
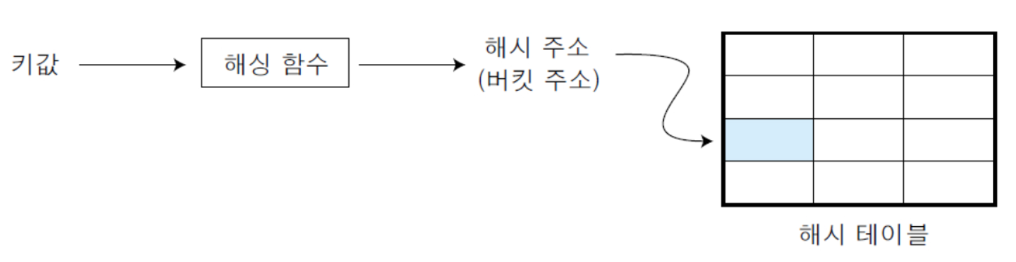
📌 hashing 해싱
산술적인 연산을 이용하여 키가 있는 위치를 계산하여 바로 찾아가는 계산 검색 방식
- 키 값에 대해서 해싱함수를 계산하여 주소를 구하고
- 구한 주소에 해당하는 해시 테이블로 바로 이동 → 해당 주소에 찾는 항목 있으면 검색성공, 없으면 실패
- O(1)안에 변환하는게 목표
해싱 함수 : 키 값을 원소의 위치로 변환하는 함수
해시 테이블 : 해싱 함수에 의해 계산된 주소의 위치에 항목을 저장한 표
테이블 자료구조
데이터가 key & value로 한 쌍을 이룸
key가 데이터의 저장/탐색 도구
탐색 시간 O(1) → 바로 찾을 수 있음
해싱 용어
- 충돌 : 서로 다른 키 값에 대해 해싱 함수로 구한 버킷 주소가 같은 경우 충돌 발생 시, 비어 있는 슬롯에 동거자 관계로 키 값 저장
- 동거자 : 서로 다른 키 값을 가지지만 해싱 함수에 의해서 같은 버킷에 저장된 키 값들
- 오버플로우 : 버킷에 비어 있는 슬롯이 없는 포화 버킷 상태에서, 충돌이 발생하여 해당 버킷에 키 값을 저장할 수 없는 상태
- 키 값 밀도 : 실제 사용 중인 키 값의 개수 / 사용 가능한 키 값의 개수
