자바의 정석 책을 보면서 자바 스터디를 매주 진행하고 있다.
이번주는 각자 Collection을 구현해보고 만나서 토론해보기로 하였다.
이번주에 구현할 것은 ArrayList, LinkedList, DoubleLinkedList 세개이다.
LinkedList
LinkedList는 일반적인 배열(ArrayList)와는 다르게 데이터들이 연결되어 있다.
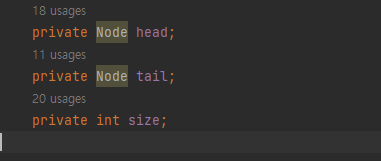
인스턴스 변수들을 보면 head와 tail을 가르키는 참조변수가 있다.
이 Node들로 부터 시작하여 다음 노드를 탐색하며 연산을 수행하는 컬렉션이다.
그럼 ArrayList와의 차이점은 무엇일까? ->인덱싱 유무
- 삽입, 삭제 연산을 할 때 ArrayList에 비해 연산비용이 적은 장점이 있다.
배열은 뒤의 요소들을 한칸씩 밀어주는 연산이 불가피하다. 하지만 LinkedList는 데이터들의 순서가 참조로써 설명이 되기 때문에 참조변수의 값만 바꾸면 된다.
그러므로 삽입, 삭제연산을 할 때 Arraaylist보다 빠르다.
- ArrayList에 비해서 요소 접근을 할 때 연산비용이 크다.
당연하게도 인덱싱의 차이 때문인데, Arraylist는 배열로 인덱싱을 하기 때문에 O(1)의 수행시간이 걸리는 반면에 LinkedList는 O(n)의 수행시간이 걸린다.
이제 함수단위로 설명하겠다.
- public void addLast(E value) 함수
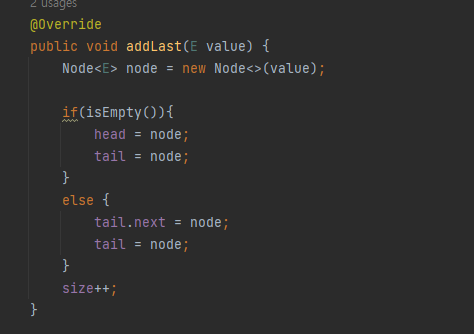
LinkedList는 요소가 하나일 때 head와 tail이 같은 요소를 가르키도록 해야한다. 그래서 비어있을 때의 연산을 나눠서 작성했다.
- boolean add(E value) 함수
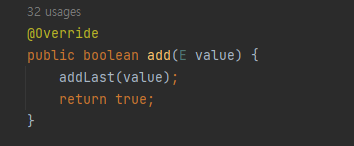
맨 뒤에 value를 넣는 연산을 한다.
처음 궁금했던 건 returnType이 boolean 형이다.
무조건 true일텐데 왜 boolean으로 리턴타입을 정했는지 궁금했다.
Collection에는 List, Set, Map이 있다.
Set은 중복을 허용하지 않는 특징이 있으므로 add함수는 boolean을 리턴하는 것이었다.
작동 방식은 addLast와 다를게 없다. 그래서 함수를 재사용 한다.
- add(index, E value) 함수.
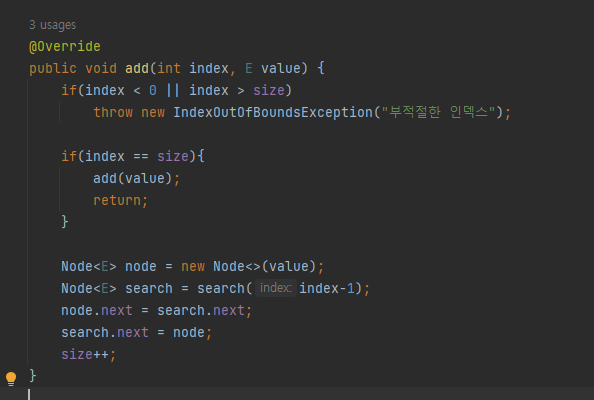
특정 인덱스에 요소를 넣는 연산을 한다.
위에서 설명했듯이 LinkedList의 인덱싱 특성으로 인해 요소를 뒤로 밀어주는 오버헤드가 필요 없다.
- E remove() 함수
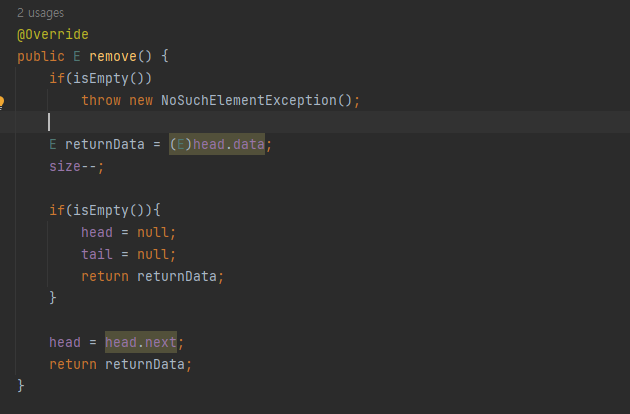
head에 있는 요소를 삭제하고 리턴하는 연산을 수행한다.
