이제 마지막 마무리만 남았다. 자연재해와 지역에 해당하는 트윗을 실시간으로 스트리밍하여 트윗 모델에 저장 후에 트윗을 지도에 띄우는 작업만 남았다.
1. Tweet 모델 만들기
class DisasterTag(models.Model):
name=models.CharField(max_length=5)
def __str__(self):
return self.name
class Tweet(BaseModel):
twid = models.TextField() #트윗의 id
time = models.TextField() #트윗 생성시간
text = models.TextField() #트윗 텍스트
user = models.TextField() #트윗 사용자
disaster_tag = models.ForeignKey(DisasterTag, on_delete=models.CASCADE, null=True, blank=True)
location = models.ForeignKey(Mark, on_delete=models.CASCADE, null=True, blank=True)
def __str__(self):
return str(self.disaster_tag) + " - " + str(self.text)자연재해 모델과 트윗 모델을 만들어주었다. Mark모델과 DisasterTag 모델을 외래키로 연결해서 만들어주었다. 트윗의 필드들 중 time, text, user, disaster_tag를 지도에 띄어줄 예정이다.
2. 트윗 실시간 스트리밍해서 모델에 저장하기
우선 스트리밍하는 함수와 모델에 저장하는 함수를 따로 만들어서 각각 파일을 만들어주었다.
스트리밍하는 함수는 아래와 같다. 다른 중복제거나 rt제거하는 함수들은 제외하고 핵심부분만 넣었다.
트위터를 실시간으로 스트리밍하는 방법은 [Python] 트위터 API로 크롤링하기 여기에 잘 나와있다.
retrieve.py
def search_tweets(queries):
twids = [] # id_str (아이디)
times = [] # created_at (생성시간)
texts = [] # text (텍스트)
users = [] # user name (유저 이름)
stream = twitter_api.GetStreamFilter(track=queries)
delay = 60 * 1 # 60 seconds * 1 minutes
close_time = time.time() + delay
# 1분동안 트윗 데이터 모으기
for tweets in stream:
# removeRT(tweets['text'])는 RT(리트윗)을 제거해주는 함수이다.
# exceptWord(tweets['text'])는 스트리밍하다보면 부적절한 트윗들이 섞여서 들어오는 데 그런 트윗들을 제거해주는 함수이다.
if removeRT(tweets['text']) and exceptWord(tweets['text']):
#utc2kst는 utc시간을 한국시간으로 바꾸는 함수이다
times.append(utc2kst(tweets['created_at']))
texts.append(tweets['text'])
twids.append(tweets['id_str'])
users.append(tweets['user']['name'])
if time.time() >= close_time:
break
# 1분동안 트윗 데이터 모은 후 모두 반환
return twids, times, texts, users다음은 실시간으로 스트리밍해온 트윗들을 모델에 저장해주는 함수이다.
main.py
def job():
# 트윗 가져오기 (retrieve)
twids, times, texts, users = search_tweets(queries) # 추출
if len(texts) > 0: # 분석할 트윗이 존재
# 트윗 지역과 자연재해별로 분류하기 (classify)
disasters, regions = classify_tweets(texts)
for twid, time, text, user, disaster, region in zip(twids, times, texts, users, disasters, regions):
if disaster != "None" and region != "None":
tag_d = DisasterTag.objects.get(name=disaster)
mark = Mark.objects.get(region_name=region)
tweet = Tweet(
twid=twid,
time=time,
text=text,
user=user,
disaster_tag=tag_d,
location=mark
)
tweet.save()
else: # 잘못 들어온 트윗은 저장X
pass
else: # 트윗 없음
pass트윗을 실시간으로 불러와서 모델에 저장해주어야 하기 때문에 서버가 실행중일때도 위에 짠 함수가 호출되어야 한다. 이 작업을 수행하기 위해서 BackgroundScheduler를 사용해주었다. 이 스케쥴러에 관한 자세한 내용은 다음 블로그를 참고해주면 된다. [Django] 서버 실행중에 함수 주기적으로 호출하기
서버를 실행해주면 아래와 같이 함수가 트윗을 실시간으로 불러오고 저장하는 함수가 잘 진행되는 것을 알수 있다.
