
📌 그래프의 정의
그래프 : 선형 자료구조나 트리 자료구조로 표현하기 어려운 다:다의 관계를 가지는 원소들을 표현하기 위한 자료구조
그래프 G는 객체를 나타내는 정점과 객체를 연결하는 간선의 집합 → G = (V, E)
차수 : 정점에 연결된 간선의 수
그래프의 제한 사항
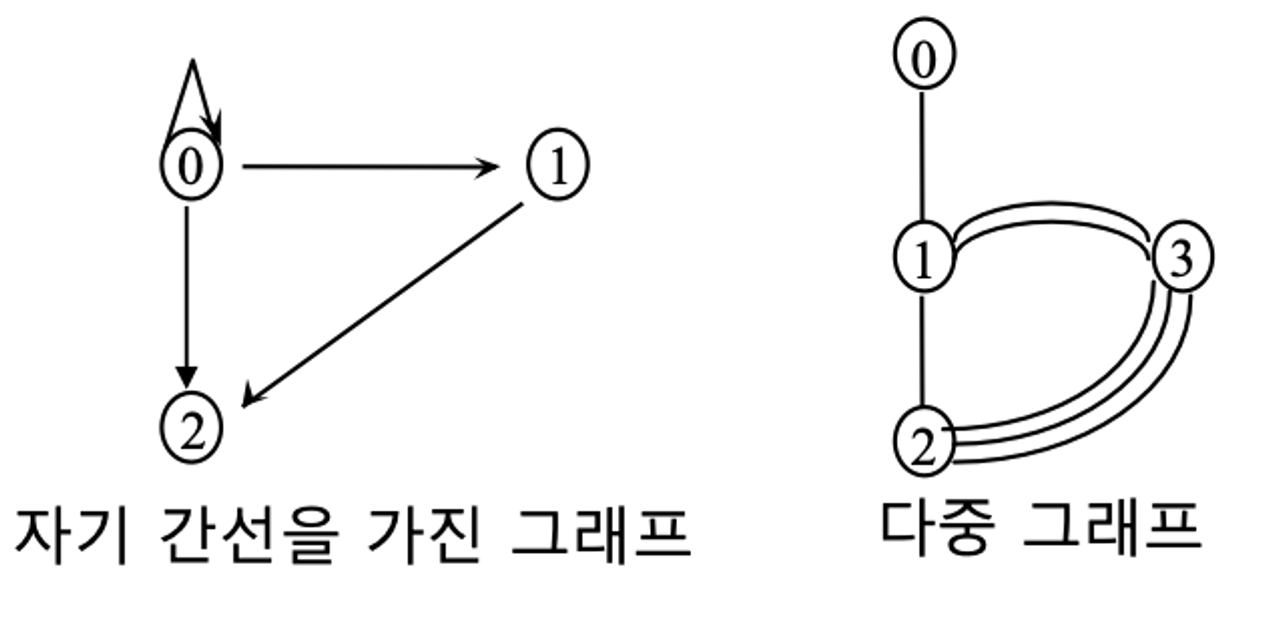
- 자기 간선 또는 자기 루프 없음
- 다중그래프(서로 다른 두 정점 사이에 2개 이상의 간선 가짐)는 이 제한 없음
📌 그래프의 종류
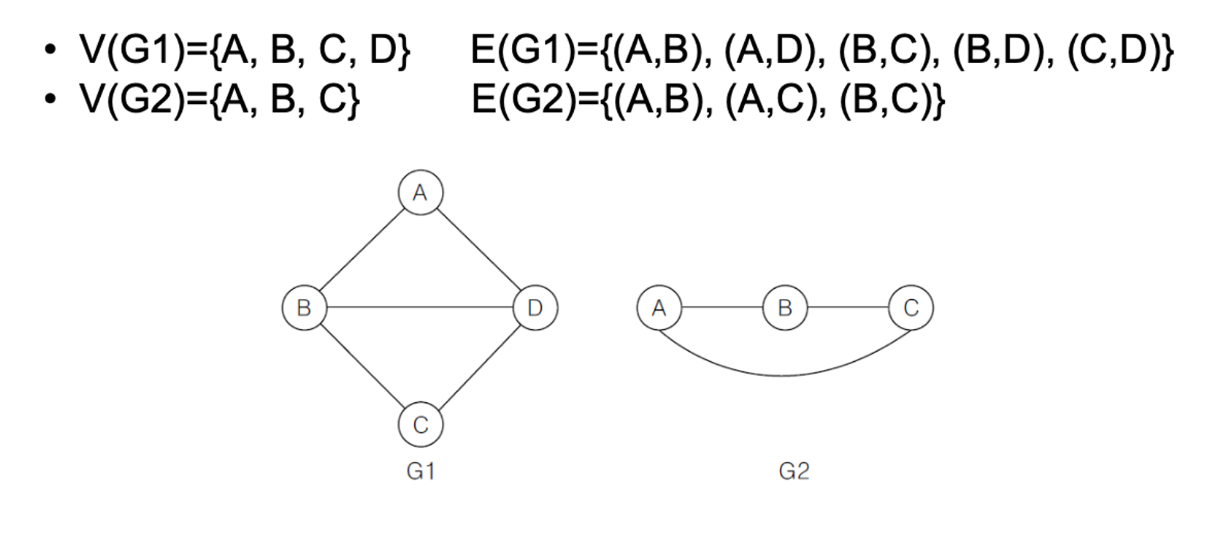
무방향 그래프
두 정점을 연결하는 간선의 방향이 없는 그래프
정점 와 를 연결하는 간선을 로 표현
(A, B)와 (B, A)는 같은 간선을 의미함 → 간선을 나타내는 정점의 쌍에 순서 없음
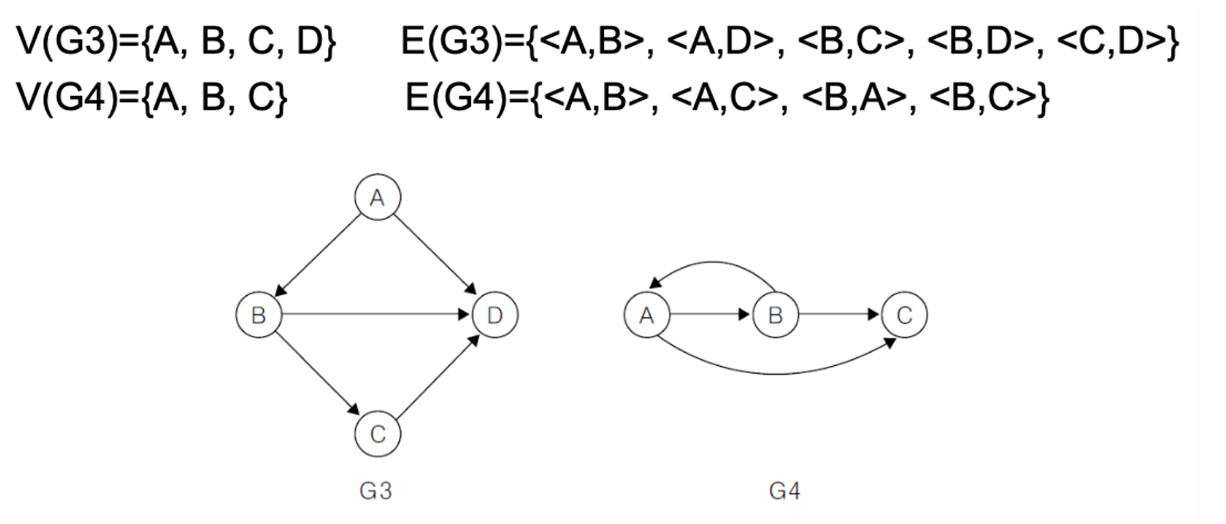
방향 그래프
간선이 방향을 가지고 있는 그래프
→ 를 로 표현 → 를 꼬리, 를 머리 라고함
<A, B>와 <B, A>는 서로 다른 간선을 의미
아래는 방향 / 무방향 그래프의 예제
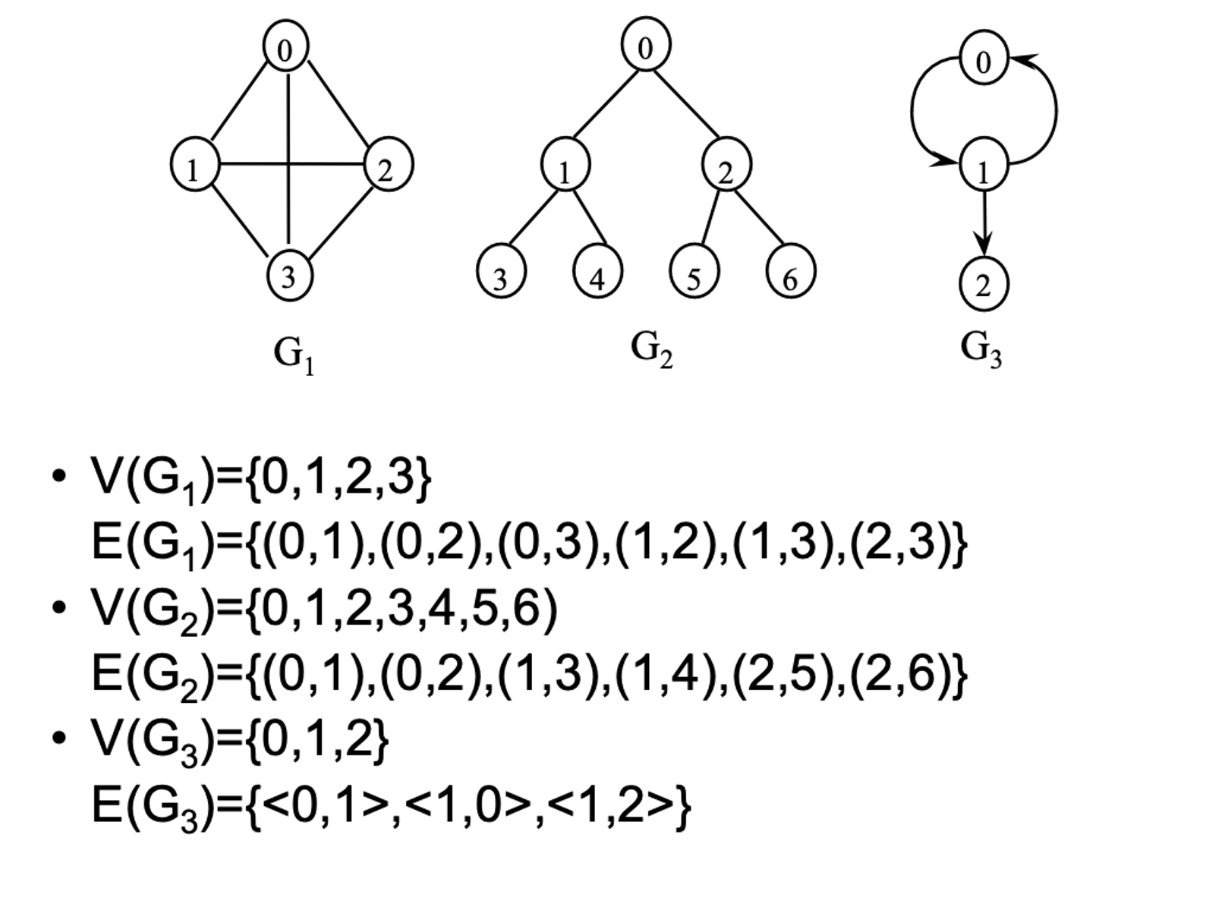
완전 그래프
각 정점에서 다른 모든 정점을 연결하여 가능한 최대의 간선 수를 가진 그래프
