우선 트위터 크롤링하기 위해서는 시크릿 키들이 몇개 필요하다 이전까지는 키 발급 받는 절차가 굉장히 까다로웠던것 같은데 최근들어 간소화 되었다. 나는 트위터 개발자 등록하기 블로그를 통해서 트위터에서 개발자 등록후 크롤링을 진행하였다.
1. 파이썬 라이브러리 설치
pip install python-twitter2. 발급받은 트위터 시크릿 키 설정해주기
twitter_consumer_key = ""
twitter_consumer_secret = ""
twitter_access_token = ""
twitter_access_secret = ""외부에 노출되면 안되는 키들이기 때문에 깃허브에 올리기 전에 env파일을 생성해준후 거기에 넣어서 숨겨주었다.
3. 트위터 연결하기
from pathlib import Path
import os
import environ
BASE_DIR = Path(__file__).resolve().parent.parent
env = environ.Env(
DEBUG=(bool, False)
)
environ.Env.read_env(os.path.join(BASE_DIR, '.env'))
# main code start
import twitter, time
# twitter api connect
twitter_consumer_key = env('twitter_consumer_key')
twitter_consumer_secret = env('twitter_consumer_secret')
twitter_access_token = env('twitter_access_token')
twitter_access_secret = env('twitter_access_secret')
twitter_api = twitter.Api(consumer_key=twitter_consumer_key,
consumer_secret=twitter_consumer_secret,
access_token_key=twitter_access_token,
access_token_secret=twitter_access_secret)
여기까지 설정해주면 트위터랑 아주 연결이 잘 된거다!!
4. 특정 계정의 타임라인 긁어오기
account = "@bts_bighit"
timeline = twitter_api.GetUserTimeline(screen_name=account, count=200, include_rts=True, exclude_replies=False)
print(timeline)방탄소년단 타임라인을 긁어오겠다
이때 최대로 가져올 수 있는 개수, 리트윗이나 답글을 포함할 것인지 여부 등을 지정할 수 있다. 출력해보면 여러 데이터들이 함께 출력될것이다. 이때 텍스트만 출력하고 싶으면 timeline.text 해주면 된다.
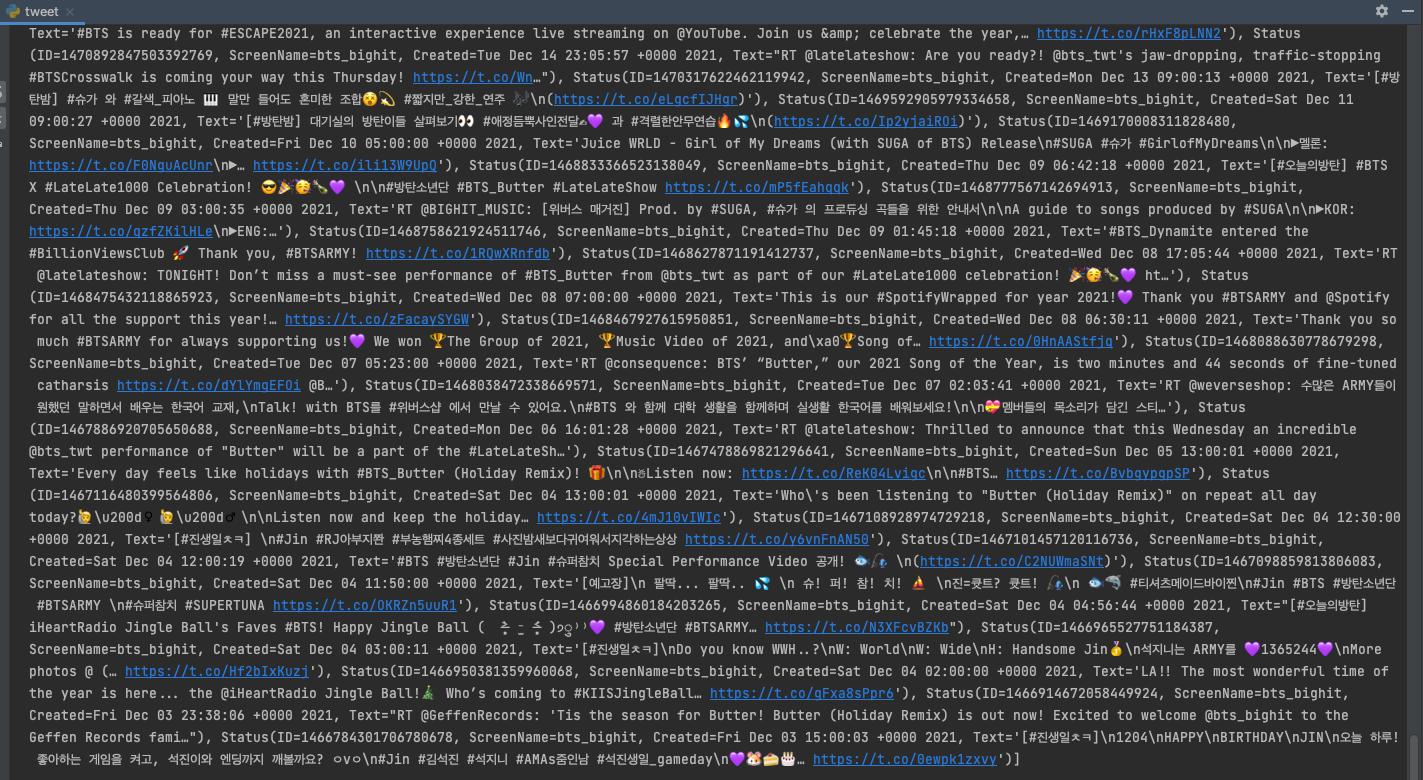
너무 많아서 다는 캡쳐하지 못했다ㅜㅜ하지만 아주 잘 작동된다.
