
1. 스레드
1.1 프로세스
프로세스(process)란 간단히 말해서 ‘실행 중인 프로그램(program)’이다. 프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)를 할당받아 프로세스가 된다.
현재 우리가 사용하는 OS들(윈도우, 리눅스, 맥OS 등등..)은 모두 멀티태스킹을 지원한다. 멀티태스킹을 지원한다는 것은 여러 개의 프로세스를 동시에 실행할 수 있다는 것이다. 내가 블로그에 글을 쓰면서, 동시에 유튜브로 음악을 듣고, 인텔리제이를 실행할 수 있는 것은 모두 OS가 멀티태스킹을 지원하기 때문이다.
프로세스는 프로그램을 수행하는 데 필요한 데이터와 메모리 등의 자원(resources)과 쓰레드로 구성되어 있다. 프로세스의 자원을 이용해서 실제 작업을 수행하는 것이 바로 쓰레드이다.
하나의 프로세스는 하나 이상의 쓰레드를 가지며, 둘 이상의 쓰레드를 가진 프로세스를 '멀티쓰레드 프로세스(multi-threaded process)'라고 한다. 우리가 카카오톡이나 슬랙을 사용할 때, 상대가 전송한 파일을 다운로드하면서 동시에 채팅을 할 수 있는 것은 해당 프로그램이 멀티쓰레드로 작성되어 있기 때문이다.
1.2 멀티 스레딩
멀티쓰레딩은 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것이다.
CPU의 코어(core)가 한 번에 단 하나의 작업만 수행할 수 있으므로, 실제로 동시에 처리되는 작업의 개수는 코어의 개수와 일치한다. 그러나 처리해야 하는 쓰레드의 수는 항상 코어의 수보다 많기 때문에 각 코어가 짧은 시간 동안 여러 작업을 번갈아 가며 수행함으로써 여러 작업들이 모두 동시에 수행되는 것처럼 보이게 한다.
프로세스의 성능이 단순히 쓰레드의 개수에 비례하는 것은 아니며, 하나의 쓰레드를 가진 프로세스 보다 두 개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수도 있다.
1.2.1 멀티 스레딩 장단점
장점
- CPU의 사용률을 향상시킨다
- 자원을 보다 효율적으로 사용할 수 있다
- 작업이 분리되어 코드가 간결해진다.
단점
- 동기화(synchronization), 교착상태(deadlock) 과 같은 문제들을 고려해야한다
2. Java에서의 스레드
Java에서의 Thread api 주석을 확인하면 다음과 같이 설명되어 있다.
- 스레드는 하나의 프로그램에서의 실행 흐름이다.
- JVM은 병렬적으로 작동하는 여러개의 스레드 실행을 허용한다.
- 모든 스레드는 우선순위가 있다. 우선순위가 높은 스레드는 우선순위가 낮은 스레드보다 먼저 실행된다.
- 어떤 스레드는 데몬스레드가 되거나 되지 않을수 있다.
- 일부 스레드에서 실행중인 코드가 새 스레드 객체를 생성할 때, 새 스레드는 처음에 생성된 스레드의 우선순위와 동일하게 설정된 우선순위를 가지며, 생성스레드가 데몬인 경우에만 데몬스레드가 된다.
- JVM이 시작될 때 일반적으로 메인메서드의 호출로 발생한 단일 비데몬 스레드가 있다.
- JVM은 다음과 같은 상황이 발생할 때 까지 지속된다.
- Runtime 클래스의 exit() 메서드가 호출되고 security manager가 종료 조작을 허가한 경우.
- 데몬 스레드가 아닌 모든 스레드가 run()메서드의 호출로 return되었거나, run()메서드를 넘어서 전파되는 예외를 throw하여 죽은경우.
- 스레드는 두 가지의 실행방식이 있다. 첫 번째는 Thread 클래스의 서브클래스로 선언되는것이다. 이 서브클래스는 반드시 Thread클래스의 run()메서드를 오버라이딩 해야한다. 그런 다음에야 서브클래스의 인스턴스를 할당하고 시작할 수 있다.
- 그 후 인스턴스의 start()메서드를 호출하면 스레드를 실행할 수 있다.
- 또 다른 방법은 Runnable 인터페이스를 구현하는 클래스를 작성하는 것이다. 그 클래스는 run()메서드를 구현해야한다.
