- 9:00 ~ 9:30 : 오전 스크럼
- 9:30 ~ 10:00 : 코드카타
- 10:00 ~ 11:00 : 머신러닝 코드필사
- 11:00 ~ 12:00 : 머신러닝 심화 3 세션
- 12:00 ~ 15:00 : 세션 복습, 점심시간
- 15:00 ~ 16:00 : 4조랑 머신러닝 스터디
- 16:00 ~ 17:00 : 사례 찾기, 아티클 찾기
- 17:00 ~ 18:00 : ADsP 3과목 공부
- 19:00 ~ 20:00 : ADsP 3과목 기출 풀기
- 20:00 ~ 21:00 : 오후 스크럼, 통계 세션 필사, TIL
코드카타
문자열 내림차순으로 배치하기
def solution(s):
u=[]
l=[]
for char in s:
if char.isupper() == True:
u.append(char)
else:
l.append(char)
l.sort(reverse=True)
u.sort(reverse=True)
return ("".join(l)+"".join(u))다른사람 풀이
def solution(s):
return ''.join(sorted(s, reverse=True))같은 길을 갔지만 나는 오리걸음으로 가고 있었다....ㅋㅎ
reverse하면 대소문자까지 바뀌는구나...
머신러닝 심화 3
오늘의 주제는 AutoML
학습 방향성
Waterfall: 이론부터 차근차근
Agile: 그냥 당장 해보고 수정하고 또 해보고
AI 튜닝: 첨부터 모양을 갖춘 상태에서 시작함. 점차 세부적으로 들어가서 수정하며 고도화
그래서 권장하는 방법은 바로 실습 들어가서 모르는 부분만 찾아서 발췌독
요즘에는 페이퍼를 보여주는 것뿐만 아니라
데모 버전을 만들어서 그것까지 만들어서 보여줘야함
.
AutoML
데이터 전처리부터 배포까지의 과정을 자동화 함.
(문제 정의 -> EDA -> 전처리 -> 모델링 -> 평가 -> 튜닝 -> 배포)
문제 정의만 잘 되어있으면 알잘딱깔센 해줌
왜 필요?
시행착오 최소화! -> 그래서 본질적인 문제 해결과 분석에 집중할 수 있도록 도움
AutoML은 단시간에 최적의 베이스라인 모델을 찾아줌
=> 가장 단순하고 기본적인 밑바탕을 깔아준다는 거. 시작점을 잘 찍어준다는 거.
여기서 더 발전 시키는 건 우리몫임
그래서 AutoML을 통해 아낀 시간으로 공정 개선 전략을 세우는데 더 힘써야 함
AutoEDA, AutoVisualizer 뭐 이런 것도 있나?
있네..!?
AutoEDA
plot(data) 딸깍하면 그래프 여러개 만들어줘서 데이터의 분포를 한눈에 볼 수 있음