5. 검색하기
query = "방탄소년단"
search = twitter_api.GetSearch(term=query, count=100)
for i in search:
print(i.text) # 텍스트만 출력하기역시나 방탄소년단에 관해서 검색을 했다. 개수는 백개까지만 검색하도록 제한했다. 검색어 문자열로 해시태그를 넣어도 된다.
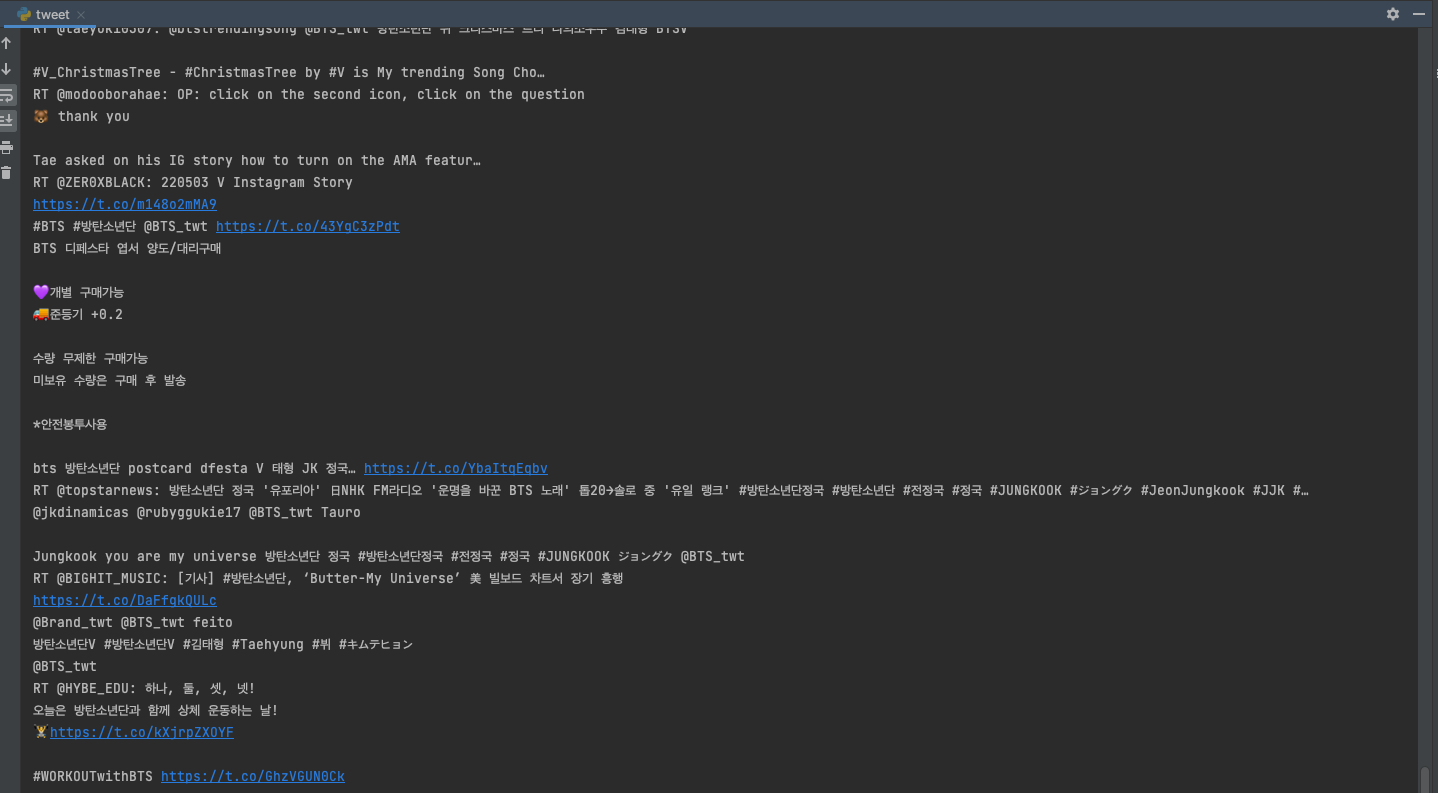
방탄소년이 포함된 텍스트들만 잘 출력되었다.