- 새로운 스레드의 인수로 Runnable인스턴스를 인자로 넘긴 후, 해당 스레드를 실행하면 스레드를 실행할 수 있다.
- 모든 스레드는 식별을 위한 이름이 있다.
- 둘 이상의 스레드가 동일한 이름을 가질 수 있다.
- 스레드가 생성될 때 이름이 지정되지 않으면 새 이름이 생성된다.
- 달리 명시되지 않는 한, 이 클래스의 생성자, 또는 메서드에 null 인수를 전달하면 NullPointerException이 throw된다.
2.1 Thread 클래스
클래스를 Thread의 자식 클래스로 선언하는 방법이다.
자식 클래스는 실행 메소드(run 메소드)를 재정의 해야한다.
그 다음 클래스의 인스턴스를 할당하고 실행할 수 있다.
public class ThreadDemo {
public static void main(String[] args) {
// 상속으로 구현
ThreadByInheritance thread1 = new ThreadByInheritance();
thread1.start();
}
}
class ThreadByInheritance extends Thread {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.print(0);
}
}
}2.1.1 Method 구성
- sleep()
- 시스템 타이머 및 스케줄러의 정밀도에 따라 현재 실행중인 스레드를 지정된 밀리초동안 휴면한다. 스레드는 모니터의 소유권을 잃지 않는다.
- yield()
- 현재 스레드가 프로세서의 현재 사용을 양보할 의사가 있다는 스케줄러에 대한 힌트이다. 보통 디버깅 또는 테스트 목적에 유용하다.
- clone() 불가능
- 클론이 불가능하다. 호출시 예외를 던진다.
- start()
- 스레드를 실행한다. 스레드를 두번 시작할 수 없고, 스레드가 실행 완료된 후에도 다시 시작할 수 없다.
- run()
- 스레드에 할당된 runnable을 실행한다.
- exit()
- 스레드가 실제로 종료되기 전에 정리할 기회를 주기 위해 시스템에 의해 호출된다.
- interrupt()
- 이 스레드를 중단한다.
- join()
- 해당 메서드가 죽을때까지 최대 파라미터ms만큼 기다린다.
- set/getPriority()
- 스레드의 우선순위 get/set한다.
- getState()
- 스레드의 상태를 get/set 한다.
2.2 Runnable 인터페이스
클래스를 Runnable 인터페이스를 구현하는 클래스로 선언하는 방법이다.
해당 클래스는 run() 메소드를 구현한 뒤 hread를 만들 때 인수로 전달하고 시작할 수 있다.
public class ThreadDemo {
public static void main(String[] args) {
//인터페이스로 구현
Runnable r = new ThreadByImplement();
Thread thread = new Thread(r); //생성자: Thread(Runnable target)
// 아래 코드로 축약 가능
// Thread thread2 = new Thread(new ThreadByImplement());
thread.start();
}
}
class ThreadByImplement implements Runnable {
@Override
public void run() {
for (int i = 0; i < 500; i++) {
System.out.print(1);
}
}
}Thread 클래스가 다른 클래스를 확장할 필요가 있을 경우에는 Runnable 인터페이스를 구현하면 되며, 그렇지 않은 경우는 Thread 클래스를 사용하는 것이 좋다.
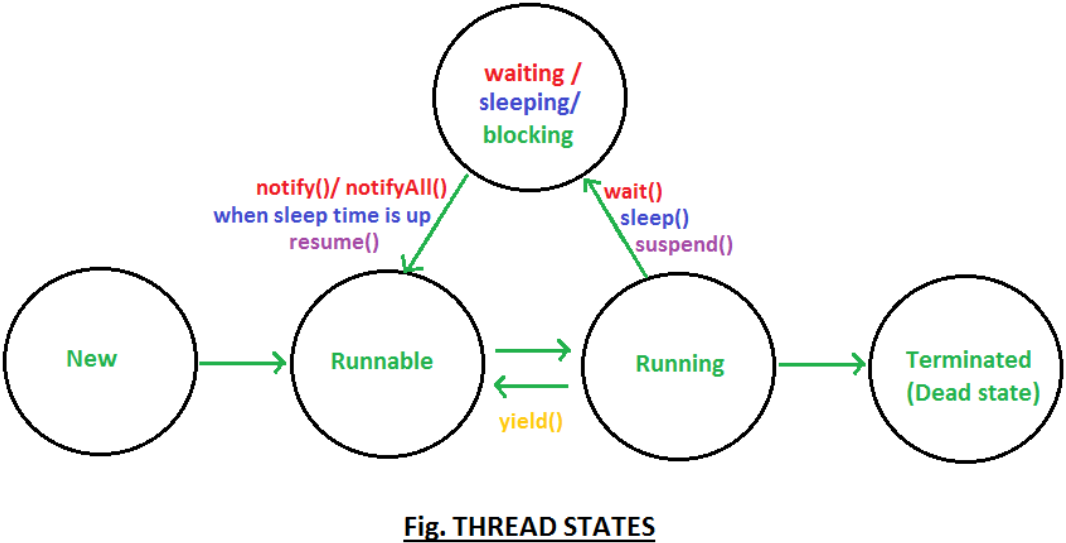
2.3 스레드 상태
스레드는 다음과 같은 상태중 하나를 가진다.
