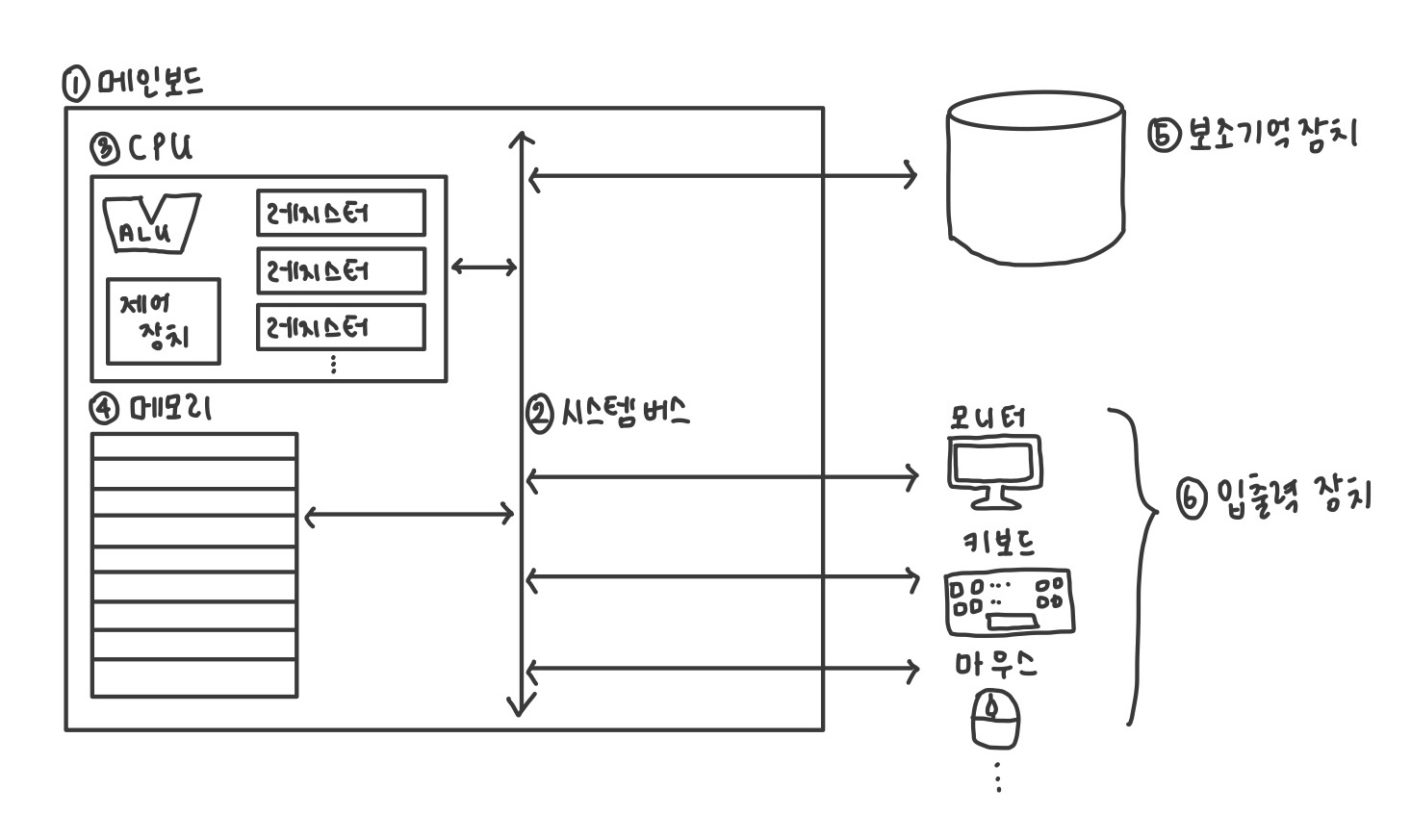
컴퓨터의 4가지 핵심 부품
: 중앙처리 장치 (CPU), 주기억장치 (메모리), 보조기억장치, 입출력장치
메모리
현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품
- 프로그램이 실행되려면 반드시 메모리에 저장되어 있어야 함
- 컴퓨터가 빠르게 작동하기 위해 메모리 속 명령어와 데이터의 위치가 정돈되어 있어야 함 : 메모리에 저장된 값에 빠르고 효율적으로 접근할 수 있도록 주소 사용
- 주소란 메모리에 저장된 값의 위치
CPU
컴퓨터의 두뇌- 메모리에 저장된 명령어를 읽어 들이고, 읽어 들인 명령어를 해석하고 실행하는 부품
CPU의 내부 구성 요소 중 중요한 3가지
1. 산술논리연산장치 (Arithmetic Logic Unit/ALU): 계산을 위해 존재하는 부품
2. 레지스터: CPU 내부의 작은 임시 저장 장치. 프로그램을 실행하는데 필요한 값들을 임시로 저장. CPU 내 여러개 존재
3. 제어 장치 (Control Unit/CU): 전기 신호(컴퓨터 부품들을 관리하고 작동시키기 위함)를 내보내고 명령어를 해석하는 장치
- 메모리 읽기: CPU가 메모리에 저장된 값을 읽고 싶을때 제어장치를 통해 메모리를 향해 보내는 제어 신호
- 메모리 쓰기: CPU가 메모리에 어떤 값을 저장하고 싶을때 제어장치를 통해 메모리를 향해 보내는 제어 신호
보조기억장치
메모리보다 크기가 크고 전원이 꺼져도 저장된 내용을 잃지 않는 메모리를 보조하는 저장 장치
예시: 하드 디스크, SSD, USB 메모리, DVD, CD-ROM
- 현재 '실행되는' 프로그램을 저장하는 메모리와 다르게 '보관할' 프로그램을 저장하는 보조기억장치
입출력장치
컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치
예시: 마이크, 스피커, 프린터, 마우스, 키보드
보조기억장치와 입출력장치의 차이점은?
