- 9:00 ~ 10:00 : 코드카타, 데일리 뉴스
- 10:00 ~ 10:30 : 오전 스크럼
- 10:30 ~ 11:00 : 머신러닝 강의
- 11:00 ~ 12:20 : 머신러닝 세션
- 12:20 ~ 13:00 : 머신러닝 세션 복습
- 14:00 ~ 16:20 : 머신러닝 강의, 4조 코드스터디 참관
- 16:20 ~ 18:00 : JD 둘러보기
- 19:00 ~ 20:00 : JD 둘러보기
- 20:00 ~ 21:00 : 데일리 스크럼 및 TIL 작성
코드카타
내적
def solution(a, b):
answer = 0
for i, v in enumerate(a):
answer += a[i]*b[i]
return answer오늘의 다른 사람 풀이
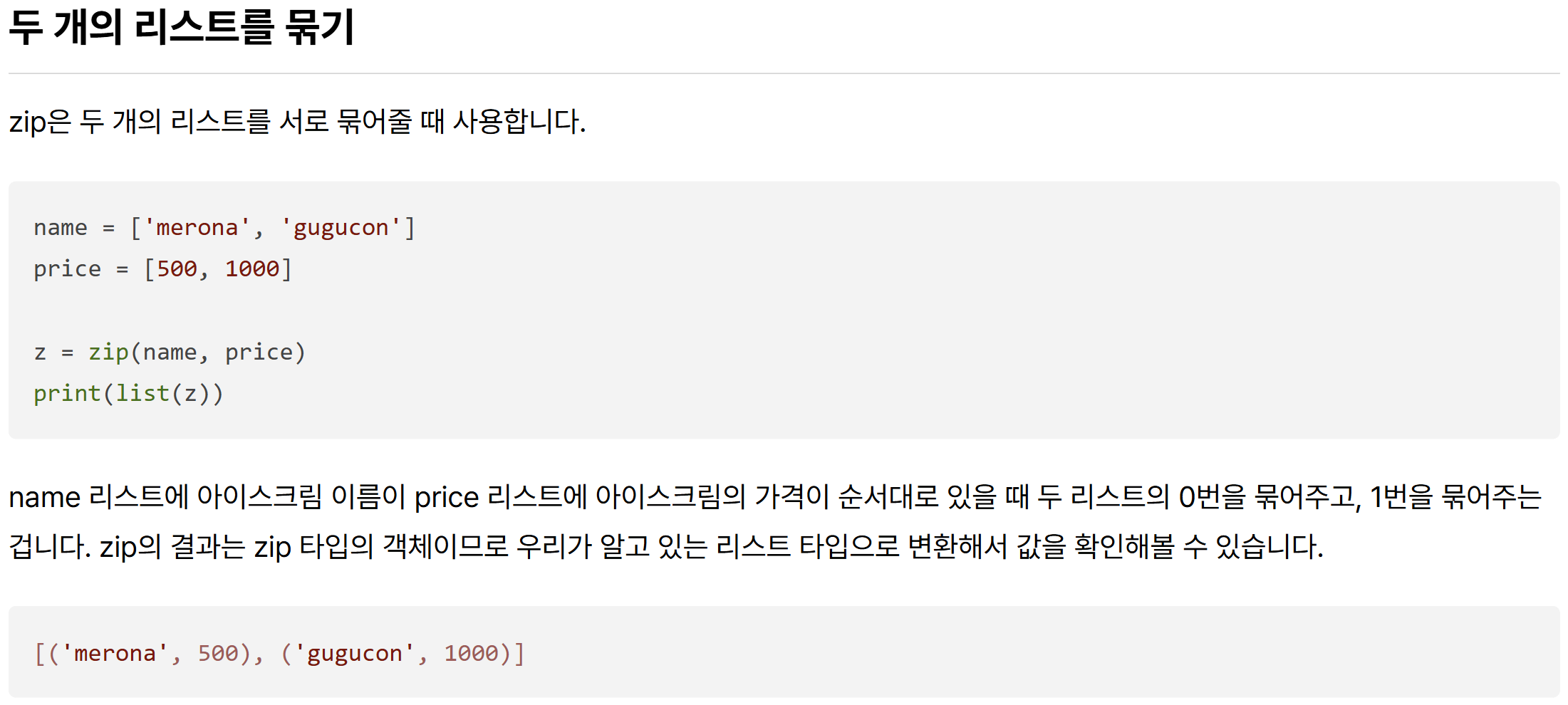
def solution(a, b):
return sum([x*y for x, y in zip(a,b)])zip이 뭐였드라..
