
1. 명시적 가용 리스트 사용하기
1) 왜 명시적 가용 리스트를 사용하는가?
처음에는 묵시적 가용 리스트를 사용해 할당기를 구현했다.
하지만 thru 점수가 14/40점에 그쳤다.
따라서 성능을 향상시키기 위해 가장 먼저 고려할 부분은 할당기의 속도를 높이는 것이었다.
묵시적 가용 리스트의 가장 큰 단점은 탐색 속도다.
힙 전체 블록을 순차적으로 훑으며 블록을 찾기 때문에, 탐색 시간은 힙의 전체 블록 수에 비례한다.
반면, 명시적 가용 리스트를 사용하면 가용 블록만 별도로 연결하여 관리할 수 있어, 탐색 시간은 가용 블록 수에만 비례한다.
그렇기에 묵시적 가용 리스트에서 명시적 가용 리스트로 바꾸는 작업을 수행했다.
2) 명시적 가용 리스트의 구조
명시적 가용 리스트는 free 블록의 payload 공간을 활용하여 가용 리스트를 구성한다.
free 블록은 payload를 실제 데이터 용도로 사용하지 않기 때문에, 이 공간에 다음과 이전 가용 블록을 가리키는 포인터(pred, succ)를 저장할 수 있다.
이를 통해 이중 연결 리스트 형태로 가용 블록들을 효율적으로 관리할 수 있다.
3) 명시적 가용 리스트를 구현하는 두 가지 방법
명시적 가용 리스트를 구현하는 방식에는 대표적으로 두 가지가 있다.
(1) LIFO 방식
가장 최근에 해제된 블록을 가용 리스트의 맨 앞에 삽입하는 방식이다.
여기에 first-fit 전략과 경계 태그(boundary tag)를 함께 사용하면, 빠른 탐색과 상수 시간으로 병합이 가능하다.
다만, LIFO 방식은 최근 해제된 블록이 반복해서 재사용되기 때문에, 메모리 전체의 활용이 고르지 못할 수 있다.
이로 인해 단편화가 심해지고 메모리 점수가 낮아질 가능성이 있다.
(실제로 메모리 점수가 44점에서 42점으로 떨어졌다.)
하지만 시간을 줄이는 것이 급선무이기에 LIFO 방식을 사용한다.
(2) 주소 순서 방식
가용 리스트를 메모리 주소 순서대로 정렬하여 유지하는 방식이다.
이 방식은 병합 과정에서 앞뒤 블록을 쉽게 찾을 수 있어, coalescing의 효율이 높고 메모리 활용률도 높다.
LIFO보다 탐색은 다소 느릴 수 있지만, 전체적인 메모리 점수가 개선될 가능성이 크다.
따라서 명시적 가용 리스트 + LIFO + First fit을 사용해서 작성했다.