정점 n개 무방향 그래프 : n(n-1) / 2개
정점 n개 방향 그래프 : n(n-1)개
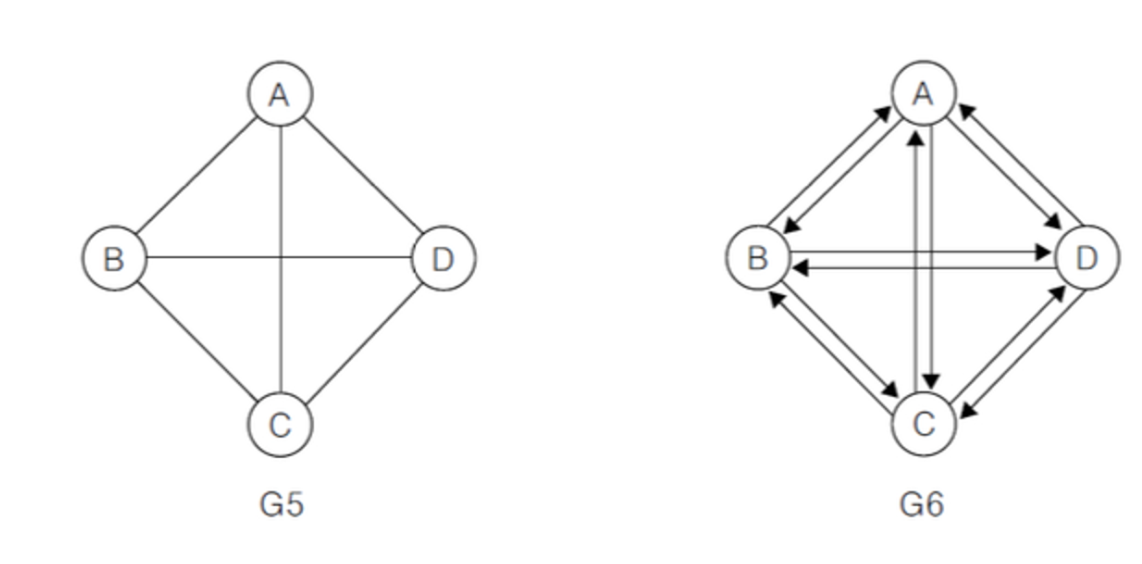
G5는 무방향 그래프이고 정점 개수 4개 → 4 * 3 / 2 = 6
G6는 방향 그래프이고 정점 개수 4개 → 4 * 3 = 12
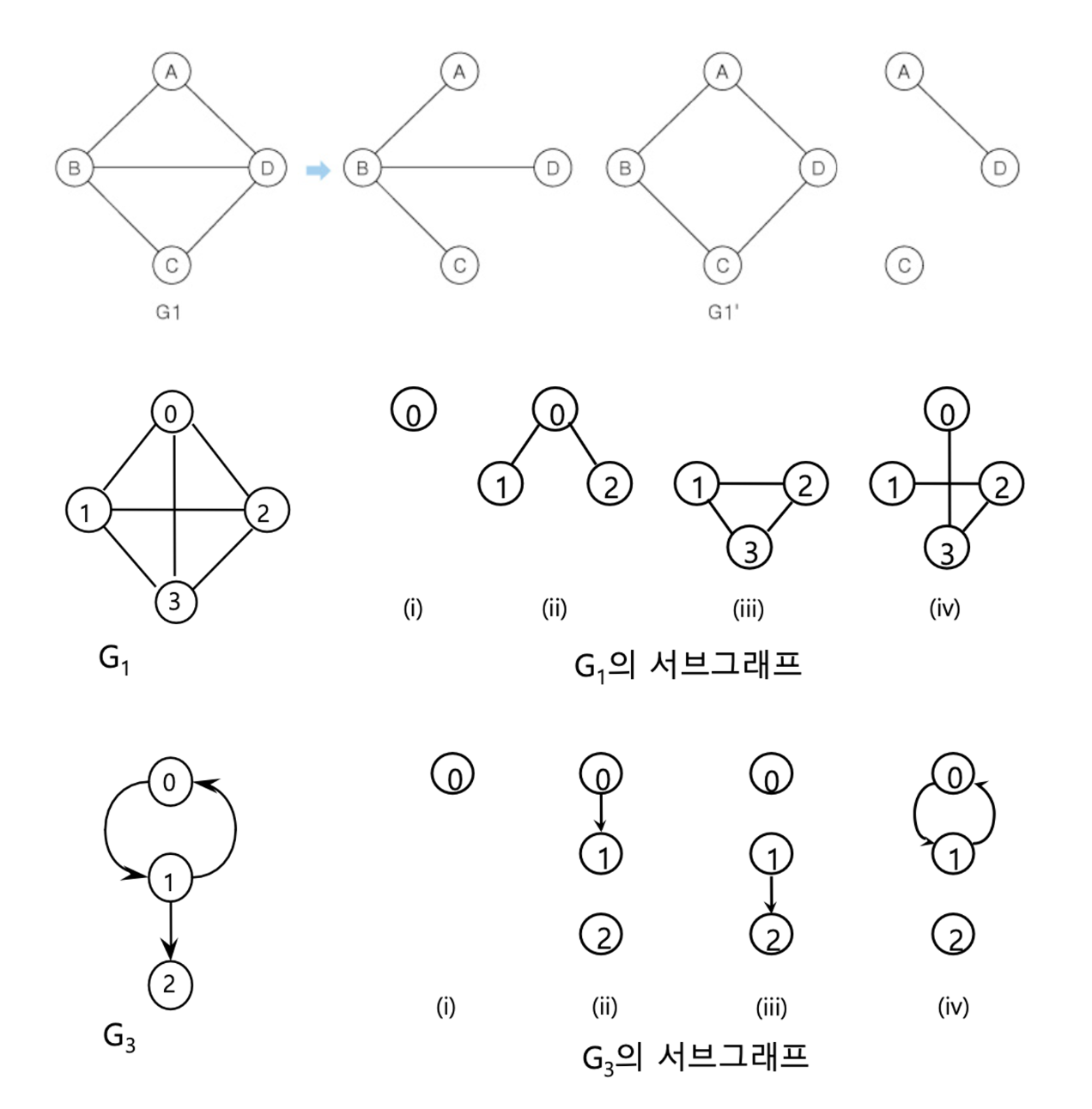
부분 그래프
원래의 그래프에서 일부의 정점이나 간선을 제외하여 만든 그래프
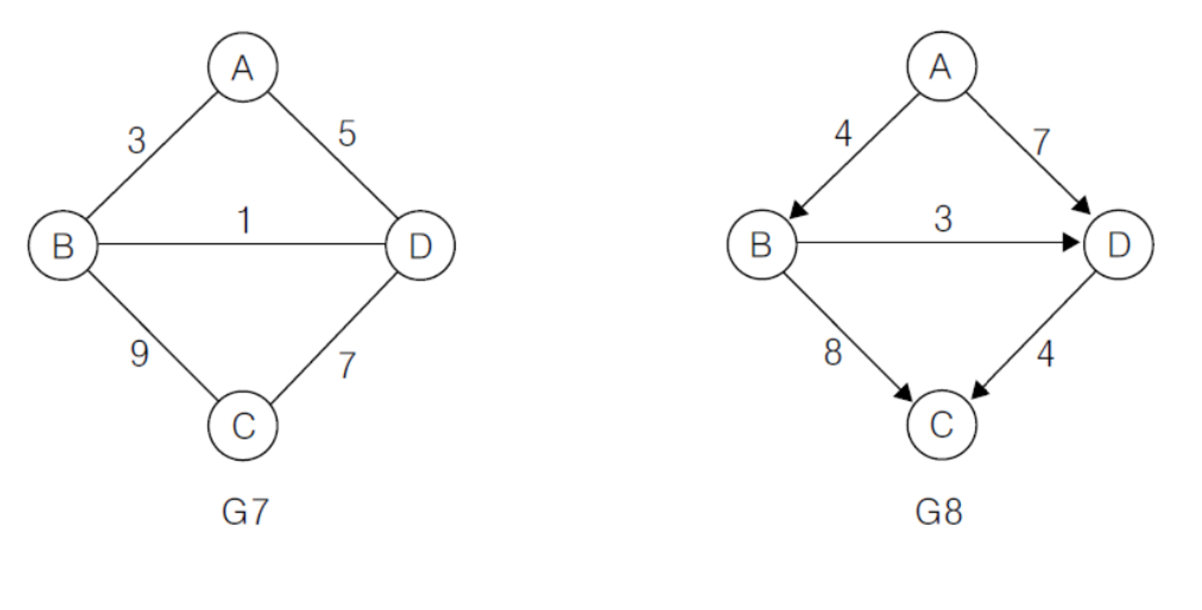
가중 그래프
정점을 연결하는 간선에 가중치를 할당한 그래프
📌 그래프 관련 용어
간선가 있을 때,
두 정점 를 인접되어 있다
간선은 정점들에 부속되어있다
ex) 위의 G7그래프에서 정점A와 인접한 정점은 B와 D이고, 정점 A에 부속되어 있는 간선은 (A, B), (A, D)이다
차수 : 정점에 부속되어 있는 간선의 수
ex) G7에서 A의 차수는 2, G8에서 B의 차수는 3
방향 그래프의 정점의 차수 = 진입차수(정점을 머리로하는 간선의 수) + 진출차수(정점을 꼬리로 하는 간선의 수)
G8에서 정점 B의 진입차수는 1, 진출차수는 2
경로 : 정점 로부터 정점 까지 갈 수 있는 길을 순서대로 나열한 것
경로의 길이 : 경로 상에 있는 간선의 수