-
new
- 아직 시작하지 않은 상태
-
runnable
- jvm에서 실행중인 상태
-
blocked
- 모니터락을 기다리면서 블럭된 상태
-
waiting
- 다른 스레드가 특정 작업을 수행할 때까지 무기한 대기중인 상태
-
timed-waiting
- 다른 스레드가 지정된 대기시간까지 작업을 수행하기를 기다리는 상태
-
terminated
- 종료된 상태
2.4 start()와 run()
쓰레드를 실행하기 위해서는 start 메서드를 통해 해당 쓰레드를 호출해야 한다. start 메서드는 쓰레드가 작업을 실행할 호출 스택을 만들고 그 안에 run 메서드를 올려주는 역할을 한다.
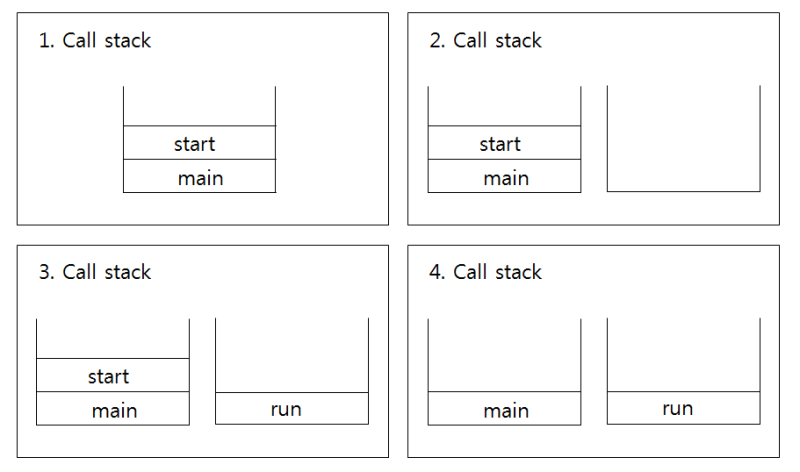
start를 호출하지 않고 run을 호출하면, 새로운 호출 스택이 생성되지 않기 때문에, 그냥 한 메서드 안에서 코드를 실행하는 것과 같다.
2.5 스레드 우선순위
쓰레드는 우선순위(priority)라는 멤버 변수를 갖고 있다.
각 쓰레드별로 우선순위를 다르게 설정해줌으로써 어떤 쓰레드에 더 많은 작업 시간을 부여할 것인가를 설정해줄 수 있다.
우선순위는 1 ~ 10 사이의 값을 지정해줄 수 있으며 기본값으로 5가 설정되어 있고 높을 수록 우선순위가 높다.
public class Thread implements Runnable {
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경한다.
int getPriority() // 쓰레드의 우선순위를 반환한다.
public static final int MIN_PRIORITY = 1; // 최소 우선순위
public static final int NORM_PRIORITY = 5; // 보통 우선순위
public static final int MAX_PRIORITY = 10; // 최대 우선순위
}setPriority 메서드는 쓰레드를 실행하기 전에만 호출할 수 있다.
그런데 주의할 점은 이것이 반드시 보장되는 것은 아니다. 쓰레드의 작업 할당은 OS의 스케쥴링 정책과 JVM의 구현에 따라 다르기 때문에 코드에서 우선순위를 지정하는 것은 단지 희망사항을 전달하는 것일 뿐, 실제 작업은 내가 설정한 우선 순위와 다르게 진행될 수 있다.
