5.1 Aggregate Functions : 집계 함수
5개의 집계함수 지원. 각 함수는 테이블의 속성에 지원가능하며, 하나의 value를 리턴
avgminmaxsumcount
select count(*) --()안에 key value가 들어가면 같은 결과
from student;student 테이블에서 튜플의 개수를 리턴
null값이 있으면 세지 않는다
Select avg(salary), max(salary), min(salary)
from professor
where deptName= ’CS’;: 컴퓨터학과의 교수들의 평균, 최대, 최소 연봉을 출력
Select count(distinct pID)
from teaches
where semester=’Fall’ and year=2014;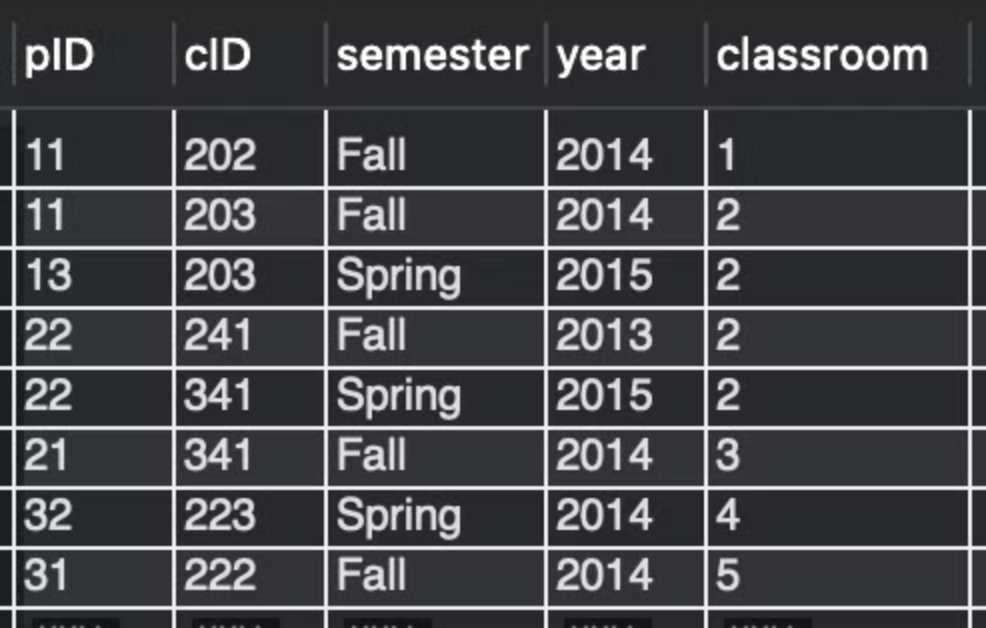
teaches 테이블
2014년 가을에 강의한 교수들의 아이디 반환
distinct를 사용했으므로 중복없이 : 한교수가 여러과목 했었어도 한개만 셈
ex) count(distinct gender) : 2 → (M/F니까)
Group By Clause
group by : 전체 테이블을 속성값으로 튜플을 분류하고, 나누어진 각 그룹에 대해 집계함수 적용
Select deptName, count(*)
from professor
group by deptName;deptName 속성값으로 전체 튜플을 몇개의 그룹으로 나눈후에 각 그룹에 대해 count
Select deptName, avg(salary)
from professor
group by deptName;professor 테이블에서 deptName 속성값으로 그룹을 분류한 후, 각 그룹에 대해 salary 속성의 평균값 구함

위의 두 예제에 대한 결과값
주의사항
Select deptName, pID, avg(salary)
from professor
group by deptName;group by절에 나온 속성과 집계함수만이 select 절에 나올 수 있음
→ pID는 그룹수보다 많이 존재하므로 뭘 보여줘야하는지 선정불가
Select avg(salary)
from professor
group by deptName;
group by절에 나온 속성은 select절에 나오는 것이 좋으나 반드시 나와야하는 것은 아님
→ 위 예시의 경우 deptName 생략시 어떤 그룹에 대한 평균값인지 알 수 없음
Having Clause
group by절로 생성한 그룹에 대해 임의 조건을 명시하는데 사용
→ 반드시 group by가 먼저 나와야함! 없으면 잘못된 쿼리
Select deptName, avg(salary)
from professor
group by deptName
having avg(salary) > 6900;deptName 기준으로 그룹 생성
→ 각 그룹에 대해 avg(salary) > 6900 조건 만족하는 절만 남김
→ 만족하는 절에 대해 select 뒤에 나오는거 출력
having : 각 그룹에 대해 적용하여 만족하는 그룹이 다음 단계로 이관됨
where : 각 튜플에 적용하여 조건을 만족하는 튜플이 grouping 등의 다음단계로 넘어가는 것
→ 둘이 동시에 존재하면 where절 조건이 먼저 적용되고 group by, having 순서로
employee(name, salary, dno) -- dno는 dnumber 참조하는 외래키
department(dnumber, dname, location)다섯명 이상의 직원을 가진 부서에 대해, 부서의 이름과 $40,000이상을 버는 직원 수를 리턴
Select dname, count(*)
from department, employee
where dnumber=dno and salary>40000
group by dname
having count(*)>5;where 조건문이 가장먼저 실행되는데 여기서 salary > 40000이상인 직원튜플만 남게됨
→ 직원수를 먼저세고 salary를 비교해야함
Select dname, count(*)
from department, employee
where dnumber=dno and salary>40000 and
dno in (select dno from employee
group by dno
having count(*)>5)
group by dname;dno in (세트) : 세트안에 dno 존재시 참, 아닐시 거짓
→ 해당 문장 내부에서 직원수가 5명이상인 부서의 no 구할 수 있다
→ 하지만 이것도 문제 있다!