- 적재 밀도 : 실제 사용 중인 키 값의 개수 / 해시 테이블에 저장 가능한 전체 키 값의 개수 = 실제 사용 중인 키 값의 개수 / 버킷 개수 * 슬롯 개수
📌 해싱 함수의 종류
조건
- 계산이 쉬워야한다 : 비교연산 시간보다 계산시간이 짧아야 의미가 있음
- 충돌이 적어야한다 : 충돌이 많으면 버킷에서 오버플로우가 발생할 수도 있으므로
- 해시 테이블에 고르게 분포할 수 있도록 주소를 만들어야 한다
-
중간 제곱 함수
키 값을 제곱한 결과 값에서 중간에 있는 적당한 비트를 주소로 사용

-
제산 함수
나머지 연산자 mod를 사용하는 방법
키 값 k를 해시테이블 크기 M으로 나눈 나머지를 해시 주소로 사용 → h(k) = k mod M
0 ~ M-1의 인덱스가 생김
충돌이 발생하지 않고 고르게 분포되기 위해서 M은 적당한 크기의 소수를 사용
-
승산 함수
곱하기 연산 사용 방법
키 값 k와 정해진 실수 a를 곱한 결과에서 소수점 이하 부분만을 테이블 크기 M과 곱하여 주소로 사용
-
접지 함수
키의 비트수가 해시 테이블 인덱스의 비트 수보다 큰 경우에 주로 사용
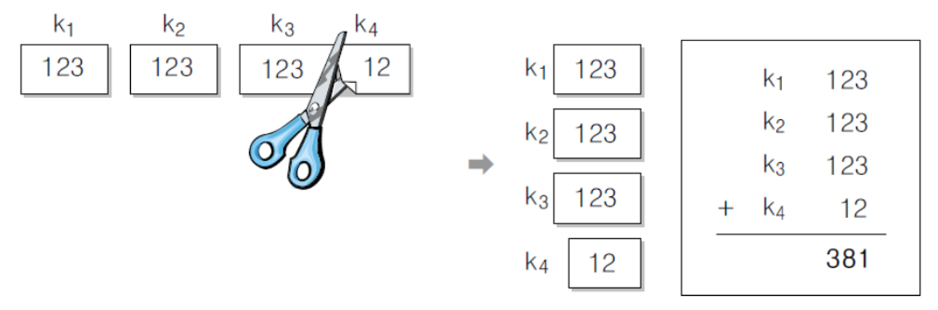
- 이동 접지 함수 : 각 분할 부분을 이동시켜 오른쪽 끝자리 맞추고 더하기
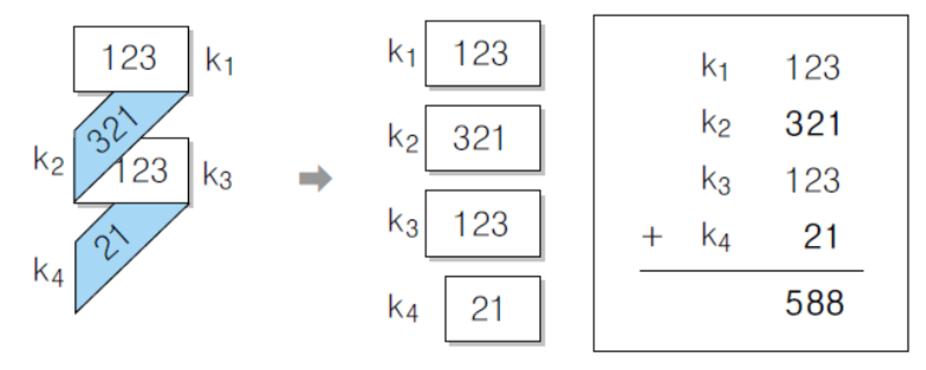