2.6 Main 스레드
public static void main(String args[]){
System.out.println("Hello World!")
}Java는 main 메소드를 통해서 실행하게 된다. main 쓰레드는 프로그램이 시작하면 가장 먼저 실행되는 쓰레드이며, 모든 쓰레드는 main 쓰레드로부터 생성된다.
이를 싱글 스레드라고도 하는데 메인 쓰레드가 종료 되면, 프로세스 자체도 종료된다. 이런 메인 쓰레드 구조에서 작업 쓰레드를 여러개 생성하여, 멀티 쓰레드를 구성 할 수 있다.
쓰레드는 '사용자 쓰레드(user thread)'와 '데몬 쓰레드(daemon thread)'로 구분되는데, 실행 중인 사용자 쓰레드가 하나도 없을 때 프로그램이 종료된다.
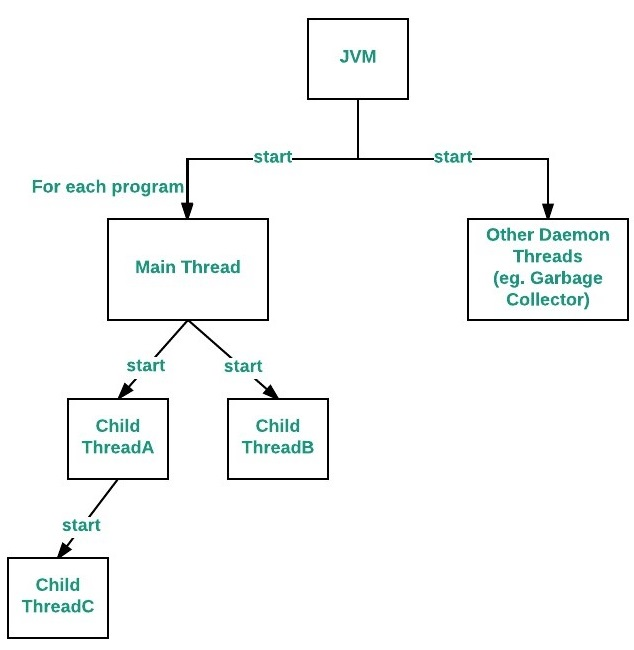
2.7 데몬 쓰레드
데몬 쓰레드는 main 쓰레드를 보조하는 쓰레드를 이야기 한다. 보조를 하는 역할 이기 때문에, 메인쓰레드가 종료되면 데몬 쓰레드도 강제적으로 종료된다.
public static void main(String[] args) {
Thread th = new ThreadExample();
th.setDaemon(true); // 데몬쓰레드들로 만들기.
th.start();
}3. 동기화(Synchronize)
여러 개의 쓰레드가 한 개의 리소스를 사용하려고 할 때 사용 하려는 쓰레드를 제외한 나머지들을 접근하지 못하게 막는 것이다.
자바에서 동기화 하는 방법은 3가지로 분류된다
- Synchronized 키워드
- Atomic 클래스
- Volatile 키워드
3.1 Synchronized
- Java 예약어 중 하나이다
- 변수명이나, 클래스명으로 사용이 불가능하다
public class CommonCalculate {
private int amount;
public CommonCalculate() {
amount=0;
}
public synchronized void plus(int value) {
amount += value;
}
public void minus(int value) {
synchronized (this){
amount -= value;
}
}
}위와 같이 method 수준, 코드 레벨 수준에서 동기화 작업이 가능하다.
3.2 Atomic
- Atomicity(원자성)의 개념은 '쪼갤 수 없는 가장 작은 단위'를 뜻한다
- 자바의 Atomic Type은 Wrapping 클래스의 일종으로, 참조 타입과 원시 타입 두 종류의 변수에 모두 적용이 가능하다. 사용시 내부적으로 CAS(Compare-And-Swap) 알고리즘을 사용해 lock 없이 동기화 처리를 할 수 있다.
- Atomic Type경우 volatile과 synchronized 와 달리 java.util.concurrent.atomic 패키지에 정의된 클래스이다
- CAS는 특정 메모리 위치와 주어진 위치의 value를 비교하여 다르면 대체하지 않는다.