단순 경로 : 경로 상에서 처음과 마지막을 제외한 모든 정점들이 서로 다른 경로
사이클 : 처음과 마지막 정점이 같은 단순 경로
DAG(Directed Acyclic Graph) : 방향그래프이면서 사이클이 없는 그래프
연결 그래프 : 서로 다른 모든 쌍의 정점들 사이에 경로가 있는 그래프 → 즉, 떨어져 있는 정점이 없는 그래프
+) 트리는 사이클이 없는 연결 그래프
📌 그래프 표현법
-
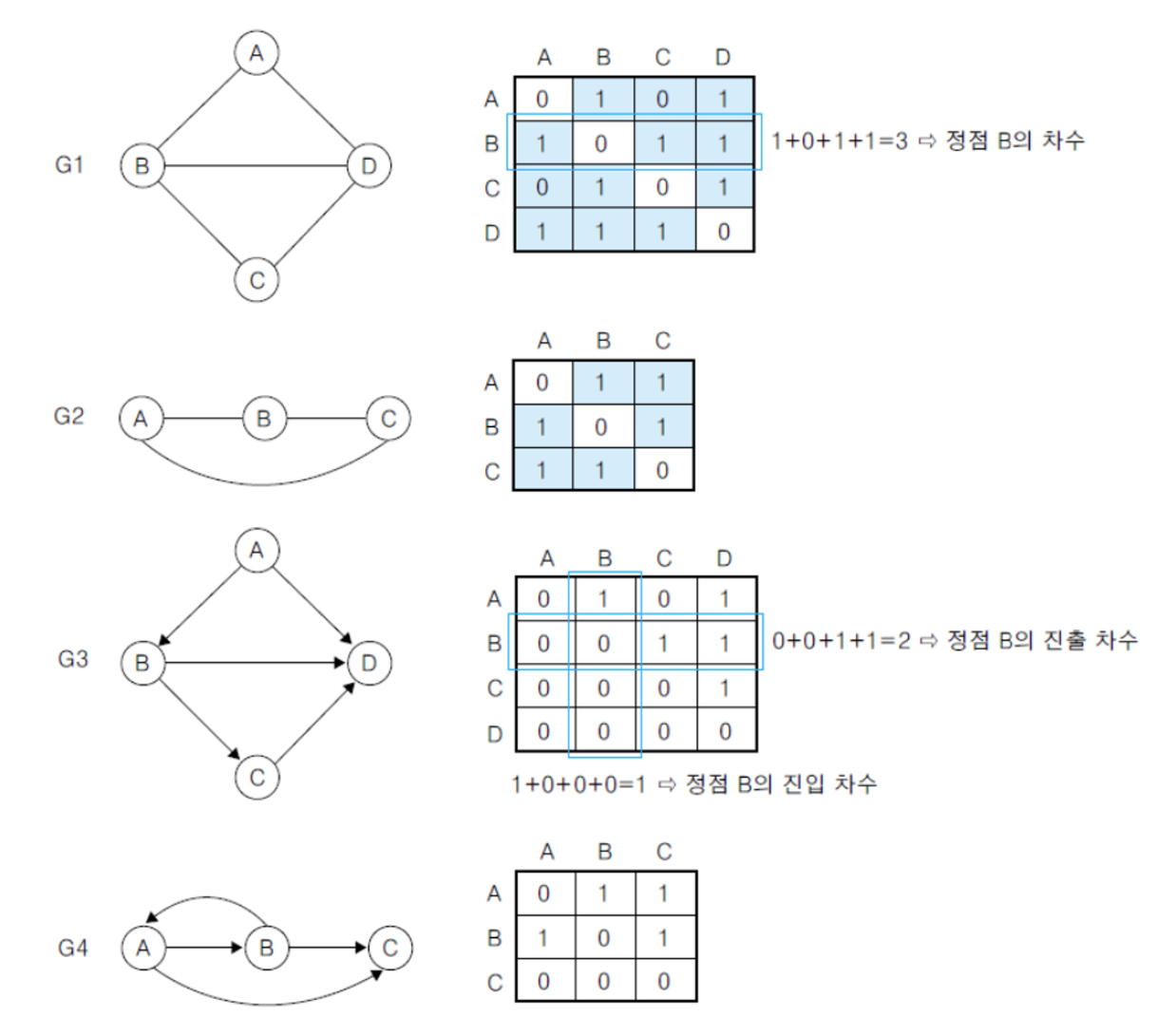
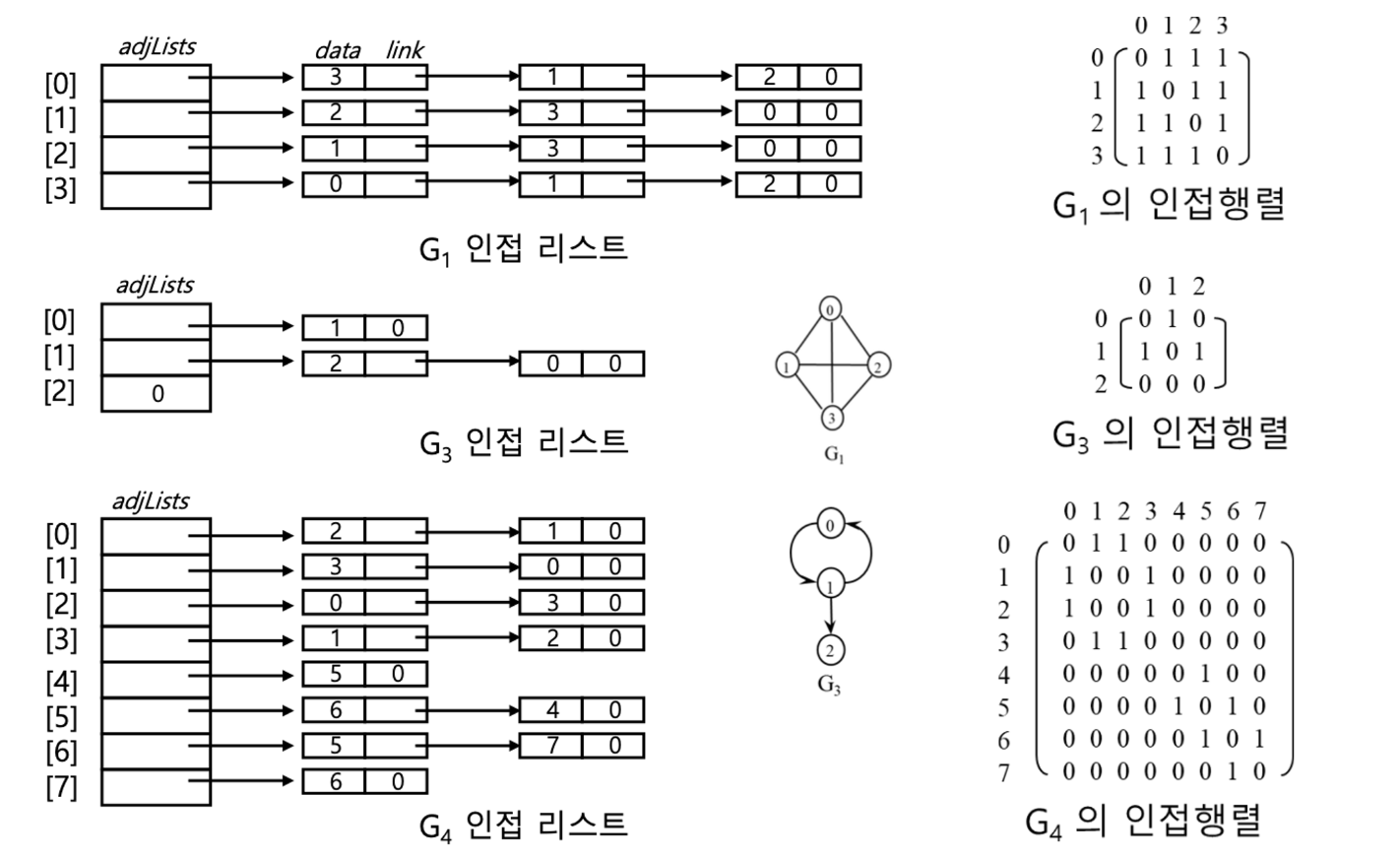
인접 행렬
무방향 그래프 : 어떤 정점의 차수는 그 행또는 열의 합
방향 그래프 : 행의 합은 진출차수, 열의 합은 진입차수
n개 정점을 가지는 그래프는 항상 n*n개의 메모리 사용
정점의 개수에 비해 간선의 개수가 적은 희소그래프에 대한 인접행렬은 희소행렬이 되므로 메모리 낭비
-
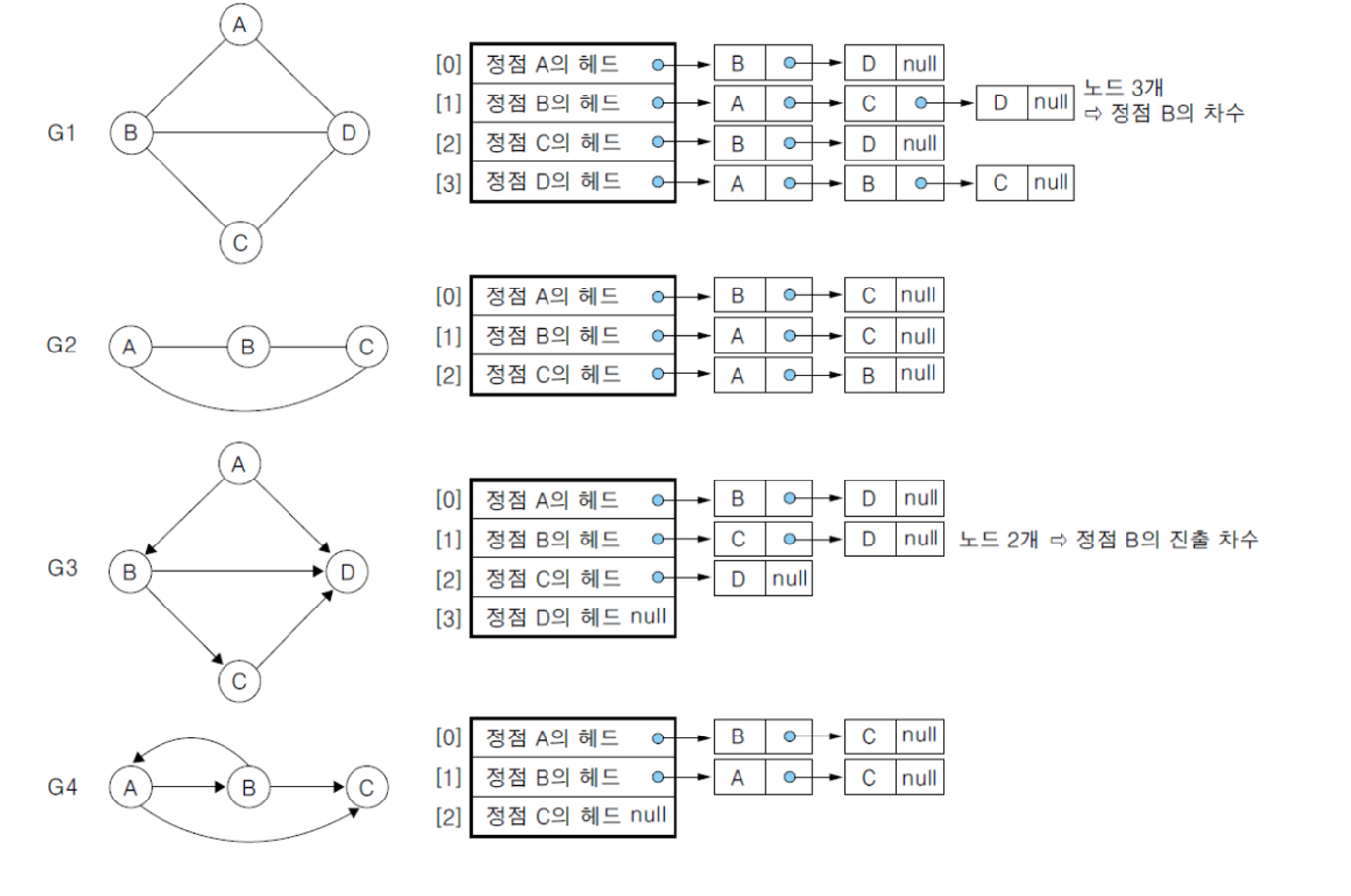
인접 리스트
각 정점에 대한 인접 정점들을 연결하여 만든 단순 연결 리스트 → 인접 행렬의 각 행을 연결리스트로
각 정점의 차수만큼 노드 연결 → 리스트 내의 노드들은 인접정점에 대해 오름차순 연결
인접 리스트의 각 노드 : 정점과 다음 정점을 연결하는 링크 필드
정점의 헤드 노드 : 정점에 대한 리스트의 시작