plot_missing(data) 딸깍으로 결측치도 시각화
AutoViz
딸깍으로 차트가 착착 나옴
그렇지만 에러가 나는 경우도 있기 때문에 내가 실제도 차트 만들어서 비교검증도 필욯마
더 자세한건 링크 들어가서 보기
.
주요 도구 및 실습
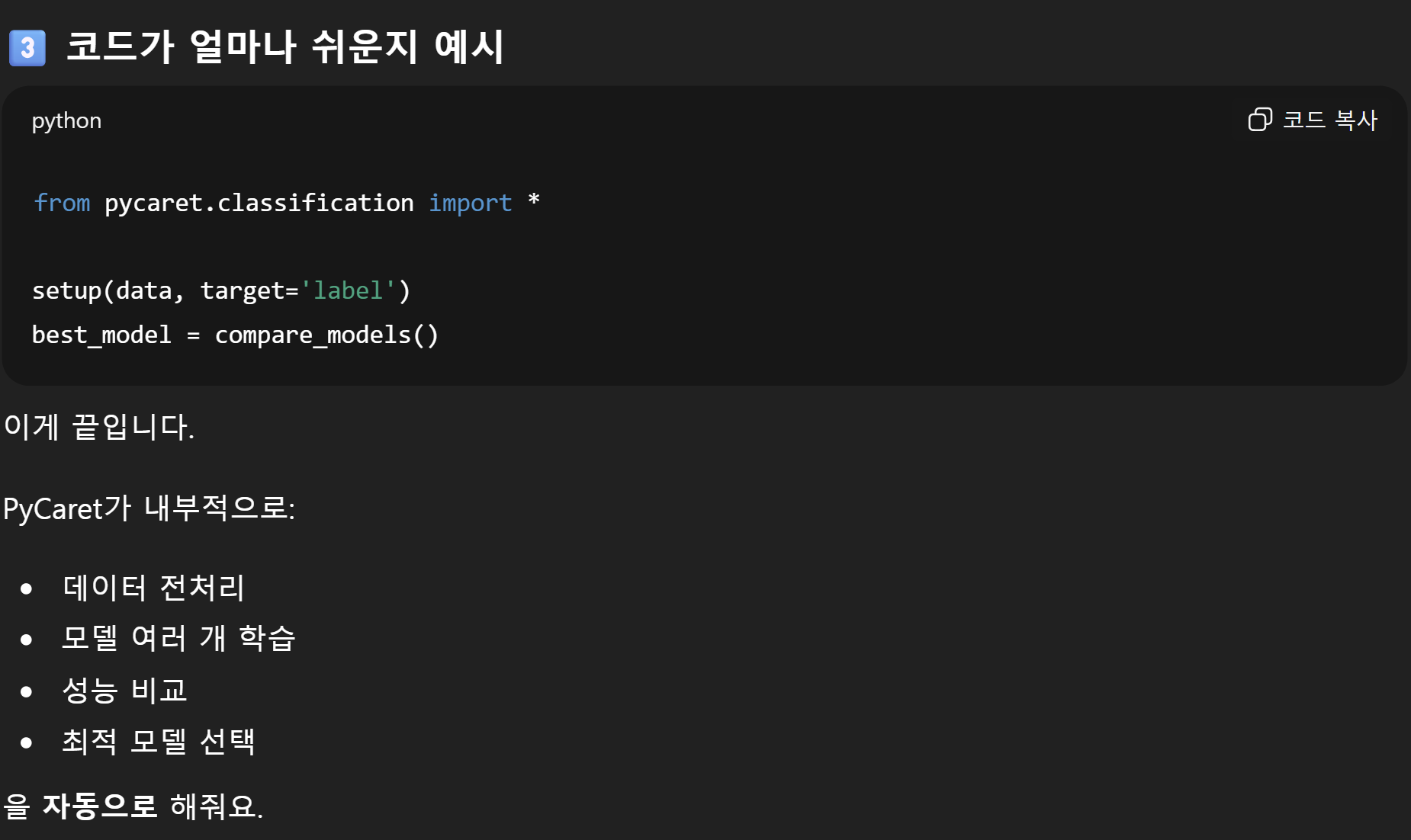
PyCaret
독스
PyCaret은 ML 실험에서 가설을 인사이트 사이클 타임으로 축소하는 것을 목표로 하는 오픈소스 로우코드 머신러닝 라이브러리입니다. 데이터 과학자들이 종단 간 실험을 빠르고 효율적으로 수행할 수 있게 해줍니다. 다른 오픈 소스 머신러닝 라이브러리와 비교할 때, PyCaret은 몇 줄의 코드만으로 복잡한 머신러닝 작업을 수행할 수 있는 대체 로우코드 라이브러리입니다.
=> 머신러닝 코드를 딸깍할 수 있게 도와준다~
데이콘: 신약개발 AI 경진대회
참가자 분이 pycaret을 이용해서 코드를 짰다고 하심
근데 아직은 뭔소린지 모르겠다....
암튼 이 안에 데이터도 있으니 참고해라
성능 중심의 도구들
좀 더 깊이있는 분석, 대규모 데이터가 필요하다? -> FLAML, Auto-Sklearn, AutoML 툴 (자세한 건 노션봐라)
클라우드 기반 AutoML
기업 중에 내부 자료가 유출되는 걸 방지하기 위해
회사 내부에서 사용가능한 AI를 사용하는 곳들도 많음
Google Cloud Vertex AI / AWS SageMaker
ㄴ 요런 거 쓰면 별도로 코딩 환경을 구축하지 않아도 뚝딱 됨
- 어떤 기업들이 사용하고 있나?
마켓컬리
검색 결과 개선에 사용했고, 문제 정의부터 모델링, 업데이트, 튜닝, 평가 과정까지 어떻게 진행했나 다 나와있음. 향후과제까지..!
결론적으론 Vertex AI를 적용한 결과, 검색 결과가 알잘딱깔센으로 나왔고 구매전환률이 상승함
티머니의 MLOps 구현 사례
MLOps는 또 먼데;;; -> 머신러닝 모델을 ‘만드는 것’이 아니라 ‘운영하는 방법론'..이라고 함.

음 글쿤
티머니 사례의 글에서도 문제 정의부터 구현결과까지 일련의 과정을 어떻게(어떤 논리로) 진행했는지 적혀있음.
이 사례에서 Amazon SageMaker를 통해 얻은 것은,,
택시 기사님들의 호출 수락 독려하기!
어떻게? 기사님들한테 마일리지 주기~ 하지만 마일리지를 너무 많은 기사님한테 드리면 회사가 손해....
그래서 머신러닝을 통해 수락할 확률이 낮은 기사님들을 추려서 그분들한테만 딜하는거임(더 얹어줄게 하쉴?)
