
CSAPP 책은 쌩으로 읽는다면 이해하기 매우 어렵습니다.
따라서 소단원만 그대로 따라가되, 내용을 이해하기 쉽게 재구성했습니다.
9.9.6 묵시적 가용 리스트
1. 모든 실용적인 할당기의 기본 조건
모든 실용적인 할당기는 다음 두 가지 조건을 만족해야 한다.
- 블록의 경계를 표시할 수 있어야 한다.
- 할당된 블록과 free 블록을 구분할 수 있어야 한다.
이 정보를 관리하기 위해, 대부분의 할당기는 이 정보를 블록 안에 직접 저장한다.
이는 블록 앞에 header를 붙임으로써 가능하다.
2. 블록의 구성
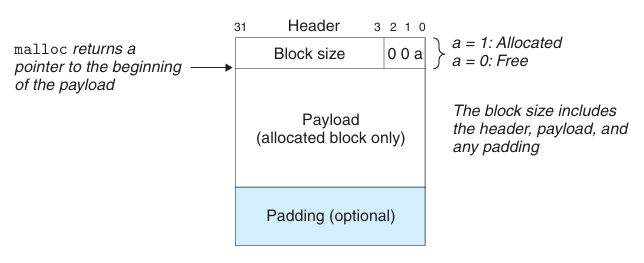
위 그림에서 블록은 크게 3부분으로 구성되어 있다.
- header: 블록 크기와 사용 여부 같은 메타정보를 담는다.
- payload: 프로그램이 실제로 사용하는 공간이다.
- padding: 정렬을 맞추기 위해 넣는 빈 공간이다.
하나씩 알아보자.
1) header
헤더는 블록의 핵심이다.
헤더는 1) 블록의 크기와 2) 할당 여부를 저장한다.
만약 double-word 정렬(8바이트 정렬) 제약을 걸었다고 가정해보자.
이때 블록 크기는 항상 8의 배수가 될 것이다.
64비트 시스템에서는 주소나 크기를 8의 배수로 맞춰야 한다.
그래서 블록 크기는 항상 8, 16, 24, 32, ... 이렇게 나온다.
이렇게 8의 배수의 주소를 이진수로 나타내면, 맨 마지막 3비트는 무조건 0이 된다.
💡 왜 double-word 정렬에서 마지막 3비트는 항상 0일까?
8의 배수인 수들을 이진수로 나타내보자.
8 →1000
16 →10000
24 →11000
32 →100000
항상 맨 끝 3자리가 0이다. ()
따라서 블록 크기를 저장할 때, 상위 29비트만 사용하면 된다.
이때 남는 3비트는 다른 정보를 저장하는 데 사용할 수 있다.
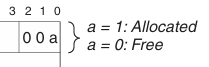
사진을 보면 블록 크기를 제외하고 남는 3비트가 있다.
이 중 맨 마지막 1비트(a)를 사용해서 할당 여부를 표시하는 데 사용할 수 있다.
(1이면 할당됨, 0이면 비어있음)
(1) 할당된 블록이 24바이트이다.
24바이트는 16진수로
0x18이다.
여기에 할당 표시인 1을 붙여서,0x18|0x1=0x19
그래서 헤더 값은0x19가 된다.
(2) free 블록이 40바이트라고 가정해보자.
40바이트는 16진수로
0x24이다.
비어있으므로 0을 붙여서,0x28|0x0=0x28
그래서 헤더 값은 그대로0x28이다.
2) payload
payload는 프로그램이 malloc을 호출해서 실제로 요청한 데이터 공간이다.
헤더 바로 뒤에 위치한다.
3) padding
payload 뒤에는 상황에 따라 빈 공간인 padding이 올 수 있다.
padding이 필요한 이유는 여러 가지 있다.
-
외부 단편화를 줄이기 위해
외부단편화란 필요한 만큼 연속된 빈 공간이 없는 문제이다.
패딩을 넣어서 블록 크기를 비슷하게 맞춰주면 단편화를 줄일 수 있다. -
메모리 정렬을 맞추기 위해
padding을 사용함으로써 CPU가 빠르게 읽는 8바이트 경계에 맞출 수 있다.
3. 묵시적 가용 리스트
1) 묵시적 가용 리스트
묵시적 가용 리스트를 이해하기 위해 먼저 아래 그림을 설명하겠다.

여기서 각각의 블록은 header + payload로 되어 있다.
또한, '사용 중인 블록(파란색)', '비어 있는 블록'(흰색), '사용 중인 블록', '비어 있는 블록'... 이런 식으로 이어진다.
이 구조를 묵시적 가용 리스트(implicit free list)라고 부른다.
첫번째 블록에서 헤더는 8/0이다.
이때 8은 블록의 전체 크기(즉, 헤더 포함 8바이트)를, 0은 free 상태임을 알려준다.