📌 그래프 순회
그래프 순회, 그래프 탐색 : 하나의 정점에서 시작하여 그래프에 있는 모든 정점을 한번씩 방문하여 처리하는 연산
- 깊이 우선 탐색 DFS
- 너비 우선 탐색 BFS
📌 깊이 우선 탐색 DFS
깊이 우선 탐색 = DFS = Depth First Search → 스택 사용
- 시작 정점 v를 결정하여 방문
- 정점 v의 인접 정점 중에서
- 방문하지 않은 정점이 있으면, 정점을 스택에 push하고 방문
- 방문하지 않은 정점이 없으면, 방향을 바꾸기 위해 스택을 pop하여 받은 가장 마지막 방문 정점에서 다시 2번시작
- 스택이 공백이 될 때까지 2를 반복
깊이 우선 탐색 예시
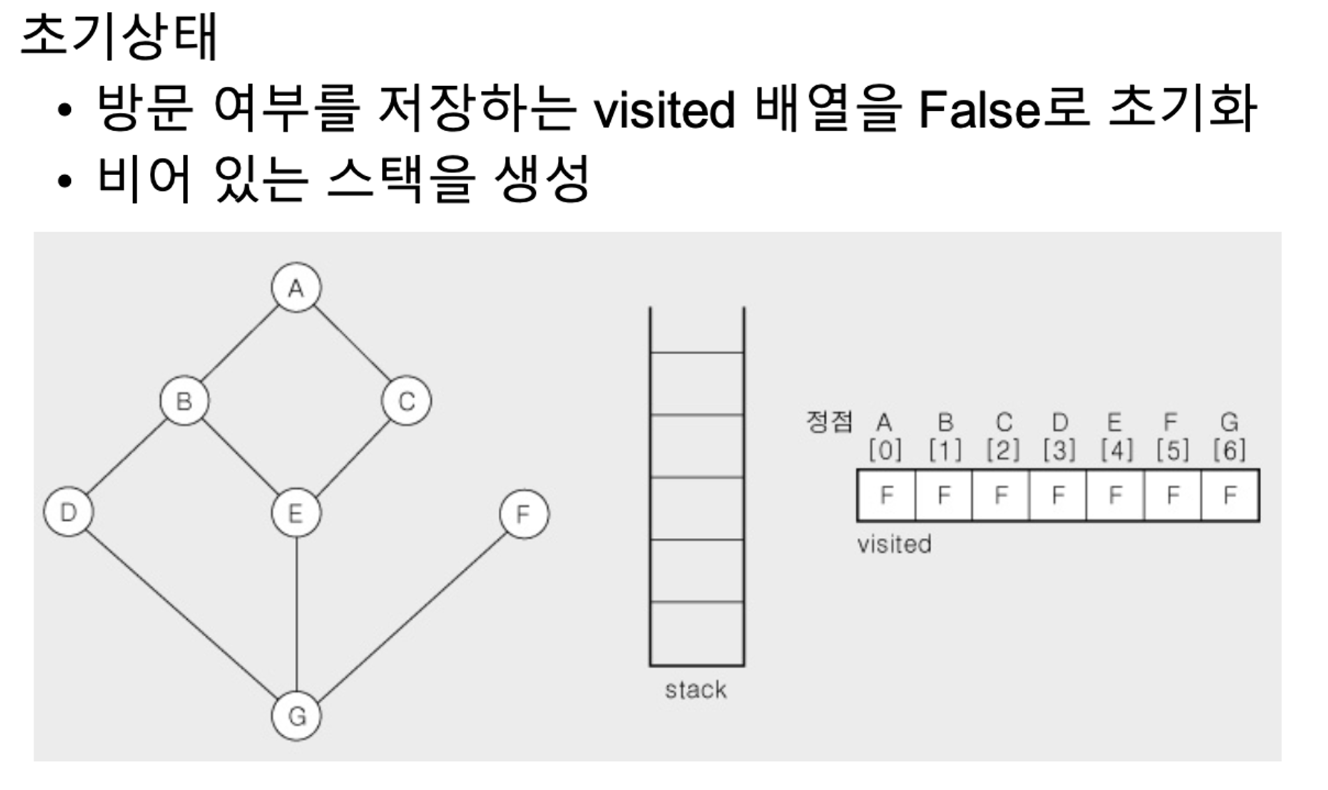
- 정점 A를 시작
- A에 방문하지 않은 정점 B,C가 있으므로 A를 스택에 push하고 B먼저감(오름차순)
- B에 방문하지 않은 정점 D,E가 있으므로 B를 스택에 push하고 D먼저
- D에 방문하지 않은 정점 G가 있으므로 D를 스택에 push하고 G로
- G에 방문하지 않은 정점 E,F가 있으므로 G를 스택에 Push하고 E먼저
- E에 방문하지 않은 정점 C가 있으므로 E push하고 C로
- C에서 방문하지 않은 인접정점이 없으므로 스택 top의 E를 pop하면서 확인