- 사용법은 변수를 선언할때 타입을 Atomic Type으로 선언해주면된다
public class AtomicTypeSample {
public static void main(String[] args) {
AtomicLong atomicLong = new AtomicLong();
AtomicLong atomicLong1 = new AtomicLong(123);
long expectedValue = 123;
long newValue = 234;
System.out.println(atomicLong.compareAndSet(expectedValue,newValue));
atomicLong1.set(234);
System.out.println(atomicLong1.compareAndSet(234,newValue));
System.out.println(atomicLong1.compareAndSet(expectedValue,newValue));
System.out.println(atomicLong.get());
System.out.println(atomicLong1.get());
}
}>>>false
>>>true
>>>false
>>>0
>>>2343.2.1 주요 Class
- AtomicBoolean
- AtomicInteger
- AtomicLong
- AtomicIntegerArray
- AtomicDoubleArray
3.2.2 주요 Method
- get()
- 현재 값을 반환
- set(newValue)
- newValue로 값을 업데이트한다
- getAndSet(newValue)
- 원자적으로 값을 업데이트하고 원래의 값을 반환한다
- CompareAndSet(expect, update)
- 현재 값이 예상하는 값(=expect)과 동일하다면 값을 update 한 후 true를 반환한다. 예상하는 값과 같지 않다면 update는 생략하고 false를 반환
- Number 타입의 경우 값의 연산을 할 수 있도록 addAndGet(delta), getAndAdd(delta), getAndDecrement(), getAndIncrement(), incrementAndGet() 등의 메소드를 추가로 제공
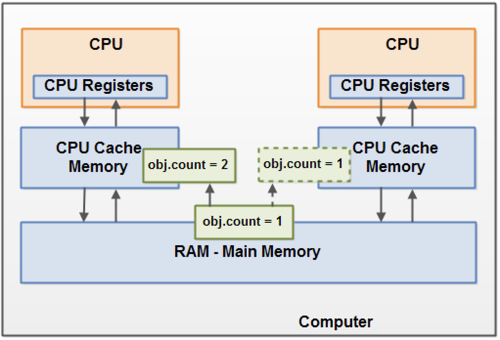
3.2.3 Compare-And-Swap(CAS)란?
- 메모리 위치의 내용을 주어진 값과 비교하고 동일한 경우에만 해당 메모리 위치의 내용을 새로 주어진 값으로 수정을 한다
- 즉, 현재 주어진 값(= 현재 쓰레드에서의 데이터)과 실제 데이터와 저장된 데이터를 비교해서 두 개가 일치할때만 값을 업데이트 한다. 이 역할을 하는 메서드가 compareAndSet() 이다. 즉 , synchronized 처럼 임계영역에 같은 시점에 두개 이상의 쓰레드가 접근하려 하면 쓰레드 자체를 blocking 시키는 메커니즘이 아니다.
3.3 Volatile
volatile keyword 는 Java 변수를 Main Memory에 저장하겠다라는 것을 명시하는것이다.
매번 변수의 값을 Read할 때마다 CPU cache에 저장된 값이 아닌 Main Memory에서 읽는다. 또한 변수의 값을 Write할 때마다 Main Memory 에 까지 작성한다.
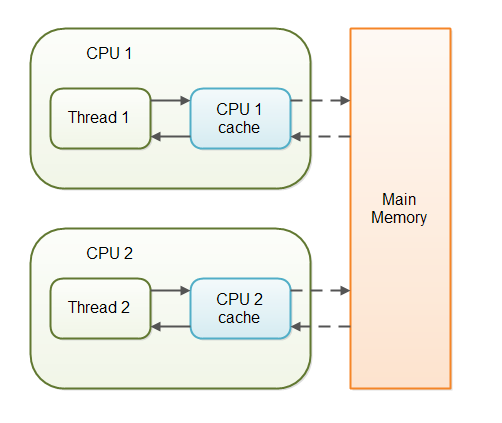
volatile 변수를 사용하고 있지 않는 MultiThread 애플리케이션은 작업을 수행하는 동안 성능 향상을 위해서 Main Memory에서 읽은 변수를 CPU Cache에 저장하게 된다
만약 Multi Thread환경에서 Thread가 변수 값을 읽어올 때 각각의 CPU Cache에 저장된 값이 다르기 때문에 변수 값 불일치 문제가 발생하게 된다.