- E remove(int index) 함수
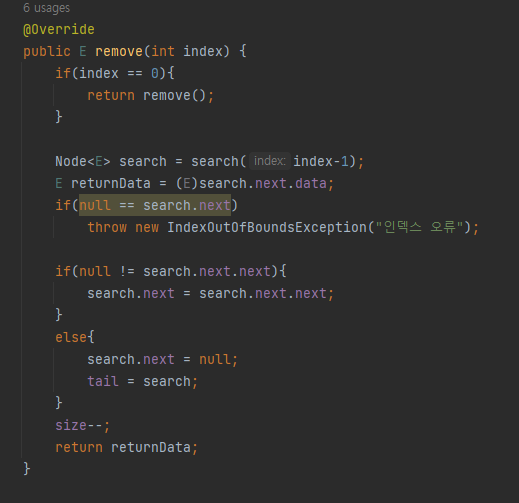
주의할 점은 search 함수로 찾을 때 index가 아닌 index-1을 찾는다.
그 이유는 index요소를 찾아서 삭제를 하려면 전 노드와 다음 노드를 연결해 주어야 한다.
DoubleLinkedList는 Node에 prev라는 참조변수를 통해서 전 노드를 탐색할 수 있지만, LinkedList는 Node에 prev 참조변수가 없으므로 그게 불가능하다. 그래서 prev노드를 가져오는 것이다.
- boolean remove(Object value)
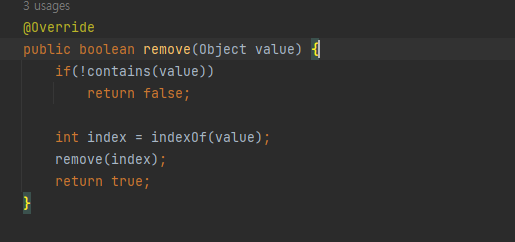
List는 중복 데이터를 허용한다.
만약 중복 데이터가 있을 때의 함수 작동 원리가 궁금했다.
공식문서를 보니 Head와 가까운 요소를 삭제한다고 나와있다.
그러므로 indexOf함수는 headNode부터 탐색을 해서 일치하는 첫번 째 요소의 인덱스일 것이다. 넘어가자.
- get, set, size 함수
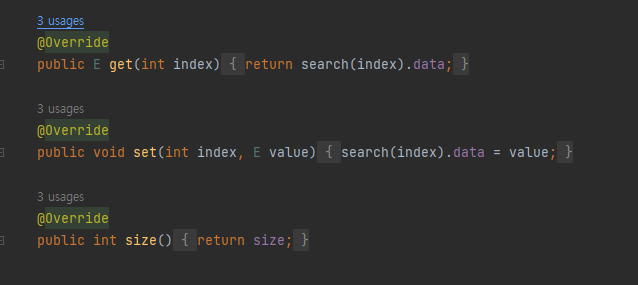
다른 연산이 필요없다. 함수 이름대로 연산을 해주면 된다.
또한 예외처리도 search 함수에서 해준다.
- contains, indexOf 함수.
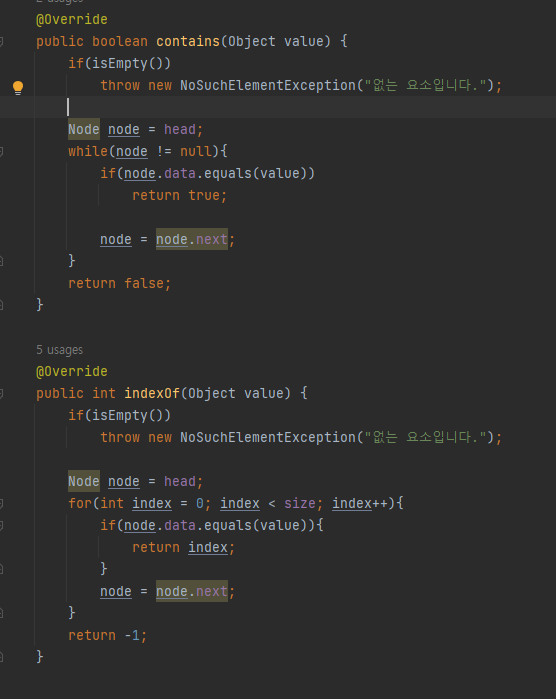
contains 함수는 일치하는 요소가 있는지 확인하여 boolean을 리턴한다.
indexOf 함수는 일치하는 요소가 있으면 인덱스를 반환하고 없으면 -1을 반환한다.