2. 구현하기
1) mm.c 전체 코드
mm.c의 전체 코드는 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include "mm.h"
#include "memlib.h"
/*********************************
* 팀 정보
**********************************/
team_t team = {
/* 개인 정보 주석 처리 */
};
/*********************************
* 정렬 및 크기 관련 매크로
**********************************/
#define ALIGNMENT 8 // 8바이트 정렬 기준
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7) // size를 8바이트 배수로 올림
#define SIZE_T_SIZE (ALIGN(sizeof(size_t))) // size_t 크기도 8바이트 정렬
#define WSIZE 4 // 워드 크기 (헤더/풋터 크기)
#define DSIZE 8 // 더블 워드 크기 (기본 블록 단위)
#define CHUNKSIZE (1 << 12) // 힙 확장 단위: 4KB
#define MAX(x, y) ((x) > (y) ? (x) : (y)) // 두 값 중 큰 값 반환
/*********************************
* 헤더/풋터 및 포인터 접근 매크로
**********************************/
#define PACK(size, alloc) ((size) | (alloc)) // 블록의 크기와 할당 여부를 하나의 워드로 결합
#define GET(p) (*(unsigned int *)(p)) // 주소 p에 저장된 값을 읽음
#define PUT(p, val) (*(unsigned int *)(p) = (val)) // 주소 p에 val 값을 저장
#define GET_SIZE(p) (GET(p) & ~0x7) // p에 저장된 블록 크기 추출 (하위 3비트 제외)
#define GET_ALLOC(p) (GET(p) & 0x1) // p에 저장된 할당 여부 추출 (하위 1비트)
#define HDRP(bp) ((char *)(bp) - WSIZE) // 블록 포인터 bp의 헤더 주소
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) // bp의 풋터 주소
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) // 다음 블록의 bp
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) // 이전 블록의 bp
// 명시적 가용 리스트에서 pred와 succ 포인터 접근
#define PRED(bp) ((char *)(bp)) // pred는 payload 첫 워드
#define SUCC(bp) ((char *)(bp + WSIZE)) // succ는 payload 두 번째 워드
/*********************************
* 전역 변수
**********************************/
static char *heap_listp = NULL; // 프롤로그 블록의 payload 포인터
static char *free_listp = NULL;
/*********************************
* 내부 함수 선언
**********************************/
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t asize);
static void place(void *bp, size_t asize);
/*
* mm_init - 초기 힙 생성 및 가용 리스트 초기화
*/
int mm_init(void)
{
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *) -1) {
return -1; // 초기 힙 공간 요청 실패 시 -1 반환
}
PUT(heap_listp, 0); // 패딩 워드
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 풋터
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 헤더
heap_listp += (2 * WSIZE); // payload 기준으로 이동
free_listp = NULL;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) { // 초기 힙 확장 실패 시
return -1;
}
return 0; // 성공적으로 초기화 완료
}
/*
* extend_heap - 힙을 확장하고 새 가용 블록 생성
*/
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE; // 짝수 워드로 정렬
if ((long)(bp = mem_sbrk(size)) == -1) {
return NULL; // 힙 확장 실패 시 NULL 반환
}
PUT(HDRP(bp), PACK(size, 0)); // 새 블록 헤더 설정 (free)
PUT(FTRP(bp), PACK(size, 0)); // 새 블록 풋터 설정 (free)
PUT(PRED(bp), 0); // pred 초기화