만약 관리처 부서의 직원이 10명인데 모두 40000불 이하의 연봉일때 : <관리처, 0> 튜플이 결과 테이블에 속해야하나 관리처 튜플이 결과에 전혀 속하지 않게됨
where절의 salary > 40000절에 의해 모든 직원 튜플이 사라져서 후에 dno in에 관리처가 속하게 되더라도 적용할 튜플이 없음
Null Values and Aggregates
count(*)을 제외한 집계 함수는 기본적으로 null값 무시
sum : 널값 무시하고 계산
만약 salary라는 속성의 모든 값이 널이라면?
→ count(salary) : 0리턴
→ 다른 모든 집계함수들 null 리턴
ex) sum(salary) : null리턴
Null Example

myTable 테이블
select count(hourWage) from myTable;
// 결과 2count(*) 아니므로 null값 무시
Select count(distinct hourWage) from mytable;
// 결과 2위에랑 같은 결과 나옴
마찬가지로 null은 무시
Select sum(hourWage) from mytable;널값은 무시하고 연산 : (5000+6000)/2 = 5500 나옴
Select hourWage, count(*) from mytable group by hourWage;
group by hourWage하면 Null값을 하나의 값으로 취급
count(*)이므로 널값 무시하지 않는다
5.2 Joined Relations
join 연산은 2개의 relations을 받아 하나의 relation을 결과로 리턴한다
조인에 필요한거 2가지
- join type
- inner : match하는것만 → inner 키워드 생략가능. join 연산은 inner join 의미
- outer left : outer는 다 match 아닌것도
- outer right
- outer full
- join condition : match 기준 정함
- nutural
- on
- using(A1,…An)
4*3 = 12가지의 join가능 + cartition product 3개
Outer Joins
외부 조인은 값 매치가 되지 않아 손실되는 정보를 유지하려고 하는 연산
일차적으로 조인연산을 수행하고, 조인 연산에서 제외된 튜플들을 널 값을 이용해 결과 테이블에 첨가
Join Conditions : 조인 조건
두 입력 테이블에서 어떤 조건으로 튜플이 매치되는지 결정하고, 어떤 속성이 결과 테이블에 나타나는지 결정
- natural 공통되는 속성이 조인 속성 공통되는 속성은 결과 테이블에 한번만 나온다
- on
- using(A1,…An) 내추럴 조인과 비슷 using(A1,…An) : A에 컬럼을 다 적으면 natural이랑 같은 셈
조인 연산 예시

myCourse inner join myPrereq
on myCourse.cID = myPrereq.cID내부 조인 : 매치가 되는 튜플만 결과 테이블에 나오게됨
매치조건 : on
→ on : pred 조건에 만족하는 것만 매치됨
| myCourse.cID | title | deptName | credit | myPrereq.cID | prereqCID |
|---|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-301 | BIO-101 |
| CS-301 | DB | CS | 4 | CS-301 | CS-101 |
myCourse left outer join myPrereq
on myCourse.cID = myPrereq.cIDleft outer join : 1차적으로 join한 후 left테이블인 myCourse의 튜플 다 살림
매치조건 위와 동일(하지만 매치안되는 것도 살아있다)
| myCourse.cID | title | deptName | credit | myPrereq.cID | prereqCID |
|---|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-301 | BIO-101 |
| CS-301 | DB | CS | 4 | CS-301 | CS-101 |
| CS-302 | AI | CS | 3 | null | null |
myCourse natural left outer join myPrereq
myCourse left outer join myPrereq using(cID)
-- 위 두개 동일한 쿼리natural : 공통되는 속성이 조인속성이고, 속성 하나만 남김
left outer join
| cID | title | deptName | credit | prereqCID |
|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-101 |
| CS-301 | DB | CS | 4 | CS-101 |
| CS-302 | AI | CS | 3 | null |
5.3 Nested Subqueries : 중첩 서브질의
SQL은 중첩되는 서브 질의에 대한 매커니즘 제공
서브쿼리는 다른 SQL 문장 안에 위치할 수 있는 select-from-where 문장임
set membership과 set comparison을 테스트할 때 자주 사용
Single-row Subquery = scalar subquery
단일 튜플을 반환하는 서브질의
Select name
from professor
where salary = (select salary from professor where pID=‘10’)