- 경계 접지 함수 : 분할된 경계를 기준으로 접으면서 서로 마주보도록 배치하고 더하기
- 이동 접지 함수 : 각 분할 부분을 이동시켜 오른쪽 끝자리 맞추고 더하기
-
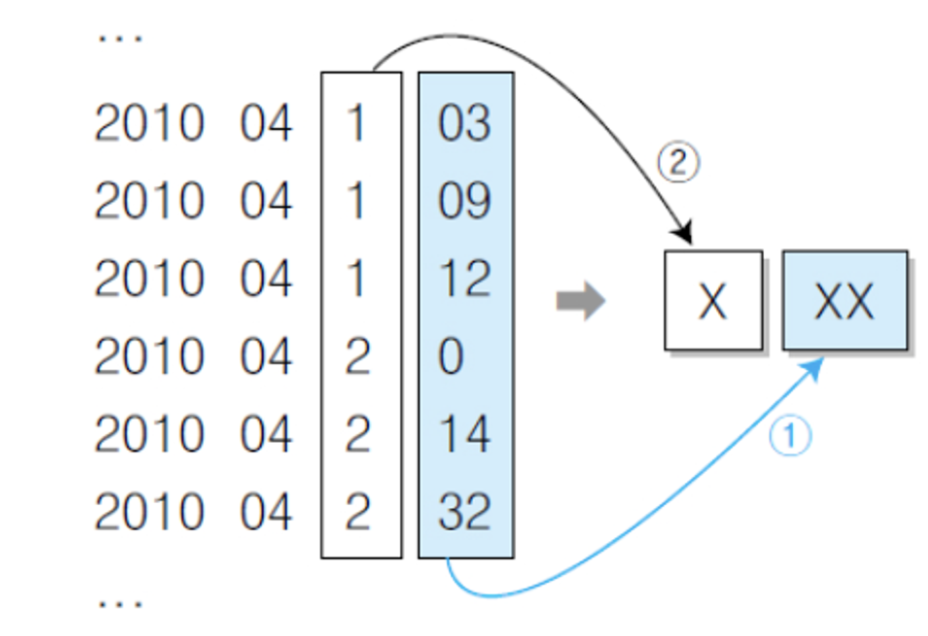
숫자 분석 함수
키 값을 이루고 있는 각 자릿수의 분포를 분석하여 해시 주소로 사용
가장 고르게 분포된 자릿수부터 해시 테이블의 자릿수만큼 차례로 뽑아 역순으로 사용
📌 오버 플로우 처리 방법 - 개방 주소법
-
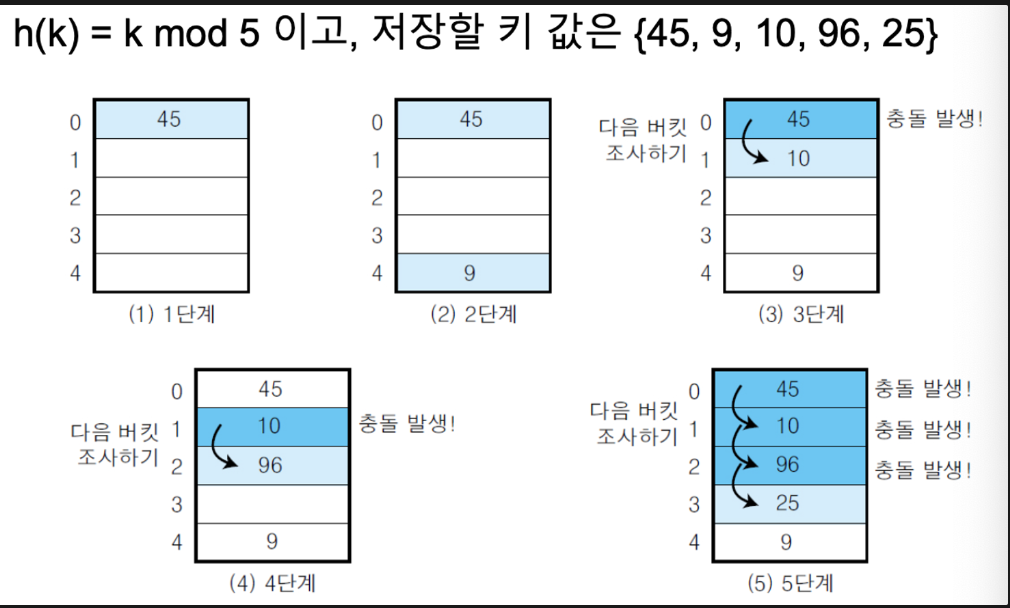
선형 조사법
원래 들어가야할 위치에 자리가 없으면 바로 다음 위치에 저장 → 거기도 자리 없으면 계속 +1칸씩 이동

단순하지만 충돌의 횟수가 증가함에 따라서 클러스터 현상(특정 영역에 데이터가 몰리는 현상)이 발생가능
빈자리가 있는 버킷이 없다면 해시 테이블이 꽉찬 상태로 테이블 크기를 늘려야함
적재밀도 = 0.75와 같은 경계값을 넘을 때 테이블 크기 늘림
→ 테이블 크기 다시 정할 때 해시 함수 바꿔야하고 모든 사전 엔트리들은 새로 커진 테이블에 다시 사상되어야 함
-
이차 조사법
선형 조사법보다 멀리서 빈자리를 찾는다

deleted 상태로 별도 표시를 해두어야 동일한 해쉬 값의 데이터 저장을 의심할 수 있다