- 둘 다 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치
- 컴퓨터 주변에 붙어있는 장치라서 주변장치라고 부르기도 함
- 다만, 보조기억장치는 일반 입출력장치에 비해 메모리를 보조하는 특별 기능을 수행하는 입출력장치임
메인보드와 시스템 버스
위 모든 핵심 부품은 메인보드라는 판에 연결
- 메인보드 = 마더보드
- 메인보드에는 위 부품들을 비롯한 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자가 있다
- 메인보드에 연결된 부품들은 메인보드 내부에 버스하는 통로를 통해 서로 정보를 주고 받음
- 여러 버스 가운데 컴퓨터의 4가지 핵심 부품을 연결하는 가장 중요한 버스: 시스템 버스
시스템 버스의 구성
1. 주소 버스: 주소를 주고 받는 통로
2. 데어터 버스: 명령어와 데이터를 주고받는 통로
3. 제어 버스: 제어 신호를 주고받는 통호
Chapter 2
정보 단위
0과 1을 나타내는 가장 작은 정보 단위인 비트 (bit)
- n개 비트는 (2^{n})가지 상태를 표현할 수 있음
8개의 비트를 묶은 바이트 (byte)
- 2^8개의 정보 표현 가능
1000개의 바이트를 묶은 킬로바이트 (kB)
1000개의 킬로바이트를 묶은 메가 바이트 (MG)
1000개의 메가바이트를 묶은 기가 바이트 (GB)
1000개의 기가바이트를 묶은 테라 바이트 (TB)
CPU가 한번에 처리할 수 있는 데이터의 크기를 나타내는 워드 (word)
- CPU가 한번에 16bit를 처리할 수 있다면 1워드 = 16bit, 한번에 32bit를 처리할 수 있다면 1워드 = 32bit
- 이렇게 정의된 워드의 절반 크기는 하프워드
- 1배 크기는 풀 워드
- 2배 크기는 더블 워드
이진법
: 수학에서 0과 1만으로 모든 숫자를 표현하는 방법 (binary)
- 이진수를 표현할때
- 이진수의 끝에 아래 첨자 붙인다 (수학적 표기)
- 이진수 앞에 '0b'를 붙인다 (코드 작성 시)
이진수의 음수 표현
가장 널리 사용되는 방식인 2의 보수
- 사전적 정의: 어떤 수를 그보다 큰 2^n에서 뺀 값
- 컴퓨터 내부에서 양수인지 음수인지 구별하기 위해 사용하는 부가 정보 플래그
- 2의 보수 한계: n비트로 -2^n과 2^n을 동시에 표현할 수 없음
십육진법
수가 15를 넘어가는 시점에서 자리 올림을 하는 숫자 표현 방식
- 숫자가 너무 길어지는 이진법의 단점을 보완
- 0 1 2 3 4 5 6 7 8 9 A B C D E F 10 11 ...