- E도 방문하지 않은 인접정점 없으므로 스택 top의 G를 pop하면서 확인
- G에서 방문하지 않은 정점 F가 있으므로 G를 스택에 push하고 F로
- F에서 방문하지 않은 인접 정점 없으므로 스택 top의 G를 pop하면서 확인
- 스택이 공백이 될 때까지 이렇게 pop해주면됨
인접리스트 구현 : O(V) + O(E)
인접 행렬 구현 : O(n^2)
📌 너비 우선 탐색 BFS
너비 우선 탐색 = BFS= Breadth First Search → 큐 사용
- 시작 정점 v를 방문
- v에 인접한 모든 정점들을 방문
- 새롭게 방문한 정점들에 인접하면서 아직 방문하지 못한 정점들을 방문
- 인접한 정점들에 대해서 차례로 다시 너비 우선 탐색을 반복해야 하므로 선입선출의 구조를 갖는 큐를 사용
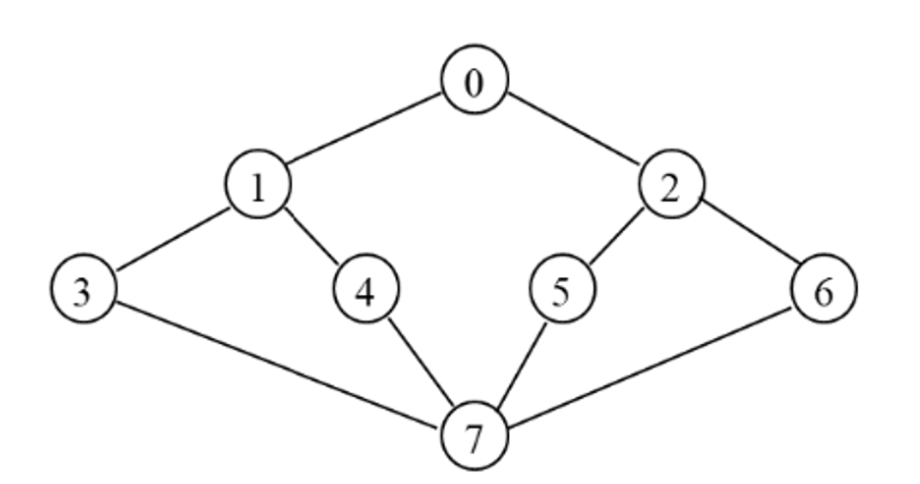
0, 1, 2, 3, 4, 5, 6, 7순으로 방문
너비 우선 탐색 예시
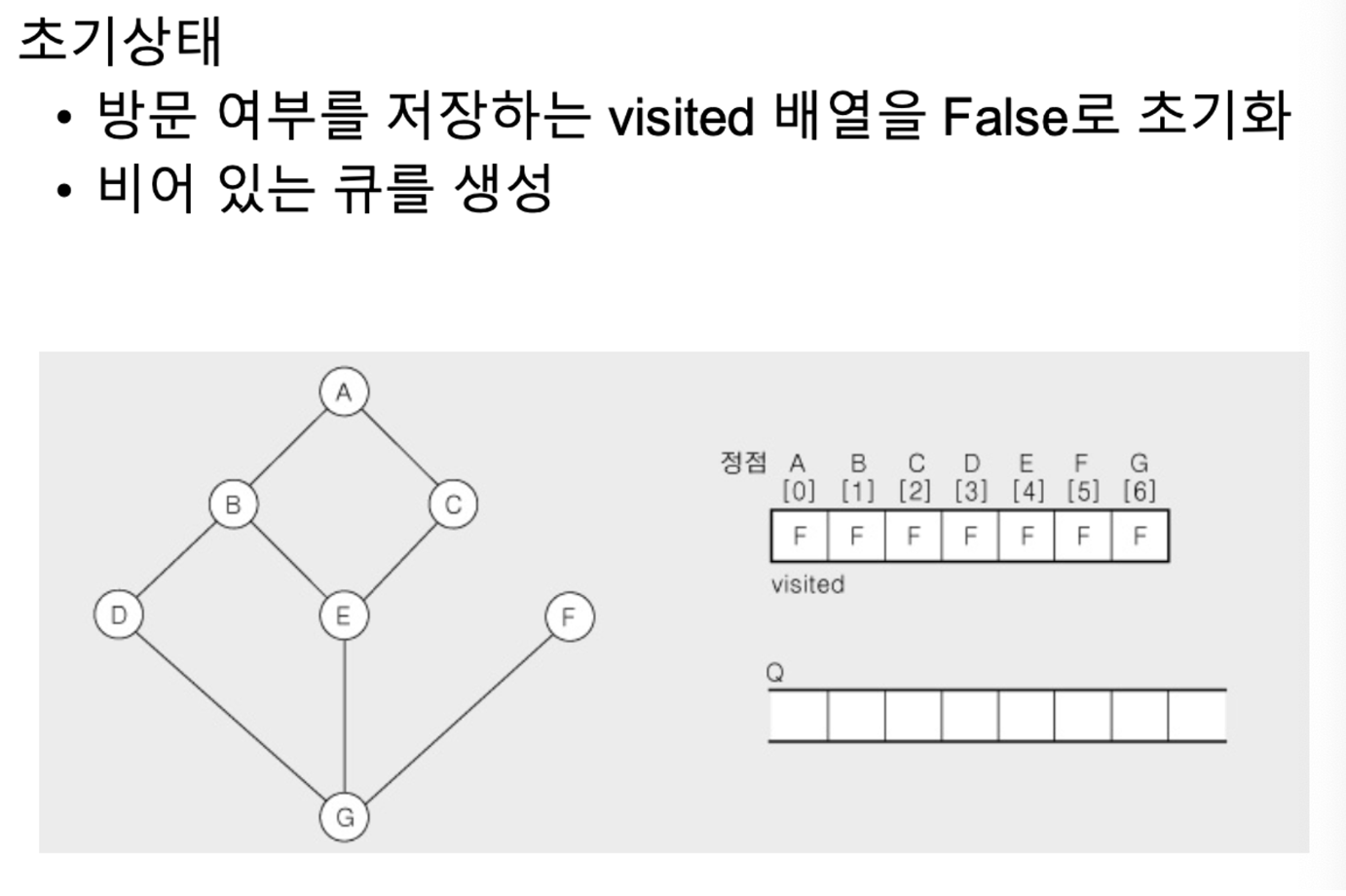
- 정점 A에서 시작
- 정점 A의 방문안한 모든 인접 정점 B,C를 방문하고 큐에 enqueue
- A의 인접 정점 처리했으므로, 큐를 dequeue하여 정점 B를 처리
- 정점 B의 방문안한 모든 정점 D,E를 방문하고 큐에 enqueue