ex)
public class SharedObject {
public volatile int counter = 0;
}Multi Thread 환경에서 하나의 Thread만 read & write하고 나머지 Thread 가 read하는 상황에서 가장 최신의 값을 보장한다
volatile는 변수의 read와 write 를 Main Memory 에서 진행하게 된다
CPU Cache 보다 Main Memory가 비용이 더 크기 때문에 변수 값 일치를 보장해야 하는 경우에 volatile 을 사용하는 것이 좋다
4. 동시성 (Concurrency)과 병렬성 (Parallelism)
멀티 쓰레드가 실행될 때 이 두가지 중 하나로 실행된다.
이것은 CPU의 코어의 수와도 연관이 있는데, 하나의 코에서 여러 쓰레드가 실행되는 것을 "동시성", 멀티 코어를 사용할 때 코어별로 개별 쓰레드가 실행되는 것을 "병렬성"이라고 한다.
만약 코어의 수가 쓰레드의 수보다 많다면, 병렬성으로 쓰레드를 실행하면 되는데, 코어의 수보다 쓰레드의 수가 더 많을 경우 "동시성"을 고려하지 않을 수 없다.
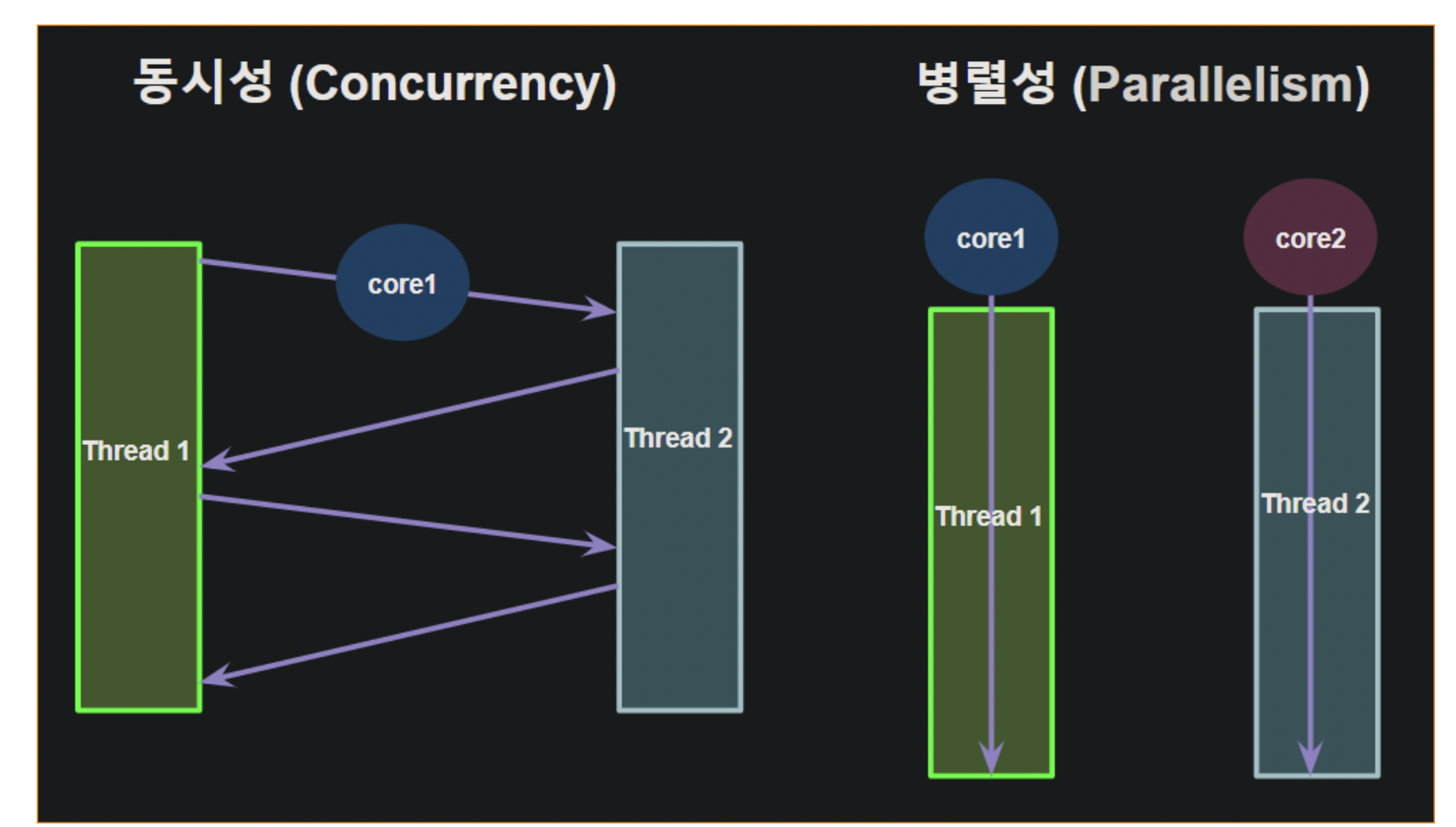
5. DeadLock(교착상태)
2개 이상의 프로세스가 다른 프로세스의 작업이 끝나기만 기다리며 작업을 더 이상 진행하지 못하는 상태를 교착 상태(dead lock)라고 한다.