and pID <> ‘10’;
-- <>는 != 의미괄호 안에 있는 서브질의는 1개의 튜플을 반환하므로 single row subquery = scalar subquery
= 기호는 반환값이 한개일때만 사용 가능
Select name
from professor
where salary = (select max(salary)
from professor
where deptName=‘CS’);max()값은 항상 단일값이므로 유효한 SQL 문장
IN Operator
in 연산자는 단일값이 다수값에 속하는지 검사
Select name, salary
from professor
where pID in (10, 21, 22);
Select name, salary
from professor
where pID=10 or pID=21 or pID=22;세명 다 있다면 다 리턴
속하는 것만 나온다고 보면됨
Comparison Operators
값 하나 간의 비교는 간단하나 값 하나와 여러값 간 비교는 간단하지 않음
SQL은 이를 위한 연산자(some, any, all, in)을 제공
(1 > 2) : false
(3 >all {2, 3}) : false // 모든조건이 만족해야하는데 아니므로
(3 >some {2, 3}) : true
(3 >any {2, 3}) : true // any ≡ someall : 모두 참이여야 참
some(또는 any) : 여러값 중 적어도 하나가 참이면 참
Some(any)절 정의
= some 은 속한다는 의미의 in 연산자와 동일
≠ some은 다수개중의 하나와도 같지 않으면 참인데 not in은 전체에 속하지 않아야 참이므로 동일하지 않음
(5 <some {0, 5, 6}) = true
(5 <some {0, 5}) = false // 모든 조건이 만족하지 않으므로
(5 =some {0, 5}) = true
(5 ≠some {0, 5}) = true (since 0 ≠ 5) // 하나만이라도 같지 않으므로 참all절 정의
(5 <all {0, 5, 6}) = false // 모든조건이 만족해야하는데 아님
(5 <all {6, 7}) = true
(5 =all {4, 5}) = false
(5 ≠all {6, 7}) = true (since 5≠6 and 5≠7) // 모든조건이 !=를 만족≠ all은 모든 원소와 동일하지 않아야 참이므로 not in과 동일의미
= all과 in은 동일하지 않음
Set Comparison Example
Select distinct T.name
from professor as T, professor as S
where T.salary > S.salary and S.deptName=’CS’;
-- 위 아래 동일
Select namefrom professor
where salary > some (select salary
from professor
where deptName=’CS’);CS학과 교수 중 적어도 한명보다는 봉급이 많은 교수 이름 구하는 질의
Select name
from professor
where salary >all (select salary
from professor
where deptName=’CS’);
-- 위아래 동일
Select name
from professor
where salary > (select max(salary)
from professor
where deptName=’CS’);CS학과의 모든 교수보다 연봉이 높은 교수
Correlated Subqueries
중첩질의에서 외부 쿼리에서 사용되는 테이블과 내부 쿼리에서 사용되는 테이블은 서로 상관없어서, 내부 쿼리가 외부 쿼리에 상관없이 실행 가능
내부쿼리가 외부쿼리의 테이블을 참조하면 이를 상관서브질의(상관중첩질의)라고 함
- 서브쿼리는 외부 테이블에서 한 개의 튜플을 골라 이에대해 내부 중첩 질의 수행
- 시간 매우 많이 듦
exits Construct
exists : 인자 형태로 표현되는 서브질의의 결과과 존재하면 참을 반환함
→ 즉, 내부질의를 수행하여 결과 튜플이 반환되면 참
Select S.cID
from teaches as S
where S.semester = ’Fall’ and S.year= 2009
and exists (select *
from teaches as T
where T.semester = ’Fall’ and T.year= 2010
and S.cID = T.cID);2009년 가을과 2010년 가을에 둘다 개설된 강의의 번호 구하는 쿼리
exits 표현을 사용하는 상관 중첩질의
외부 테이블을 S로 rename하고 이를 exits내부 절에서도 사용
exits without Correlation
상관 서브 질의를 사용하지 않는 exits 연산자 사용은 의미 없음
Select distinct sID // nonsense query
from student
where exists (select cID // where절 다 빼도 의미 같음
from course
where deptName = ’CS’);
해당 쿼리는 중첩질의가 외부 질의문과 관련이 없음
for all 쿼리
for all 의미를 구현하는 연산자 SQL에서 제공 X → not exits 사용
Select S.sID, S.name
from student as S
where not exists ( (select cID
from course
where deptName = ’CS’)
except (select T.cID
from takes as T
