
개요
Spring Batch에서 병렬로 배치를 실행하는 방법을 지원합니다.
저번 시간에는 파티셔닝을 통해 Step을 나눠, 병렬 실행하는 방법을 알아보았습니다.
이번 포스팅에서는 Multi-threaded Step이 뭔지 알아보고, 실습해보는 시간을 갖겠습니다.
Multi-threaded Step이란?
Multi-threaded Step은 하나의 Step 내에서 청크 단위를 병렬로 실행합니다. 저번 포스팅에서 학습했던 Partitioning 와 비교해보면, Partitioning은 여러 파티션을 나눠서 독립적인 환경을 갖춘 뒤, 병렬 실행했습니다.
따라서 각 파티션마다 중복되지 않는 데이터를 처리하는 Partitioning 방식은 Reader와 Writer를 구성할 때, 동시성을 생각할 필요가 없습니다. 만약 Partitioning 방식을 사용할 때 동시성이 발생한다면, 파티셔닝에 문제가 있는 것이죠.
Multi-threaded Step 은 환경을 분할하지 않고, 멀티 스레드로 Step을 병렬 실행하기 때문에, 스레드 안전한 배치 작업을 설계하는 것이 중요합니다.
그럼 Multi-threaded Step을 구성하는 방법과, 스레드 안전한 배치 작업을 설계하는 방법을 알아보겠습니다.
Multi-threaded Step 구성하기
멀티스레드 Step을 구성하는 가장 간단한 방법은 TaskExecutor 를 Step 구성에 추가하는 것입니다.
SimpleAsyncTaskExecutor
아래는 가장 간단한 구현체인 SimpleAsyncTaskExecutor 를 사용하여 멀티스레드 Step을 구성하는 방법입니다.
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}하지만 실제 환경에서는 SimpleAsyncTaskExecutor 를 사용하는 것은 성능적인 이슈가 있습니다.
SimpleAsyncTaskExecutor 코드 내부의 주석을 보시면..
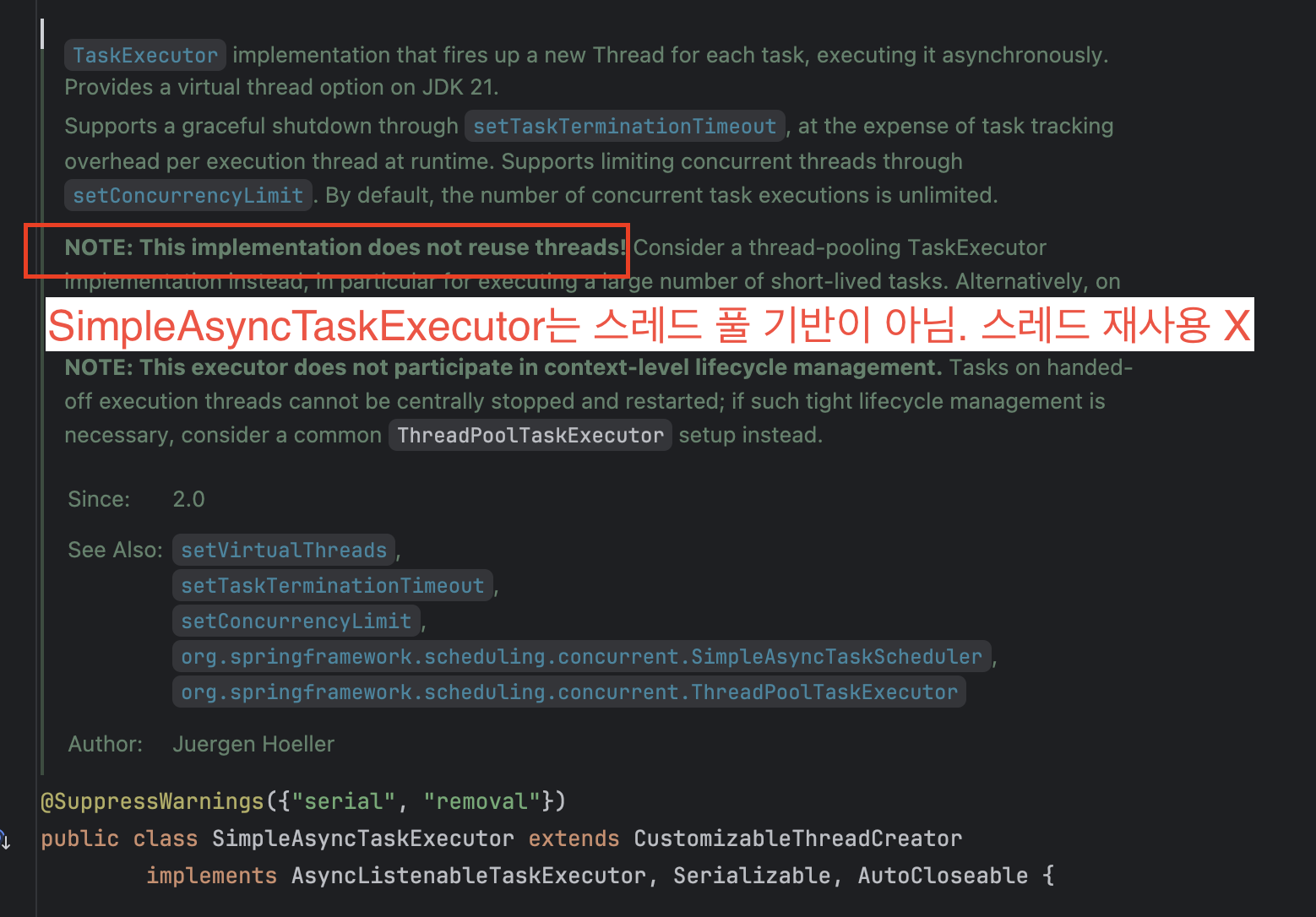
SimpleAsyncTaskExecutor 는 스레드풀 기반이 아니라서, 스레드를 재사용하지 않는다는 성능적 이슈가 있습니다.