개인학습시간
머신러닝 1-11~1-15
- 다중선형회귀
인코딩 과정에서 apply 메소드 - 간단한 전처리에 자주 사용
다중선형회귀에서는
x = [[a,b]] x변수 이렇게 지정함#학습
model_lr.fit(X,y)
#예측
model_lr.predict(X)
#평가
mse, R^2-
선형 회귀의 가정
선형성: x,y가 선형 관계
등분산성: 오차들이 뭔가 패턴, 모양이 있어보인다? 선형회귀 말고 딴 거 해야함
정규성: 오차가 정규분포 따라야 함
독립성: 다중공선성(x끼리 상관성 있는 거) 없어야 함 -
선형회귀의 장단점
장점: 직관적이고 이해 쉽다
단점: 이상치에 민감(평균 포함해서), 범주형 변수 인코딩하면 정보 손실 -
로지스틱 회귀
로지스틱 함수는 가중치 값을 안다면 X값이 주어졌을 때 해당 사건이 일어날 수 있는 확률을 계산할 수 있게 됨 -
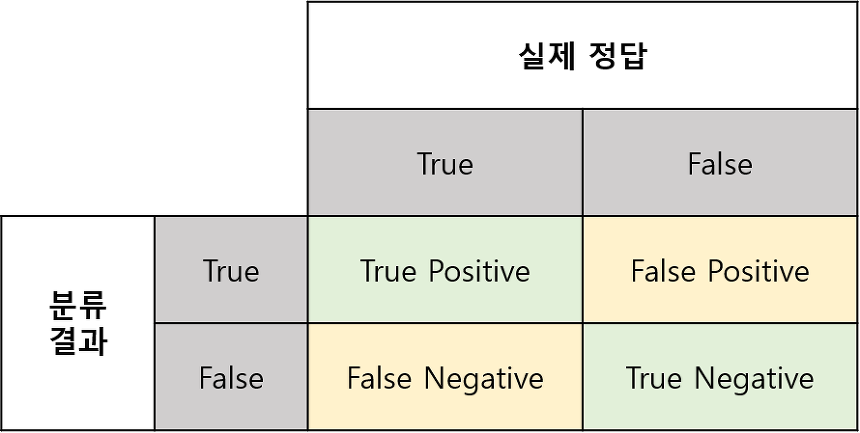
정확도/정밀도/재현율/f1-score
정확도 - 맞춘 거/전체
100명 중 암환자 5명 있는데 다 정상이라고 우겨도 정확도은 95%가 나오는 한계
.
그래서 f1-score 보는 거임
f1-score = 2(정밀도재현율)/(정밀도+재현율)
정밀도: TP/(TP+FP) 모델 관점
재현율: TP/(TP+FN) 데이터 관점
머신러닝 심화 세션
학습
학습
모델을 학습한다 -> 오답률을 줄여나가는거~
모델 학습할 때마다 이것저것 많이 시도해봐야함 (하이퍼파라미터도 요래조래)
특성 공학(피처 엔지니어링)
새로운 지표 만들기
BMI 계산 했던 것도 특성공학이다~~
그렇다고 지표가 많다고 좋으냐? 그건 또 아니다~~
튜닝
하이퍼파라미터 -> 수치 조절해서 꿀조합 찾기(like 하이디라오 건희소스)
꿀조합 찾았다고 끝인가? 당연히 아님
공정과정이 조금씩 변함에 따라서 하이퍼파라미터도 다시한번 생각해봐야한다! (탕 정했다고 끝아니고 뭐 넣어먹느냐에 따라서 소스 다르게)
.
과적합
학습 데이터에 너무 딱맞춰져서 실제 데이터에서는 정답률이 낮을 때
- 데이터가 부족할 때
- 모델의 복잡도가 넘 높을 때(원리는 모르고 깜지로 달달 외운 느낌인거임)
어떻게 방지하지..?
규제, 교차 검증, 드롭아웃(딥러닝. 무작위.ver 선택과 집중)
.
프로세스
머신러닝 왜 배워?