where S.sID = T.sID) ); 
X - Y = 공집합
→ X 가 Y에 속함을 의미
→ not exist (X except Y)로 구현
Unique Construct
unique 구성요소는 서브질의 결과에 중복성이 있는지 찾음
Select C.cID
from course as C
where unique (select T.cID
from teaches as T
where C.cID=T.cID and T.year=2009);
--위아래동일
Select C.cIDfrom course as C
where 1 >= (select count(T.cID)
from teaches as T
where C.cID=T.cID and T.year=2009);2009년에 최대 1번 강의한 과목을 찾아라(1번 이하로 개설된 과목)
unique{<1,2>, <1,2>} : false
unique{<1,2>, <1,3>} : true
unique{<1,2>, <1,null>} : true
unique{<1,null>, <1,null>} : truenull값이 나오는 튜플은 중복으로 나와도 unique하다고 판단
unique(r)에서 만약 r이 공집합이면 unique(r)은 참
from절 서브질의
서브질의 from절 안에서 사용 가능
Select deptName, avgSalary
from (select deptName, avg(salary) as avgSalary
from professor
group by deptName)
where avgSalary > 6900;
Select deptName, avgSalary
from (select deptName, avg(salary)
from professor
group by deptName) as deptAvg(deptName, avgSalary)
where avgSalary > 6900;
Select deptName, avg(salary)
from professor
group by deptName
having avg(salary) > 6900;
-- 세개다동일 마지막은 from절 내 서브질의 안쓰고 having절 이용평균연봉이 6900이상인 과 이름과 평균 연봉 구하기
Select max(totalSalary)
from (select deptName, sum(salary)
from professor
group by deptName) as deptTot(deptName, totalSalary);
-- 위아래 동일
Select sum(salary)
from professor
group by deptName
having sum(salary) >= all (select sum(salary)
from professor
group by deptName);총 연봉이 가장 높은 과의 총 연봉을 구하시오
lateral 절
from절에서 선행관계 또는 서브질의를 참조하게함
Select P1.name, P1.salary, avgSalary
from professor P1, lateral (select avg(P2.salary) as avgSalary
from professor P2
where P1.deptName= P2.deptName);Select name, salary, avg(salary) // syntax error
from professor
group by deptName;name, salary, avg(salary)값 개수가 다 틀려서 틀린 쿼리
With 절
SQL 문장의 결과를 임시적으로 저장하는 효과
With maxBudget(value) as
(select max(budget)
from department)
select deptName, budget
from department, maxBudget
where department.budget = maxBudget.value;with deptTotal(deptName, value) as
(select deptName, sum(salary)
from professor
group by deptName),
deptTotalAvg(value) as
(select avg(value)
from deptTotal)
select deptName
from deptTotal, deptTotalAvg
where deptTotal.value > deptTotalAvg.value;deptTotal : deptName당 해당과에 속하는 교수의 봉급 합
deptTotalAvg : deptName당 교수봉급합의 평균값
Scalar Subquery
서브질의가 오직 한개의 속성을 반환하고 동시에 속성값으로 한개를 반환한다면, 서브질의가 연산식에서 값이 반환되는 어떤 곳이라도 나타날 수 있게함
→ 이런 서브질의를 scalar 서브질의라고함
Select deptName, (select count(*)
from professor p1
where d1.deptName = p1.deptName)
from department d1;스칼라 서브질의 예시
5.4 Ranking
SQL 서버 : Select top(3) * from professor ordery by salary
// 상위 연봉 3인
MySQL : Select * from professor order by salary desc limit 3 offset 1;
// 상위 연봉 3인인데 최고 1명 제외
5.5 More Features
blob, clob : 대용량 객체 저장 관리
📖 데이터베이스 1: 이론과 실제, 이상호, 진샘미디어