사실 두 함수의 연산은 같다. 리턴방식만 다를 뿐이다.
그래서 의문이 들었다. 왜 굳이 contains함수를 만들 이유가 있을까?
indexOf함수로도 충분히 contains함수의 역할을 수행할 수 있는데??
그 이유를 설명하자면 Collection 에는 List, Set, Map이 있고
List 하위에 LinkedList가 있다.
List와 Set의 가장 큰 차이점은 중복을 허용하지 않는 것이기 때문에 Collection 인터페이스에는 contains함수만 선언되어 있다.
그리고 Collection 인터페이스를 상속받은 List 인터페이스에서는 당연하게도 인덱싱으로 데이터의 순서를 구분하기 때문에 indexOf 함수가 선언되어 있다.
최종적으로 List 인터페이스를 구현한 LinkedList는 두 함수를 모두 구현해야 하지만, LinkedList에서는 저 위의 이유때문에 contains 함수가 필요하진 않다.
- isEmpty toArray 함수
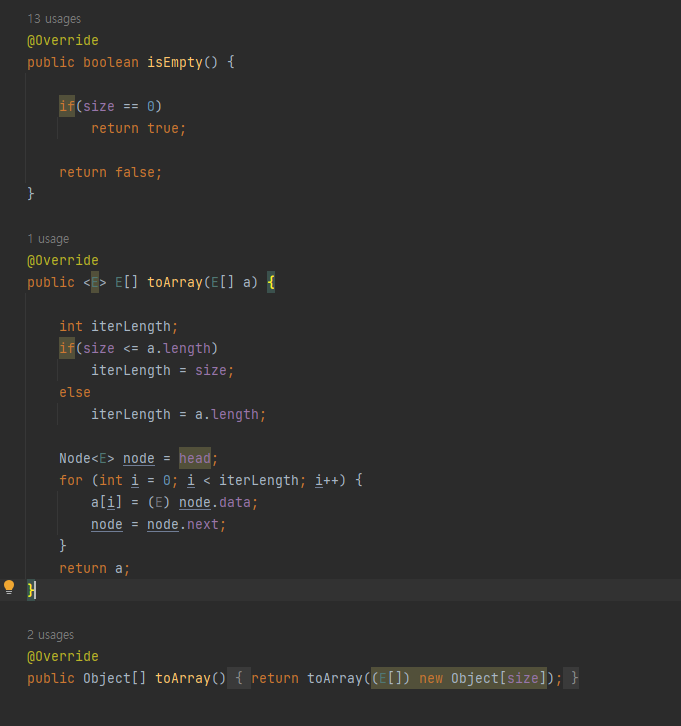
isEmpty 함수는 예외처리 할 때 많이 쓰이므로 함수화 해놓았다.
toArray함수는 두가지로 오버로딩 되었다.
첫번째는 매개변수로 배열을 받는다. 그 배열에 LinkedList객체의 요소들 복사해서 넣어준다.
만약 매개변수로 받은 배열의 사이즈가 객체의 요소 갯수 즉 size보다 크다면, 남은 요소들을 그대로 바꾸지 않고 반환된다.
객체 요소의 사이즈만큼만 복사되는 것이다.
만약 그 반대라면 매개변수 배열의 사이즈만큼 요소를 복사해준다.
두번째는 매개변수를 받지 않는다. 이 함수가 수행하는 역할은 객체 요소들을 배열로 만들어서 리턴하는 것이다. 그러므로 size변수만큼 배열을 할당해서 첫번째 함수를 호출했다.
- clear() 함수.
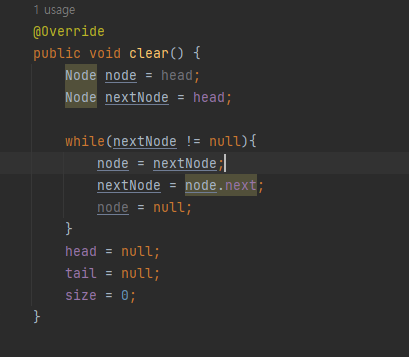
head와 tail을 null로 해주는 방법은 gc에게 메모리 해제를 맡기는 방법이다. 나는 이 방법이 모든 노드를 반복문으로 돌아서 null로 초기화를 시키는 명시적인 방법보다 수행시간이 좋은 방법인 줄 알았다.
하지만 잘 생각해보면 gc가 메모리를 해제하는 작업도 코드에 보이지는 않지만 수행시간에 포함된다. 그래서 어떤 방법이 옳은 방법인지 궁금했고 gc에 대해서 검색해봤다.