- 사람이 놓치는 부분을 캐치
룰 베이스의 간단한 거까지 사용한다는 건 X
복잡한 작업에 쓴다~
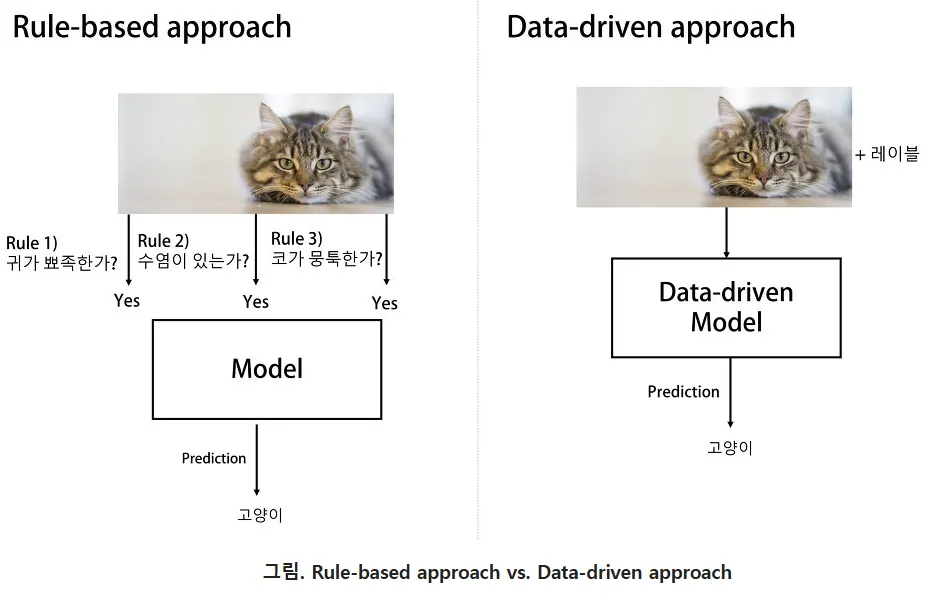
코가 뭉툭한 고양이
룰 베이스, 모델 베이스 내 분야에선 어떤 게 있을까
-
사전 예방, 예지 보전
통계 -> 사후처리
머신러닝 -> 사전예방 -
비정형 데이터
머신러닝으론 이미지나 영상 데이터 분석도 가능~
사람은 24시간 불가능인데 기계는 가능이다~
문제 정의 & 목표 설정
무엇보다 중요한 건 문제 정의와 목표 설정
나는 진로에 대해서 제대로 확립이 되었는가
내 진로에서는 지금까지 배운 것들을 어떻게 써먹을 수 있는가
데이터 수집 & 전처리
Garbage In, Garbage Out
구린 재료로도 요리는 되지만 맛있게 되느냐?
데이터 품질 ↑ => 모델 성능 ↑
진짜 실무에서의 찐rawdate는 전처리만 한 세월 걸린다
- 데이터 전처리
중복 데이터라고 다 지워야 좋은 게 아님.
중복 데이터가 왜 발생했는가도 해결해야할 문제일 수도 있음
이상치 탐지를 하려면 어디까지를 정상으로 잡을건지부터 제대로 정해놔야 함
EDA 왜 하는데?
분석 방향을 알아보기 위해. 재료 손질
Garbage In 안 할라면 꼼꼼하게
.
모델 선택 & 학습
문제에 따라, 데이터 특성에 따라, 환경과 인프라에 따라 모델 선택
현장 적용까지가 고려해야할 요소임!!!
상황에 따라서 성능 조금 높아지고 느려지는 것보다
성능이 조금 모자라도 예측속도가 빠른 게 나을 수도 있음! (예측이 빨리 되어야 공정과정에 빠르게 적용할 수 있고, 그래야 손실을 줄일 수 있기 때문)
과적합을 방지하기 위해 조기 학습 종료를 하는 경우도 있음
.
하이퍼파라미터 튜닝
설정 미세조정해서 꿀조합 찾기
계속 첮아보고 적용해보고 더 나은 방법을 생각해보고...의 연속
머신러닝에 대한 개요를 살펴볼 수 있었고, 친숙한 내용들을 예시로 들어 이해하기 쉬웠음. 머신러닝에서도 그렇듯 항상 중요한 건 문제 정의와 목표 설정이라고 느낌. 나무가 아닌 숲을 보면서 내 진로에 필요한 걸 취사선택할 수 있도록 해야겠다고 생각함.
JD 둘러보기
다시 한번 숲을 보기 위해서 채용 공고들 좀 둘러봤다
얀국약품 공고 중에 R&DQA 직무에 관심이 생겨서 내일은 기업분석을 해볼까 싶다
국가통합바이오빅데이터구축사업단
JD는 아닌데 국민 의료 데이터 모으는 사업 중인가 봄. 신기하다~
회고
오늘 세션에서 채팅 좀 열심히 했다..ㅎㅎㅎ
그리고 깜짝퀴즈 선착순 3인 안에 들어서 100포인트도 받았음 희희~~
세션 들으면서 또 한번 내가 나무를 보고있구나를 자각하곤 채용공고들을 살짝 봤다
관심가는 곳들이 있긴한데 내 스펙으로 될까 싶기도 하고
괜히 시간 낭비하는 하는 게 아닐까 걱정도 되고
그렇지만 해야한다!
주말에 세웠던 계획
체력 증진을 위해 수영 갔다오기!
ADsP 3과목 강의 듣기 △
통계 세션 끝내기 (중요한 것만 하고 후딱후딱 넘어가기)
ADsP 3과목 강의 오늘 아침에 침대에서 살짝 들음..ㅋㅋㅋ
.
내일 할 거
- 머신러닝 강의 완강
- 머신러닝 세션
- 아티클 읽고 스터디
- 안국약품 기업분석
- 통계 코드필사 조금만