PUT(SUCC(bp), 0); // succ 초기화
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 새 에필로그 헤더
return coalesce(bp); // 인접 블록 병합 후 반환
}
/*
* find_fit - first-fit 방식으로 적절한 가용 블록 찾기
*/
static void *find_fit(size_t asize)
{
char *bp = free_listp; // 가용 리스트 순회 시작점
while (bp != NULL) {
if (GET_SIZE(HDRP(bp)) >= asize) { // 요청 크기 만족 시 반환
return bp;
}
bp = GET(SUCC(bp)); // 다음 블록으로 이동
}
return NULL; // 적절한 블록 없으면 NULL
}
/*
* place - 요청 크기만큼 블록을 할당, 잔여 공간은 분할
*/
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록 크기
del_block(bp); // 가용 리스트에서 제거
if ((csize - asize) >= (2 * DSIZE)) { // 분할 가능하면
PUT(HDRP(bp), PACK(asize, 1)); // 앞쪽 블록 할당
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp); // 남은 블록 처리
PUT(HDRP(bp), PACK(csize - asize, 0)); // 남은 블록 헤더
PUT(FTRP(bp), PACK(csize - asize, 0)); // 남은 블록 풋터
PUT(PRED(bp), 0);
PUT(SUCC(bp), 0);
coalesce(bp); // 남은 블록 병합 시도
} else {
PUT(HDRP(bp), PACK(csize, 1)); // 전체 블록 할당
PUT(FTRP(bp), PACK(csize, 1));
}
}
/*
* mm_malloc - 요청한 크기의 블록을 할당
*/
void *mm_malloc(size_t size)
{
size_t asize; // 실제 할당할 블록 크기 (조정된 크기)
size_t extendsize; // 힙을 확장해야 할 경우 그 크기
char *bp; // 할당할 블록의 포인터
if (size == 0) { // 요청 크기가 0이면 NULL 반환
return NULL;
}
if (size <= DSIZE) { // 요청 크기가 DSIZE 이하면 최소 블록 크기(16바이트)로 설정
asize = 2 * DSIZE;
} else {
// 그 이상이면 8의 배수로 올림하여 조정된 크기 계산
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
}
if ((bp = find_fit(asize)) != NULL) { // 가용 리스트에서 적절한 블록 탐색 (first-fit)
place(bp, asize); // 찾은 블록에 메모리 배치
return bp; // 할당된 블록 포인터 반환
}
extendsize = MAX(asize, CHUNKSIZE); // 적당한 블록이 없으면 힙 확장 필요
if ((bp = extend_heap(extendsize / WSIZE)) == NULL) { // 힙 확장 실패 시 NULL 반환
return NULL;
}
place(bp, asize); // 새로 확장된 블록에 메모리 배치
return bp; // 할당된 블록 포인터 반환
}
/*
* mm_free - 블록을 해제하고 병합 시도
*/
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록의 크기 가져오기
PUT(HDRP(bp), PACK(size, 0)); // 헤더에 free 표시
PUT(FTRP(bp), PACK(size, 0)); // 풋터에 free 표시
PUT(PRED(bp), 0); // pred 초기화 (가용 리스트 연결 전)
PUT(SUCC(bp), 0); // succ 초기화
coalesce(bp); // 인접 free 블록과 병합 시도
}
/*
* coalesce - 인접 free 블록과 병합
*/
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록의 할당 여부
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록의 할당 여부
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록의 크기
if (prev_alloc && next_alloc) { // Case 1: 앞뒤 모두 할당
// 아무 병합도 하지 않음
}
else if (prev_alloc && !next_alloc) { // Case 2: 뒤 블록만 free
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); // 뒤 블록 크기 합침
del_block(NEXT_BLKP(bp)); // 뒤 블록 가용 리스트에서 제거
PUT(HDRP(bp), PACK(size, 0)); // 병합된 헤더 설정
PUT(FTRP(bp), PACK(size, 0)); // 병합된 풋터 설정
}
else if (!prev_alloc && next_alloc) { // Case 3: 앞 블록만 free
size += GET_SIZE(HDRP(PREV_BLKP(bp))); // 앞 블록 크기 합침