Reference
https://docs.oracle.com/en/java/javase/15/gctuning/introduction-garbage-collection-tuning.html
찾아봤더니 정답은 없는듯 하다.
gc를 믿지 않고 명시적으로 null로 초기화하여 메모리를 해제하는 개발자도 있고, 내가 처음 생각했던 방법처럼 gc에게 메모리해제를 맡기는 개발자도 있다.
하지만 clear함수같이 함수를 수행하는 로직이 메모리해제가 무조건 포함되어 있다면 오버헤드가 많은 gc에게 작업을 맡기는 방식보다, 개발자가 명시적으로 해제해주는 방법이 좋은거 같다고 생각한다.
- 총 코드.
import java.util.NoSuchElementException;
public class MyDoubleLinkedList<E> implements MyList<E>, CustomDoubleLinkedLst<E>{
private Node head;
private Node tail;
private int size;
@Override
public Node search(int index) {
if(isEmpty() || index < 0 || index >= size)
throw new IndexOutOfBoundsException("부적절한 인덱스");
Node node;
if(index < size/2) {
node = head;
for (int i = 0; i < index; i++) {
node = node.next;
}
}
else{
node = tail;
for(int i = size-1; i > index; i--){
node = node.prev;
}
}
return node;
}
@Override
public boolean add(E value) {
addLast(value);
return true;
}
@Override
public void add(int index, E value) {
if(index < 0 || index > size)
throw new IndexOutOfBoundsException("부적절한 인덱스");
if(index == size){
add(value);
return;
}
Node<E> node = new Node<>(value);
Node search = search(index);
node.prev = search.prev;
node.next = search;
search.prev.next = node;
search.prev = node;
size++;
}
@Override
public void addFirst(E value) {
Node node = new Node(value);
if(isEmpty()){
head = node;
tail = node;
size++;
return;
}
node.next = head;
head.prev = node;
head = node;
size++;
}
@Override
public void addLast(E value) {
Node node = new Node(value);
if(isEmpty()){
head = node;
tail = node;
size++;
return;
}
if(size == 1){
tail = node;
head.next = node;
node.prev = head;
size++;
return;
}
tail.next = node;
node.prev = tail;
tail = node;
size++;
}
@Override
public E remove(int index) {
Node search = search(index);
E returnData = (E)search.data;
if(index == 0){
head = null;
tail = null;
size--;
return returnData;
}
if(index == size-1){
search.prev.next = null;
tail = search.prev;
}
else{
search.prev.next = search.next;
search.next.prev = search.prev;
}
size--;
return returnData;
}
@Override
public boolean remove(Object value) {
if(!contains(value))
return false;
int index = indexOf(value);
remove(index);
return true;
}
@Override
public E remove() {
if(isEmpty())
throw new NoSuchElementException();
Node<E> node = head;
E returnData = (E)head.data;
size--;
if(isEmpty()){
head = null;
tail = null;
return returnData;
}
head = head.next;
head.prev = null;
return returnData;
}
@Override
public int lastIndexOf(Object o) {
Node<E> node = tail;
for(int index = size-1; index >=0; index--){
if(node.data.equals(o))
return index;
node = node.prev;
}
throw new NoSuchElementException("없는 요소입니다.");
}
@Override
public E get(int index) {
return (E)search(index).data;
}
@Override
public void set(int index, E value) {
Node node = search(index);
node.data = value;
}
@Override
public boolean contains(Object value) {
Node<E> node = head;
for(int i = 0; i < size; i++){
if(node.data.equals(value))
return true;
}
return false;
}
@Override
public int indexOf(Object value) {
if(isEmpty())
throw new NoSuchElementException("없는 요소입니다.");
Node<E> node = head;
for(int index = 0; index < size; index++){
if(node.data.equals(value)){
return index;
}
node = node.next;
}
throw new NoSuchElementException("없는 요소입니다.");
}
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
if(size == 0)
return true;
return false;
}
@Override
public <E> E[] toArray(E[] a) {
int iterLength;
if(size <= a.length)
iterLength = size;
else
iterLength = a.length;
Node<E> node = head;
for (int i = 0; i < iterLength; i++) {
a[i] = (E) node.data;
node = node.next;
}
return a;
}
@Override
public Object[] toArray() {
return toArray((E[]) new Object[size]);
}
/**
* clear 함수
* for문을 돌려서 매 요소마다 null을 선언해주는것과
* head와 tail을 모두 null을 선언해주는 방식이 있다.
*
* velog에 올림.
*/
@Override
public void clear() {
Node node = head;
Node nextNode = head;
while(nextNode != null){
node = nextNode;
nextNode = node.next;
node = null;
}
head = null;
tail = null;
size = 0;
}
class Node<E> {
E data;
Node<E> next;
Node<E> prev;
public Node(){
}
public Node(E data){
this.data = data;
}
}
}