→ empty 비었다 / deleted 데이터가 있었는데 삭제되었다 / inuse 데이터가 있다
위와 같은 status 정보 사용
-
재해싱 : 여러개의 해시 함수를 사용하는법
-
임의 조사법
📌 오버 플로우 처리 방법 - 체이닝
선형 조사법과 같은 방법들이 효율이 좋지 않은 이유 : 키를 탐색할 때 서로 다른 해시 값을 가진 키와 비교를 해야 하기 때문
체이닝(=체인법) : 해시 테이블의 구조를 변경하여 각 버킷에 하나 이상의 키 값을 저장할 수 있도록 하는 방법 → 연결리스트 사용
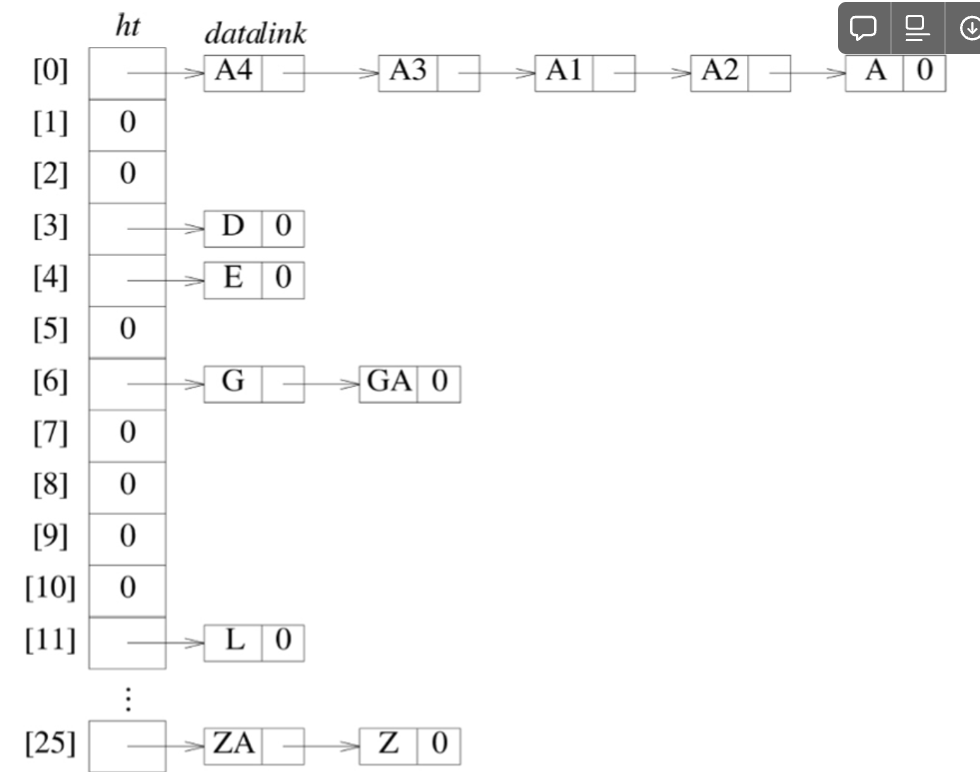
단점 : 순차접근을 해야하므로 시간복잡도가 증가
📌 동적 해싱
해시 테이블에 삽입으로 인해 테이블의 크기가 커지게 되는 경우, 모든 엔트리에 대해 재조정 필요
→ 동적 해싱(=확장성 해싱) : 재조정을 한 번 할 때마다 오직 하나의 버킷 안에 있는 엔트리 들에 대해서만 홈 버킷을 변경하게 하여 재조정 시간을 줄임
디렉터리를 이용한 동적 해싱
버킷들에 대한 포인터를 저장하고 있는 디렉터리 이용
디렉터리의 크기 : 해시 주소의 비트수에 좌우됨. 버킷 수 < 디렉터리 크기
디렉터리의 깊이 : 디렉터리를 인덱싱하는 해시 주소의 비트 수