6. 스트리밍
특정 키워드를 지정해놓으면, 그 키워드가 포함된 트윗을 “실시간”으로 수집하는 거다.
query = ["방탄소년단"]
stream = twitter_api.GetStreamFilter(track=query)
for tweet in stream:
print(tweet)
저대로 출력했다가 너무 많이 수집돼서 정신없어서 텍스트만 출력하는 걸로 바꿔줬다.
for tweet in stream:
print(tweet['text']) 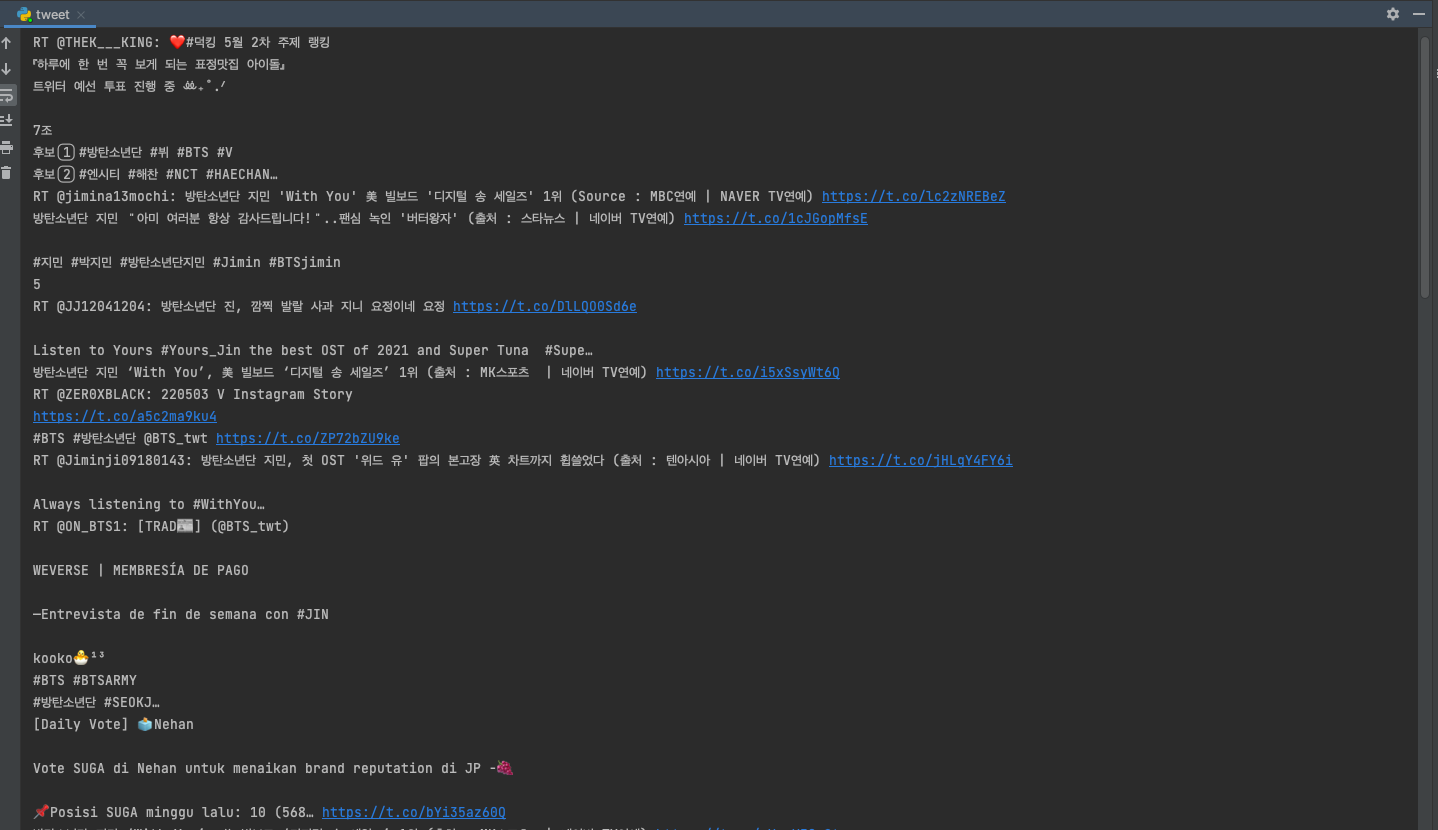
깔끔하다!! 끝!!

해당 기능은 현재 basic 계정만 이용가능한거겠죠...?