- B의 인접 정점 처리했으므로, 큐를 dequeue하여 정점 C를 처리
- C에는 방문안한 인접 정점 없으므로, 큐를 dequeue하여 정점 D를 처리
- 정점 D의 방문안한 모든 정점 G를 방문하고 큐에 enqueue
- D의 인접 정점 처리했으므로, 큐를 dequeue하여 정점 E를 처리
- E에는 방문안한 인접 정점 없으므로, 큐를 dequeue하여 정점 G를 처리
- 정점 G의 방문안한 모든 정점 F를 방문하고 큐에 enqueue
- 큐가 공백이 될 때까지 dequeue
📌 최소 비용 신장 트리
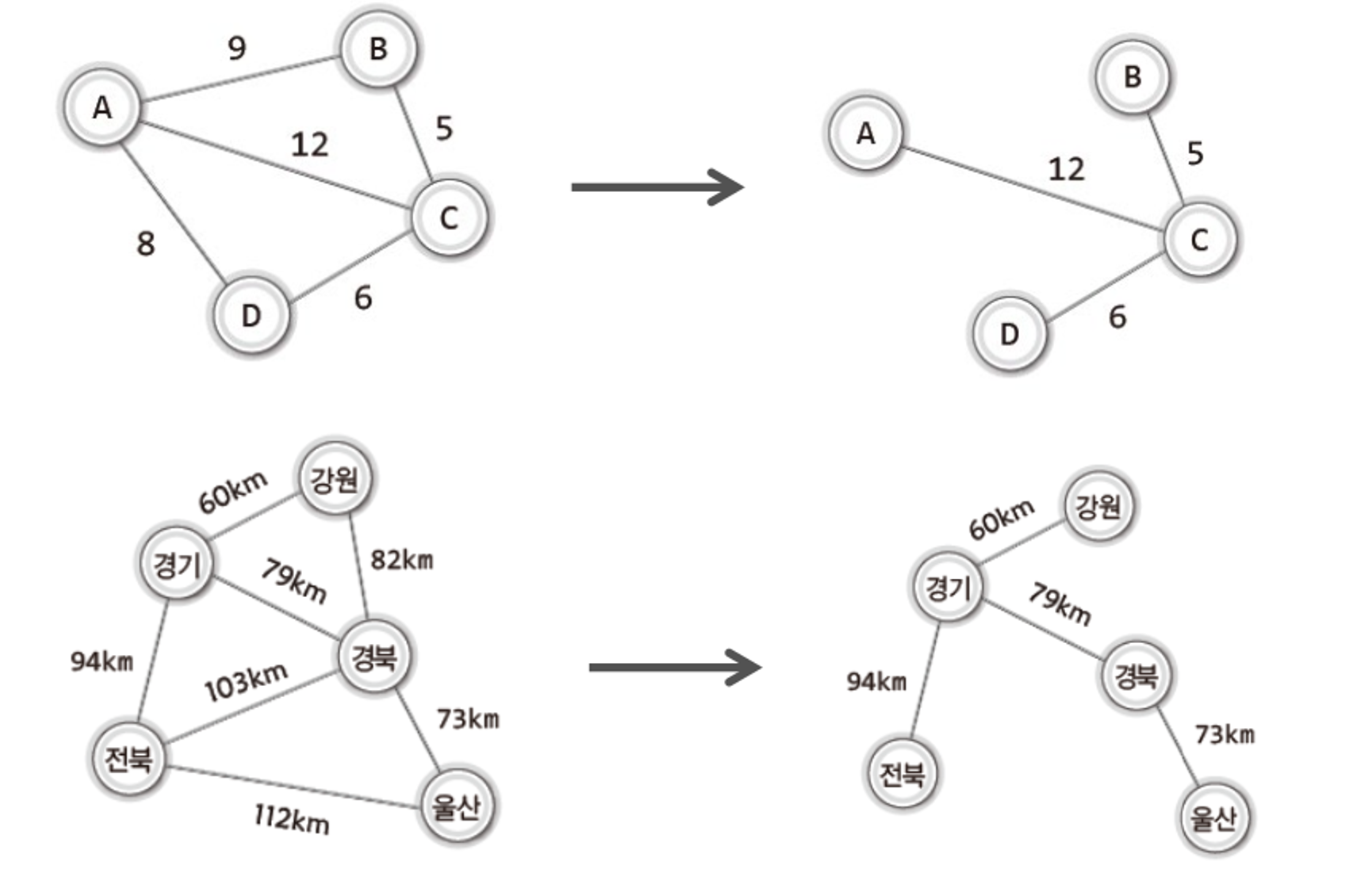
신장 트리 : G의 간선들로만 구성되고 G의 모든 정점들이 포함된 트리 → 즉, 그래프에서 일부 간선을 선택해서 만든 트리
- 깊이 우선 신장 트리 : 깊이 우선 탐색을 이용해서 생성
- 너비 우선 신장 트리 : 너비 우선 탐색을 이용해서 생성
신장 트리는 G의 최소부분 그래프
n-1개의 간선을 가짐(사이클 없음)
최소 비용 신장 트리 : 무방향 가중치 그래프에서 신장트리를 구성하는 간선들의 가중치 합이 최소인 신장 트리 → 즉, 무방향 그래프이며, 모든 정점들이 포함되며, 가중치 합이 최소
최소 비용 신장 트리를 만드는 알고리즘
- Kruskal - 간선 추가/삭제
- Prim - 간선을 연결하면서 트리 확장