5.1 필요 조건
교착상태가 발생하기 위해서는 아래의 4가지 조건을 만족해야 한다.
- 상호 배제
- 자원을 공유하지 못하면 교착 상태가 발생한다. 여기서 자원은 배타적인 자원이어야 한다. 배타적인 자원은 임계구역에서 보호되기 때문에 다른 프로세스(쓰레드)가 동시에 사용할 수 없다.
-
비선점
- 자원을 빼앗을 수 없드면 자원을 놓을 때까지 기다려야 하므로 교착상태가 발생한다.
-
점유와 대기
- 자원 하나를 잡은 상태에서 다른 자원을 기다리면 교착 상태가 발생합니다.
-
원형 대기
- 자원을 요구하는 방향이 원을 이루면 양보를 하지 않기 때문에 교착상태가 발생합니다.
5.2 해결 방법
-
교착 상태 예방
- 교착 상태는 상호 배제, 비선점, 점유와 대기, 원형 대기 라는 네 가지 조건을 동시에 충족해야 발생하기 때문에 이 중 하나라도 막는다면 교착 상태가 발생하지 않는다.
- 이 방법은 실효성이 적어 잘 사용되지 않는다.
-
교착 상태 회피
- 자원 할당량을 조절하여 교착 상태를 해결하는 방식이다.
- 즉, 자원을 할당하다가 교착 상태를 유발할 가능성이 있다고 판단하면 자원 할당을 중단하고 지켜보는 것
- 그러나 자원을 얼마만큼 할당해야 교착 상태가 발생하지 않는다는 보장이 없기 때문에 실효성이 적다.
-
교착 상태 검출과 회복
- 교착 상태 검출은 어떤 제약을 가하지 않고 자원 할당 그래프를 모니터링 하면서 교착 상태가 발생하는지 살펴보는 방식이다.
- 만약 교착 상태가 발생하면 교착 상태 회복 단계가 진행됩니다.
교착 상태를 검출한 후 이를 회복시키는 것은 결론적으로 교착 상태를 해결하는 현실적인 접근 방법이다.
6. fork & join 프레임워크
JDK 1.7부터 'fork & join 프레임워크' 가 추가 되어, 하나의 작업을 작은 단위로 쪼개서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어 준다.
수행할 작업에 따라 아래의 두 클래스 중에서 하나를 상속받아 구현한다.
RecursiveAction 반환값이 없는 작업을 구현할 때 사용
RecursiveTask 반환값이 있는 작업을 구현할 때 사용
위의 두 클래스를 상속받아 compute() 라는 추상 메소드에 작업할 내용으로 재정의 하면 된다.
ex) 1부터 n까지의 합을 계산한 결과를 반환
class SumTask extends RecursiveTask<Long> {
long from, to;
SumTask(long from, long to) {
this.from = from;
this.to = to;
}
public Long compute() {
long size = to - from + 1;
if (size <= 5) // 더할 숫자가 5개 이하면
return sum(); // 숫자의 합을 반환
long half = (from + to) / 2;
// 범위를 반으로 나눠서 두개의 작업을 생성
SumTask leftSum = new SumTask(from, half);
SumTask rightSum = new SumTask(half+1, to);
leftSum.fork();
return rightSum.compute() + leftSum.join();
}
long sum() {
long tmp = 0L;
for (long i = from; i <= to; i++) {
tmp += i;
}
return tmp;
}
}invoke() 메소드를 호출해서 작업을 시작
ForkJoinPool pool = new ForkJoinPool(); // 쓰레드 풀을 생성
SumTask task = new SumTask(from, to); // 수행할 작업을 생성
Long result = pool.invoke(task); // invoke() 를 호출해서 작업을 시작6.1 ForkJoinPool
fork&join프레임워크에서 제공하는 쓰레드 풀(thread pool)이다.