이를 통해 첫번째 블록은 8바이트짜리 free 블록임을 알 수 있다.
두번째 블록의 위치는 어떻게 될까?
첫 블록이 8바이트이므로, 8칸 뒤로 가면 두번째 블록에 도착할 수 있다.
이걸 통해서 포인터를 사용하지 않고도, 헤더의 크기 정보를 통해 자동으로 다음 블록을 알 수 있다.
이렇게 포인터 없이 블록을 연결하는 구조를 묵시적 가용 리스트라고 한다.
묵시적 가용 리스트에서 할당기는 힙 안에 있는 모든 블록을 차례대로 흝으면서 free 블록들을 간접적으로 찾을 수 있다.
2) 끝 블록
힙 끝에는 특별히 표시된 끝 블록이 필요하다.
끝 블록은 할당표시가 되어있고, 크기는 0인 헤더를 사용한다.
이런 표시를 통해서 가용 블록을 합치는 것(coalescing)이 더 쉬워진다.
3) 묵시적 가용 리스트의 장단점
묵시적 가용 리스트의 장점은 바로 단순함이다.
별도의 포인터 관리를 할 필요도 없고, 그저 배열처럼 쭉 나열하기만 하면 되니 구현이 간단하기도 하다.
하지만 단점도 있다.
새 블록을 찾는 작업(예: malloc할 때 어디에 넣을지 찾기)이 필요할 때, 힙에 존재하는 블록 수에 비례해서 시간이 오래 걸린다.
4. 블록의 최소 크기
메모리를 요청할 때, 요청한 크기가 아무리 작더라도 블록의 최소 크기는 정해져있다.
시스템 정렬을 맞춰야 하기 때문이다.
이로 인해 할당된 블록이든 free 블록이든, 최소 크기보다 작을 수는 없다.
만약 double word(8바이트) 정렬을 요구한다면, 각 블록의 크기는 항상 8의 배수여야 한다.
따라서 최소 블록 크기는 header 8바이트와 payload 8바이트를 합쳐서 총 16바이트가 된다.
심지어 프로그램이 1바이트만 요청하더라도, 할당기는 정렬 규칙을 맞추기 위해 16바이트짜리 블록을 만들어야 한다.
연습문제 9.6
1. 문제

다음의 malloc 요청 배열의 결과를 얻는 블록의 크기와 헤더 값을 결정하시오.
가정: (1) 할당기는 더블 워드 정렬을 유지하며, 그림 9.35의 블록 포맷을 갖는 묵시적 가용 리스트를 사용한다. (2) 블록 크기들은 인접 8바이트의 배수로 반올림한다.
2. 문제 풀이
-
블록의 크기
그림 9.35를 보면, 힙 블록은 헤더(header) + 페이로드(payload)로 구성되어 있다.
헤더는 항상 4바이트(32비트) 크기를 가진다.
malloc(n)을 요청하면 n바이트(payload)를 저장하기 위한 공간과, 4바이트(header)를 합친 크기가 필요하다.
정렬 조건에 의해 합산한 크기는 항상 8바이트의 배수가 되어야 한다.
따라서 합산 후 8바이트 단위로 반올림하여 최종 블록 크기를 구한다. -
헤더 값
모든 요청은 malloc을 통한 "할당된 블록"이므로 최종 블록 크기를 16진수로 변환한다.
이후 할당 비트 0x1을 OR 연산하여 헤더 값을 계산한다.
1) malloc(2)
-
블록의 크기
2바이트(payload) + 4바이트(header) = 6바이트
6바이트를 8바이트 단위로 반올림 → 8바이트 -
헤더 값
8바이트 = 0x8 (16진수)
0x8 | 0x1 = 0x9
2) malloc(9)
-
블록의 크기
9바이트(payload) + 4바이트(header) = 13바이트
13바이트를 8바이트 단위로 반올림 → 16바이트 -
헤더 값
16바이트 = 0x10
0x10 | 0x1 = 0x11
3) malloc(15)
-
블록의 크기
15바이트(payload) + 4바이트(header) = 19바이트
19바이트를 8바이트 단위로 반올림 → 24바이트 -
헤더 값
24바이트 = 0x18
0x18 | 0x1 = 0x19
4) malloc(20)
-
블록의 크기
20바이트(payload) + 4바이트(header) = 24바이트
(이미 8바이트 정렬되어 있음) -
헤더 값
24바이트 = 0x18
0x18 | 0x1 = 0x19
3. 정답
| Request | Block Size | Block Header |
|---|---|---|
| malloc(2) | 8 | 0x9 |
| malloc(9) | 16 | 0x11 |
| malloc(15) | 24 | 0x19 |
| malloc(20) | 24 | 0x19 |