📌 Kruskal 알고리즘
Greedy algorithm 그리디 알고리즘
매순간 최적의 해를 단계별로 도출
각 단계에서 판단기준에 따라 최상의 결정을 선택. 그러나 결정 번복은 불가능
최종적인 최적해에 도달
그리디 알고리즘이 잘 작동하는 조건
- 탐욕스런 선택 조건 : 앞의 선택이 이후의 선택에 영향을 주지 않음
- 최적 부분 구조 조건 : 문제에 대한 최적해가 부분 문제에 대해서도 최적해
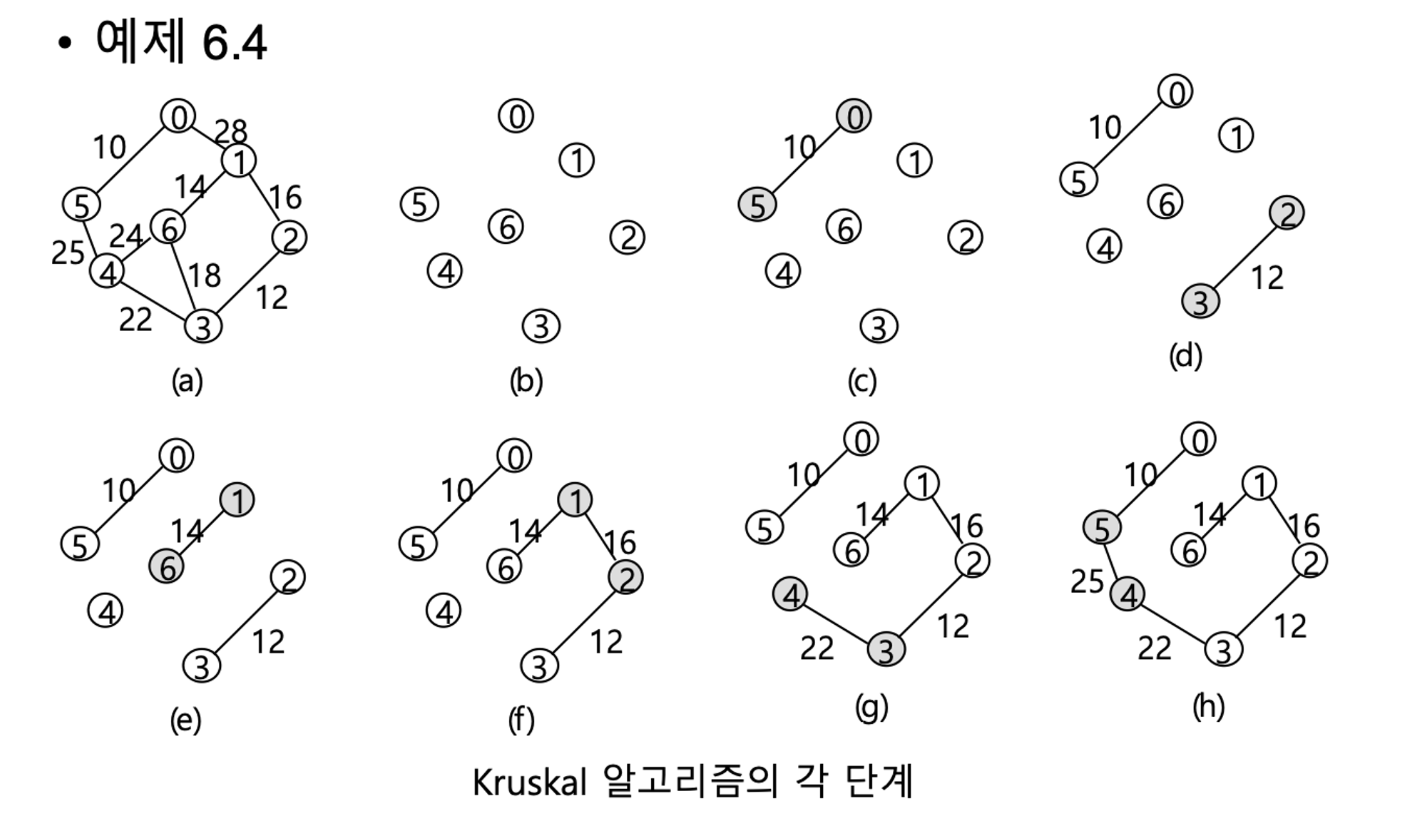
kruskal 알고리즘 : 간선 추가 or 삭제 → 간선 위주 알고리즘
전체에서 가장 비용이 낮은 간선 추가한다
이때 사이클 생기는지 간선 추가할때마다 확인해줘야함 → 사이클을 형성하지 않는 간선만 추가
가중치 낮은 간선부터 정렬할때 시간복잡도 mlogm(퀵정렬)
시간 복잡도 O(mlogm) → m은 간선 개수
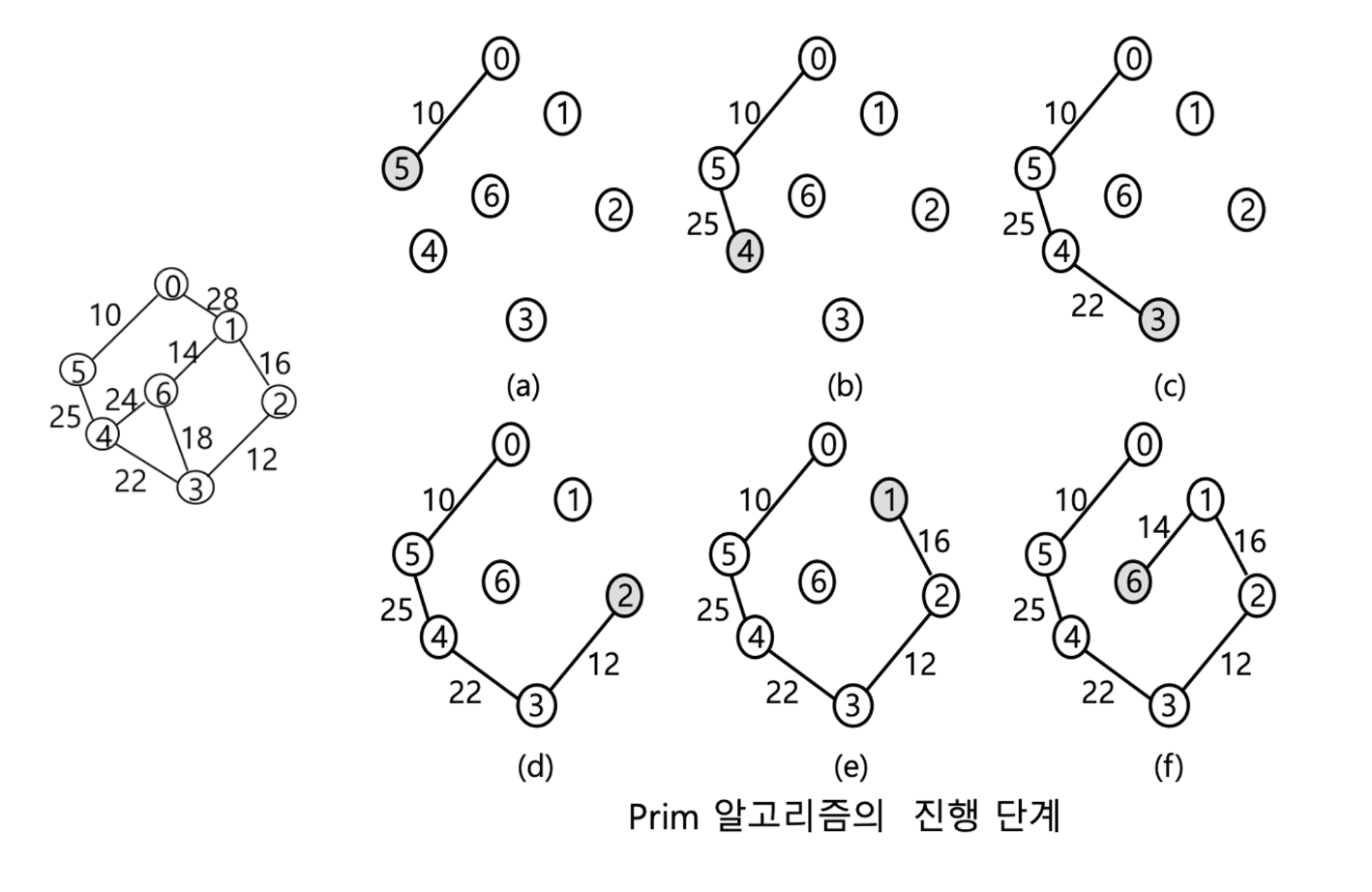
📌 Prim 알고리즘
prim 알고리즘 : 간선을 정렬하지 않고 하나의 정점에서 시작하여 간선을 연결하며 트리를 확장해 나가는 방법 → 정점 위주 알고리즘
정점에 연결되어 있는 간선들 중 가장 가중치가 작은 간선 추가 → 추가한 정점의 주변 간선들 갱신 → 반복
kruskal에 비해 사이클 검사는 적음 → prim은 사이클이 안생김