장점
- 지정된 수의 쓰레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게 한다.
- 쓰레드를 반복해서 생성하지 않아도 된다.
- 너무 많은 쓰레드가 생성되어도 성능 저하가 발생하는 것을 막아준다.
- 쓰레드 풀은 기본적으로 코어의 개수와 동일한 개수의 쓰레드를 생성한다.
6.2 Compute()
compute()를 구현할 때는 수행할 작업 외에도 작업을 어떻게 나눌 것인가에 대해서도 구현해야한다.
public Long compute() {
long size = to - from + 1;
if (size <= 5) { // 더할 숫자가 5개 이하면
return sum(); // 숫자의 합을 반환. sum()은 from부터 to까지의 수를 더해서 반환
}
// 범위를 반으로 나눠서 두 개의 작업을 생성
long half = (from + to) / 2;
// 절반을 기준으로 나눠 left, right 로 작업의 범위를 반으로 나눠서 새로운 작업으로 생성합니다.
SumTask leftSum = new SumTask(from, half); // 시작부터 절반지점 까지
SumTask rightSum = new SumTask(half+1, to); // 절반지점부터 끝까지
leftSum.fork(); // 작업(leftSum)을 작업 큐에 넣습니다.
return rightSum.compute() + leftSum.join();
}compute()는 작업을 반으로 나누고 fork()는 작업 큐에 작업을 담는다.
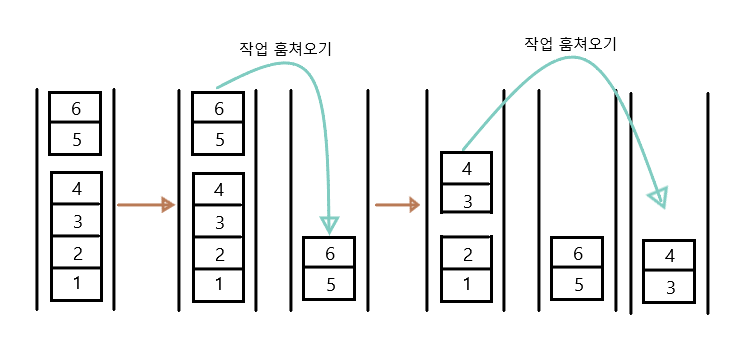
위는 compute() 메소드와 fork() 메소드로 인해 작업풀에 담긴 작업이 쓰레드 풀(thread pool)의 빈 쓰레드가 작업을 가져와서 작업을 수행하는 것을 나타낸 그림이다.
빈 쓰레드가 작은 단위의 작업을 가져와서 작업을 수행하는 것을 작업 훔쳐오기(work stealing)라고 하며, 이 과정은 모두 쓰레드 풀에 의해 자동으로 이루어 진다.
이런 과정을 통해 한 쓰레드에 작업이 몰리지 않고 여러 쓰레드가 골고루 작업을 나누어 처리하게 된다.
물론 작업의 크기가 충분히 작게 나눠져야 여러 쓰레드에게 작업을 골고루 나눠줄 수 있다.
6.3 fork() 와 join()
-
fork() : 해당 작업을 쓰레드 풀의 작업큐에 넣는다. 비동기 메소드(asynchronous method)
-
join() : 해당 작업의 수행이 끝날 때까지 기다렸다가, 수행이 끝나면 그 결과를 반환한다.동기 메소드(synchronous method)
return rightSum.compute() + leftSum.join(); 이 return 문에서 compute()가 재귀호출 될 때, join()은 호출되지 않는다. compute()로 더이상 작업을 나눌 수 없게 됐을 때 join()의 결과를 기다렸다가 더해서 결과를 반환한다.
즉, 재귀 호출된 모든 compute()가 모두 종료될 때, 최종 결과를 얻는다.
참조