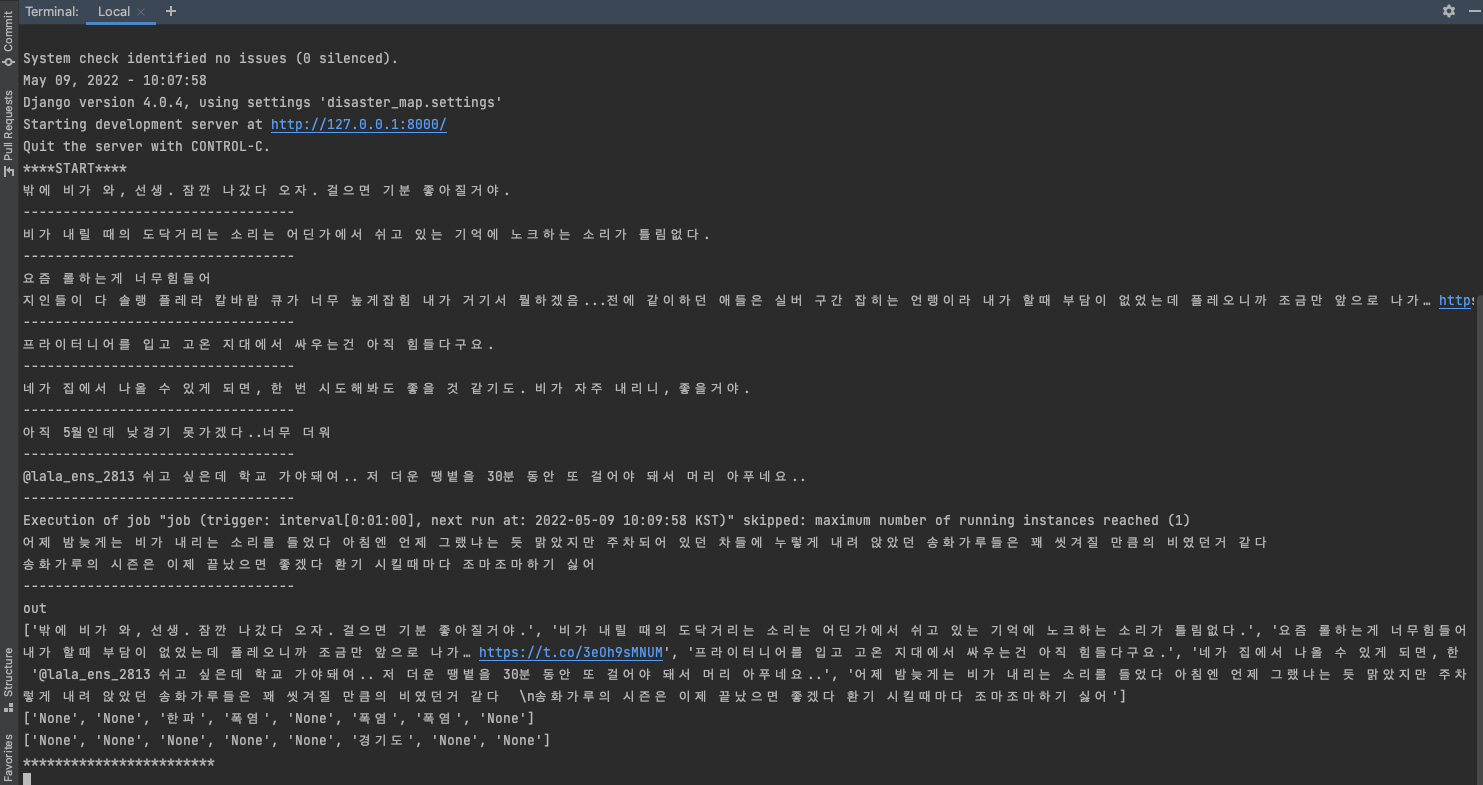
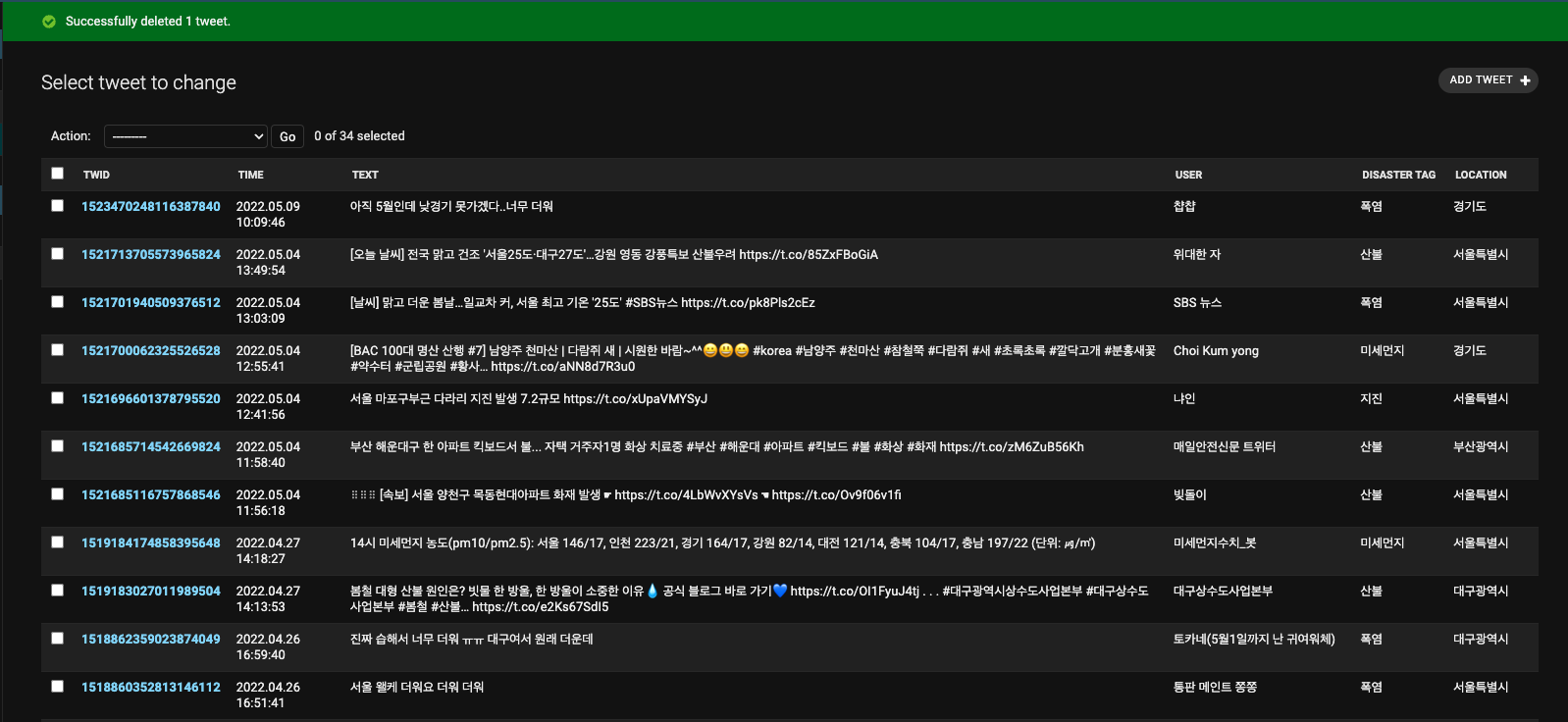
어느 정도 시간이 지나면 트윗이 모델에 쌓이고 저장되면 이제 어드민에 들어가서 확인해보면 트윗들이 잘 저장된 것을 볼 수 있다.
분류하기
# 트윗 지역과 자연재해별로 분류하기 (classify)
disasters, regions = classify_tweets(texts)위에서 이부분에서 트윗을 분류했는데 어떤 방식으로 분류했는지 간단하게 설명해보겠다.
우선은 mecab이라는 라이브러리를 설치해주어서 트윗을 형태소로 분석해주었다. 이부분에서 설치과정부터 분석하는 과정까지 굉장히 애를 먹었는데 어찌저찌해서 해결했다ㅜㅜㅜ그후에 지역에 해당하는 키워드들을 리스트로 만들었고 자연재해 역시 해당하는 키워드들을 리스트로 만들었다
queries_typhoon = ["태풍"] # 태풍
queries_downpour = ["폭우", "호우", "비 많", "비가", "장마"] # 호우/폭우
queries_snow = ["눈 많이", "폭설", "대설", "눈 쌓여"] # 폭설/대설
queries_forestfire = ["산불", "화재", "건조"] # 산불
# 생략...
region_seoul = ["서울", "서울특별시", "송파", "강서", "강남", "노원", "관악", "은평", "양천", "성북", "강동", "서초", "영등포"]