정점이 많을 경우에 안좋다
시간 복잡도 O(n^2)
📌 최단 경로
최단 경로 : 하나의 정점에서 다른 모든 정점까지
시작점에서 목표점까지의 경로중, 경로를 구성하는 간선들의 가중치 합이 최소가 되는 경로
차이점은 시작점과 끝점이 있다는 것
📌 Dijkstra 다익스트라 알고리즘
- 시작점에서 시작
- 연결된 간선들 중 최소 비용 간선을 보고 노드 선택
- 선택된 간선을 적용하여 나머지 경로 비용을 갱신 : 간선 완화
- 최소 비용 간선을 보고 노드 선택하고 간선완화 과정 반복
음의 가중치는 허용되지 않음
다른 정점들과의 시간 계산 O(n) * 모든 정점 다 (n-1) → 시간복잡도 O(n^2)
📌 Bellman and Ford 벨먼포드 알고리즘
모든 경로의 가중치합을 구한다는 개념 → 몇개의 노드를 거쳐갔는지
간선 1,2,3, …개 방문했을때의 최단거리를 단계별로 확인
매 단계마다 모든 간선을 전부 확인하면서 모든 노드간의 최단거리 구해나감
↔ 다익스트라 : 방문하지 않은 노드 중에서 최단거리가 가장 가까운 노드만 방문
음의 가중치 허용
시간복잡도가 느리다는 단점이 있음 → O(VE)
플로이드 워셜 알고리즘
모든 정점 쌍의 최단 경로
하나가 아닌 모든 정점을 시작점으로 하는 최단 경로
음이 아닌 가중치 : O(n^3)
음의 가중치 허용 : O(n^4)