ThreadPoolTaskExecutor
따라서 실무 상황에서는 아래 예시처럼 스레드풀 기반의 ThreadPoolTaskExecutor 을 사용하는게 적합합니다.
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setThreadNamePrefix("batch-thread-");
executor.initialize();
return executor;
}간단하게 ThreadPoolTaskExecutor를 살펴봅시다.
corePoolSize: 동시에 실행 가능한 스레드의 갯수maxPoolSize: 최대로 수행 가능한 스레드의 갯수queueCapacity:corePoolSize만큼 스레드가 작업중일 경우, 작업을 대기큐에 넣는다. 이 때 대기큐의 용량이다.
이 개념들은 스레드풀에 대한 내용이니 넘어가도록 하겠습니다.
Thread-safe한 Multi-threaded Step 구성
주의할 점은 대부분의 표준 Reader 들은 기본적으로 thread-unsafe 합니다.
따라서 멀티스레드 설정 시 동일한 Reader 인스턴스를 여러 스레드에서 공유하게 되어, 읽기 순서가 꼬이거나 예외가 발생할 수 있습니다.
따라서 Reader를 thread-safe 하게 구성해주어야 하는데, 크게 두가지 방법이 있습니다.
Thread safe한 Reader 구성하는 방법
1. SynchronizedItemStreamReader
Thread-safe하게 Reader를 구성하는 첫 번째 방법은, SynchronizedItemStreamReader 를 사용하는 것입니다.
SynchronizedItemStreamReader 는 Spring Batch에서 제공하는 래퍼클래스입니다.
@Bean
public SynchronizedItemStreamReader<Orders> syncReader() {
return new SynchronizedItemStreamReaderBuilder<Orders>()
.delegate(orderJpaCursorItemReader())
.build();
}위와 같이 SynchronizedItemStreamReader 에 기존 Reader를 위임하는 방식으로 구성할 수 있습니다.
SynchronizedItemStreamReader 의 내부 구조를 간단하게 봐보자면
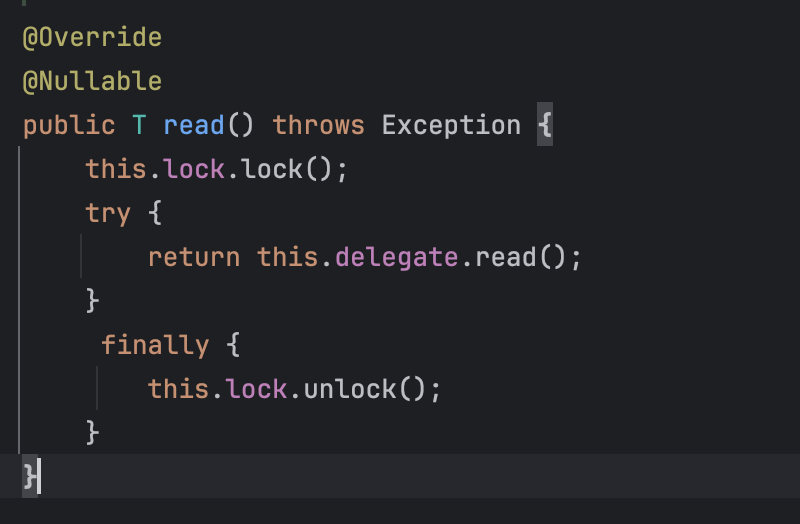
내부적으로 read()를 호출하기 전에 lock을 얻고, read가 끝난 뒤 lock을 해제하여 thread-safe하게 만들어 줍니다.
2. Thread-safe Reader 사용
두 번째로는 thread-safe한 Reader를 사용하는 것입니다.
JdbcPagingItemReader 는 대표적인 thread-safe한 Reader입니다. 멀티 스레드 환경에서는 saveState=false 로 설정해야 한다는 것을 주의한다면, thread-safe한 Reader를 구성할 수 있습니다.
따라서 전에 작성했던 JpaCursorItemReader 기반 리더는, thread-safe하지 않습니다. 따라서 thread-safe하게 구성하기 위해 JpaPagingItemReader 로 변경하는 것이 적합해 보입니다.