결론적으로는 이게 배차 성공률을 높여줘서 기사님도 승객도 행복해졌다는 이야기
둘다 내가 관심있는 도메인은 아니지만, 실무가 어떤 흐름으로 진행되는지 참고하면 좋을듯
PyCaret vs 클라우드 기반 AutoML
두 개 개념이 좀 헷갈림
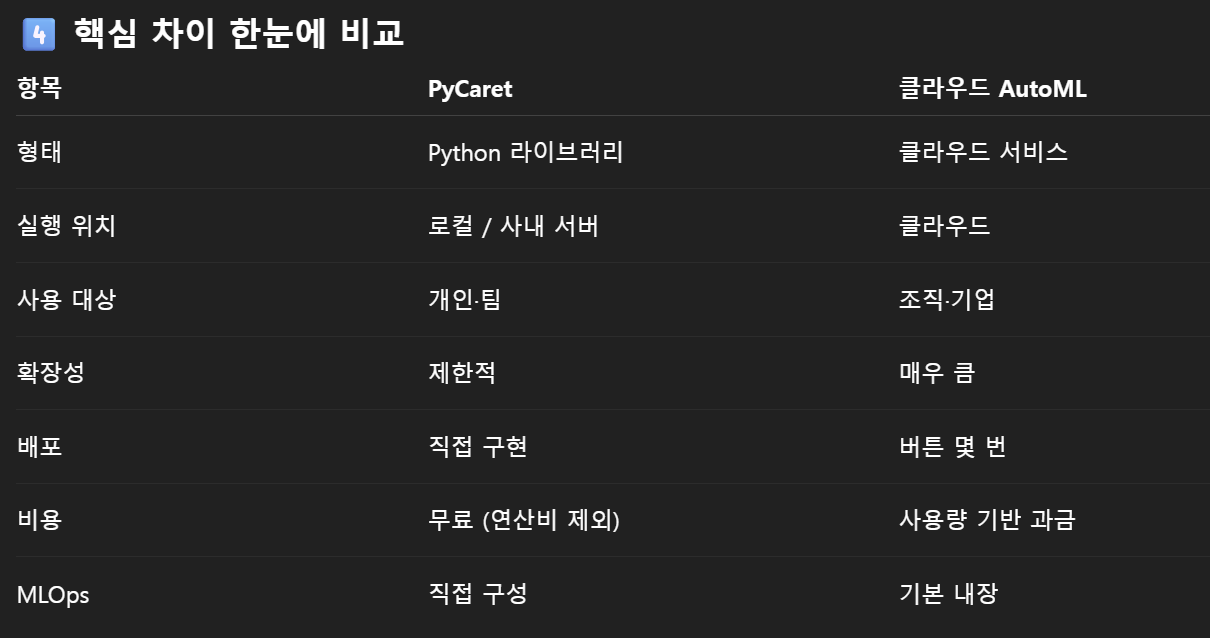
.
머신러닝 파이프라인 자동화범위
위키독스만 읽어도 도움 많이 됨
데이터 전처리부터~~앙상블까지 PyCaret 사용가능하다
위키독스 내용 개많아서 필요할 때 슥 훑어봐야할 듯
.
모델 평가 및 해석
AutoML이 만든다고 손놓고 있으면 안됨
얘가 어떤 원리, 근거로 만들었는지 확인해봐야 한다~(모델이 블랙박스가 되지 않도록)
뭐가 출력되었다고 다 가치가 있느냐? 아니다 재료가 쓰레기면 결과도 쓰레기
항상 왜 이런 결과가 나왔는지를 집요하게 생각해봐야함
모델이 내놓은 결과도 최상의 결과물이 아닐 수도 있음
모델은 내가 제시한 분석방향에 대한 최적의 결과를 냈을 뿐
그리고 실무에서 내 작업에 대해 얘기할 때도 청자에 따라서 설명하는 방법을 다르게 해야함
나도 모르게 상관관계를 인과관계로 생각하지 않도록 주의
데이터 증강
기존의 데이터를 변형하거나 확장하여 학습 모델의 성능을 향상시키는 기술
데이터의 특징을 더 학습시키기 위해서 데이터를 더 만들어 내는 거임
.
노션에 AI 실무 사례집 읽어보기
작은 성공 사례를 쌓아쌓아 크기를 키워가야함
실무적 관점에 대한 내용
문제를 해결하는 사람이 되자
회사는 월급의 10배가량의 매출을 가져다줄 인재를 원한다..
사수가 잘 가르쳐줄거라는 기대는 하지마라
스스로 잘 배워나가자(지피티 사수와 함께)
스스로 내 한계를 단정짓지마라
결국 다 내가 해봐야 의미가 있는 거임인사이트
이번 세션을 복습하면서 가장 많이 쓴 단어가 딸깍인 것 같음. 그만큼 AutoML, AutoEDA, AutoViz 같은 자동화 시스템이나 PyCaret 같은 라이브러리가 효율성을 높여준다는 의미라고 생각함. 누구나 이런 도구들은 쉽게 사용할 수 있다는 건, 오히려 사람이 처리해야 하는 작업을 어떻게 수행하느냐에 따라서 결과물의 퀄리티를 결정되겠다고 느꼈음. 분석 방향성 수립, 양질의 데이터 준비, 적절한 평가지표 선정, 그리고 지속적인 업데이트 전략 등의 영역에서 논리적으로 설계할 수 있는 역량이 필요할 것이라 생각함.ADsP
ADsP 3과목 45회 기출 풀기
코드필사
회고
ㅇ
.
내일 할 거
- 머신러닝 심화 내용으로 문제 2개 만들기
- ADsP 오답 다시 훑어보고 기출 1회 풀기
- 장단점 검사 해보기(잠올때)
- 사례집 뜯어보기