region_gyeoung = ["경기", "경기도", "수원", "고양", "용인", "성남", "부천", "화성", "남양주", "안산", "안양", "평택", "고양시"]
region_gang = ["강원", "강원도", "원주", "춘천", "강릉", "속초"]
region_chungbuk = ["충북", "충청북도", "청주", "충주"]
# 생략...그후에 트윗을 mecab으로 형태소별로 분석을 해서 해당하는 지역이나 자연재해와 일치하는게 있는지 일일히 코드로 비교해주었다. 굉장히 노가다적인 방식이지만 더 좋은 방법을 아직 못 찾았다ㅜㅜ
m = Mecab()
region_tag = "None"
disaster_tag = "None"
for w in m.pos(txt):
if w[0] in region_seoul:
region_tag = "서울특별시"
break
elif w[0] in region_gyeoung:
region_tag = "경기도"
break
elif w[0] in region_gang:
region_tag = "강원도"
break
elif w[0] in region_chungbuk:
region_tag = "충청북도"
break
elif w[0] in region_chungnam:
region_tag = "충청남도"코드를 짜면서 분석하는게 제일 어렵고 헷갈렸던것 같다. 여기서 조금만 더 깊게 가면 이제 데이터분석쪽 영역이라 너무 어려워질 것 같아서 여기서 트윗을 분류하는것까지만 하기로 했다. 아직 데이터 분석쪽은 경험이 없어서 나중에 꼭 한번 경험해보고 싶다.