del_block(PREV_BLKP(bp)); // 앞 블록 가용 리스트에서 제거
PUT(FTRP(bp), PACK(size, 0)); // 병합된 풋터 설정
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 병합된 헤더 설정
bp = PREV_BLKP(bp); // bp를 병합된 블록으로 이동
}
else { // Case 4: 앞뒤 모두 free
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp))); // 앞뒤 블록 크기 모두 합침
del_block(PREV_BLKP(bp)); // 앞 블록 가용 리스트에서 제거
del_block(NEXT_BLKP(bp)); // 뒤 블록 가용 리스트에서 제거
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 병합된 헤더 설정
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // 병합된 풋터 설정
bp = PREV_BLKP(bp); // bp를 병합된 블록으로 이동
}
put_block(bp); // 병합된 블록을 가용 리스트에 추가
return bp;
}
/*
* put_block - 가용 블록을 리스트 맨 앞에 삽입
*/
void put_block(char *bp)
{
char* succ = free_listp; // 현재 가용 리스트 첫 블록
if (succ != NULL) {
PUT(PRED(succ), bp); // 기존 첫 블록의 pred를 새 블록으로 설정
}
PUT(SUCC(bp), succ); // 새 블록의 succ 설정
PUT(PRED(bp), 0); // 새 블록의 pred는 NULL
free_listp = bp; // 새 블록을 가용 리스트 첫 블록으로 설정
}
/*
* del_block - 가용 블록을 리스트에서 제거
*/
void del_block(char *bp)
{
if (GET(PRED(bp)) == 0) { // pred가 NULL이면 첫 번째 블록
if (GET(SUCC(bp)) != NULL) {
PUT(PRED(GET(SUCC(bp))), 0); // succ의 pred를 NULL로
}
free_listp = GET(SUCC(bp)); // free_listp 갱신
} else {
if (GET(SUCC(bp)) != NULL) {
PUT(PRED(GET(SUCC(bp))), GET(PRED(bp))); // succ의 pred 연결
}
PUT(SUCC(GET(PRED(bp))), GET(SUCC(bp))); // pred의 succ 연결
}
PUT(SUCC(bp), 0); // 자신 초기화
PUT(PRED(bp), 0);
}
/*
* mm_realloc - 블록을 재할당
*/
void *mm_realloc(void *bp, size_t size)
{
if (size <= 0) { // 요청 크기가 0이면
mm_free(bp); // 기존 블록 해제 후
return NULL; // NULL 반환
}
if (bp == NULL) { // bp가 NULL이면
return mm_malloc(size); // malloc으로 동작
}
void *newbp = mm_malloc(size); // 새로운 블록 할당
if (newbp == NULL) { // 할당 실패 시
return NULL; // NULL 반환
}
size_t oldsize = GET_SIZE(HDRP(bp)); // 기존 블록 크기
if (size < oldsize) { // 요청 크기가 더 작으면
oldsize = size; // 복사 크기 조정
}
memcpy(newbp, bp, oldsize); // 데이터를 새 블록으로 복사
mm_free(bp); // 기존 블록 해제
return newbp; // 새 블록 포인터 반환
}다른 분의 코드를 많이 참고해서 작성했다.
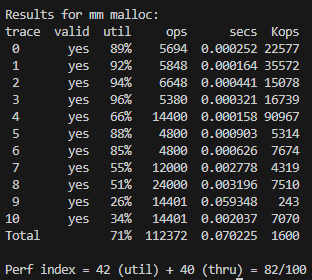
2) 점수
위 코드를 돌리면 나오는 점수는 다음과 같다.
(명시적 가용 리스트 + LIFO + First Fit)
3. Malloc Lab 후기
오랫동안 개념 공부에 집중했기에, 명시적 가용 리스트로 할당기를 구성하는 원리는 완벽히 이해하고 있다고 생각했다.
그러나 실제로 구현을 해보니, 함수들이 유기적으로 연결되는 부분이 너무나도 헷갈렸다.
각 함수들의 역할을 분명히 알고 있었음에도 막상 구현을 하려니 막막했다.
단순한 이해와 실제 구현 사이에는 큰 간극이 존재했다.
이 과정에서 문득 정처기 공부 당시 배운 SOLID 원칙이 떠올랐다.
(물론 C는 객체지향 언어가 아니다.)
의미는 약간 다르지만, 단일 책임 원칙(Single Responsibility Principle)의 중요성이 절실히 느껴졌다.
각 함수가 명확한 하나의 역할만을 책임질 때, 함수를 사용하고 설계하는 데 거리낌이 없다.
또한 전체 흐름을 파악하는 데도 큰 도움이 된다.
예전에 재귀 함수를 처음 배웠을 때도 비슷한 감정을 느꼈었다.
당시 재귀함수를 개념적으로 분명히 이해했었는데, 실제로 사용하려니 구현이 불가능함을 느꼈었다.
그때의 막막했던 기억이 Malloc Lab으로 인해 다시금 떠올랐다.
그럼에도 시간이 넉넉했다라면, 여러 조합들을 시도하며 점수를 올리는 데 혈안이 되어 있었을 것 같다.
분리 가용 리스트나 버디시스템, 그리고 Next-fit, Best-fit 같은 방법들을 사용해보지 못한 게 아쉽다.