십육진수를 이진수로 변환
- 십육진수를 이루고 있는 각 글자를 따로따로, 4개의 숫자로 구성된 이진수로 변환
- 변환한 수를 그대로 이어붙인다
이진수를 십육진수로 변환
- 이진수 숫자 네 개씩 끊는다
- 끊어준 네 개의 숫자를 하나의 십육진수로 변환한다
- 변환한 십육진수를 그대로 이어붙인다
문자 집합과 인코딩
- 문자 집합 (Character Set): 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
- 문자 인코딩 (Character Encoding): 문자 집합에 속한 문자를 0과 1로 변환하는 과정
- 문자 디코딩 (Character Decoding): 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
아스키 코드
ACSII: American Standard Code for Information Interchange
- 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자 포함
- 아스키 문자는 각각 7비트로 표현
- 총 128개(2^7) 문자 표현 가능
- 장점: 간단하게 인코딩된다
- 단점: 한글뿐만 아니라 아스키 문자 집합 외의 문자와 특수문자를 표현할 수 없다
- 더 많은 문자 표현을 위해 1비트 추가한 8비트의 확장 아스키 등장
- 그러나 표현 가능한 문자는 256개라서 여전히 부족
EUC-KR
한글 인코딩의 두가지 방식
1. 완성형 인코딩: 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식
2. 조합형 인코딩: 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것들의 조합으로 글자 코드를 완성하는 인코딩 방식
- EUC-KR는 대표적인 완성형 인코딩 방식
- 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드 부여
- 한글 한글자를 표현하려면 16비트 필요
- 총 2350개의 한글 단어 표현 가능
- 모든 한글 조합을 표현할 수는 없다
- 글자 깨짐 유발
- 해결을 위해 마이크로소프트의 CP949 등장
- EUC-KR의 확장 버전이지만 이마저도 한글 전체를 표현할 수 없다
유니코드와 UTF-8
유니코드: EUC-KR보다 훨씬 다양한 한글을 포함하며 대부분 나라의 문자, 특수문자, 화살표나 이모티콘까지도 코드로 표현할 수 있는 통일된 문자 집합
- 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합
- 글자에 부여된 값을 그대로 인코딩 값으로 삼은 아스키 코드나 EUC-KR과 달리 유니코드에서는 이 값을 다양한 방법으로 인코딩함
- 인코딩 방식에는 크게 UTF-8, UTF-16, UTF-32가 있다
UTF-8: 1바이트부터 4바이트까지의 인코딩 결과를 만들어 낸다
- 따라서 인코딩한 값의 결과는 1바이트/2바이트/3바이트/4바이트가 될 수도 있다
- UTF-8로 인코딩한 결과가 몇 바이트가 될지는 유니코드 문자에 부여된 값의 범위에 따라 결정 됨
- 유니코드 문자에 부여된 값의 범위가 0부터 007F(16)까지는 1바이트로 표현
- 유니코드 문자에 부여된 값의 범위가 0080(16)부터 07FF(16)까지는 2바이트로 표현
- 유니코드 문자에 부여된 값의 범위가 0800(16)부터 FFFF(16)까지는 3바이트로 표현
- 유니코드 문자에 부여된 값의 범위가 10000(16)부터 10FFFF(16)까지는 4바이트로 표현
Chapter 3
고급 언어와 저급 언어
사람을 위한 고급 언어
- 예시로 C, C++, Java, Python과 같은 프로그래밍 언어
컴퓨터가 직접 이해하고 실행할 수 있는 저급 언어
- 명령어로 이루어져 있다
- 고급 언어로 작성된 소스 코드가 실행되려면 저급 언어, 즉 명령어로 변환되어야 한다
저급 언어의 2가지 종류
1. 기계어: 0과 1의 명령어 비트로 이루어진 언어
- 이진수로 나열 시 너무 길어지기 때문에 가독성을 위해 십육진수로 표현하기도 함
- 어셈블리어: 0과 1로 표현된 명령어인 기계어를 읽기 편한 형태로 번역한 언어
- 한 줄 한 줄이 명령어임
- 임베디드 개발자, 게임 개발자, 정보 보안 분야 등의 개발자는 어셈블리어 꽤 사용
컴파일 언어와 인터프리터 언어
고급 언어가 저급 언어로 변환되는 2가지 방식
1. 컴파일 방식
2. 인터프리트 방식
연산 코드와 오퍼랜드
주소 지정 방식
혼공학습단 미션
기본 미션
1. p51 확인 문제 3번
프로그램이 실행되려면 반드시 메모리에 저장되어 있어야 합니다
2. p65 확인 문제 3번
1101(2)를 음수로 표현한 값은 0011(2)입니다
선택 미션
p100의 스택과 큐의 개념 정리하기
스택
한쪽 끝이 막혀 있는 통과 같은 저장 공간
- 막혀 있지 않은 쪽으로 데이터를 차곡차곡 저장
- 저장한 자료를 빼낼 떄는 마지막으로 저장한 데이터부터 빼냄
- 후입선출: 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식
- LIFO (Last In First Out)
- 명령어
- PUSH: 스택에 새로운 데이터를 저장
- POP: 스택에 저장된 데이터를 꺼내는 명령어
큐
양쪽이 뚫려 있는 통과 같은 저장공간
- 한쪽으로는 데이터를 저장
- 다른 한쪽으로는 먼저 저장한 순서대로 데이터를 빼냄
- 선입선출: 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식
- FIFO (First In First Out)