Multi-threaded Step 실습
전에 작성했던 사용자별 월별 주문 통계를 요약하는 배치 시스템을 Multi-threaded Step으로 변경해보는 실습을 진행하겠습니다.
TaskExecutor
먼저 스레드 풀 기반의 TaskExecutor 를 설정하고, Step 구성에 추가해야 합니다.
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setThreadNamePrefix("batch-thread-");
executor.initialize();
return executor;
}
@Bean
public Step multiThreadedStep() {
return new StepBuilder("multiThreadedStep", jobRepository)
.<Orders, MonthlySalesSummary>chunk(CHUNK_SIZE, transactionManager)
.reader(ordersPagingReader())
.processor(multiThreadedOrderToSummaryProcessor())
.writer(summaryWriterV2())
.taskExecutor(taskExecutor) // 멀티 스레드 설정
.build();
}Thread Safe Reader 구성
Multi-threaded Step을 구성할 때 가장 중요한 것은 스레드 안전한 Reader와 Writer를 구성하는 것입니다.
그 전에 작성했던 Cursor 기반의 ItemReader인 JpaCursorItemReader 은 멀티 스레드 환경에서 안전하지 않습니다. 커서를 공유하게 된다면, 청크 단위의 아이템 격리가 뭉개지게 됩니다.
따라서 위에서 설명한 대로 JpaPagingItemReader 를 사용하여 Reader를 구성해야 합니다.
하지만 JpaPagingItemReader 는 row 기반 페이징 방식이고, 성능 향상을 위해 Fetch Join과 함께 쿼리를 실행하게 되면 심각한 성능적인 이슈가 발생하게 됩니다.
관련 이슈에 대해서 궁금하신 분들은 TS-Pagination with fetch join여기를 참고해주세요.
간략하게 설명하자면, 페이지네이션과 N+1 방지를 위한 Fetch join을 함께 수행하려면, 한방 쿼리로 불가능합니다. 조회 쿼리를 실행시키는 시점에 row의 수를 측정할 수 없기 때문입니다.
따라서 id를 기준으로 먼저 페이징을 한 뒤, IN 쿼리를 통해 모든 order의 연관관계 엔티티들을 Fetch join하여 청크당 2번의 쿼리를 통해 아이템을 가져오는 ItemReader를 직접 구현했습니다.
package chan.springbatch.springbatchex.config.job.sales.reader;
import chan.springbatch.springbatchex.domain.order.Orders;
import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.stereotype.Component;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.atomic.AtomicInteger;
@Component
@Slf4j
@RequiredArgsConstructor
public class OrdersReader implements ItemStreamReader<Orders> {
private final EntityManagerFactory emf;
private final int pageSize = 1000;
private int offset = 0;
private final Queue<Orders> buffer = new LinkedList<>();
@Override
public Orders read() {
synchronized (this) {
if (!buffer.isEmpty()) return buffer.poll(); // 이미 채워져 있으면 바로 꺼내기
try (EntityManager em = emf.createEntityManager()){ // try with resources
List<Long> ids = em.createQuery("""
SELECT o.id FROM Orders o ORDER BY o.id
""", Long.class)
.setFirstResult(offset)
.setMaxResults(pageSize)
.getResultList();
if (ids.isEmpty()) return null;
List<Orders> orders = em.createQuery("""
SELECT DISTINCT o
FROM Orders o
LEFT JOIN FETCH o.user
LEFT JOIN FETCH o.orderItems
WHERE o.id IN :ids
ORDER BY o.id
""", Orders.class)
.setParameter("ids", ids)
.getResultList();
buffer.addAll(orders); // 버퍼에 채워두고
offset+=pageSize;
return buffer.poll(); // 첫 번째 항목 반환
}
}
}
}
위 코드에서 스레드끼리 공유하는 offset, buffer 는 스레드 안전해야 합니다.
스레드 안전한 AtomicInteger , ConcurrentLinkedQueue 를 사용하는 방법도 있습니다만, 공부용 단일 인스턴스 실습 상황입니다. 또한 확장에 대한 생각도 없으므로 syncronized 키워드를 통해 공유 자원인 offset과 buffer 를 스레드 안전하게 해주었습니다.
Thread Safe Writer 구성
@Bean
@StepScope
public ItemWriter<MonthlySalesSummary> summaryWriterV2() {
String UPSERT_SQL = """
INSERT INTO monthly_sales_summary(user_id, year_month_value, monthly_order_count, monthly_spend_money)
VALUES (?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
monthly_order_count = monthly_order_count + VALUES(monthly_order_count),
monthly_spend_money = monthly_spend_money + VALUES(monthly_spend_money)
""";
return items -> {
Map<String, MonthlySalesSummary> summaryMap = new HashMap<>();
for (MonthlySalesSummary item : items) {
String key = item.getUser().getId() + "_" + item.getYearMonth();
summaryMap.merge(key, item, (existing, incoming) -> {
existing.accumulateSpendMoney(incoming.getMonthlySpendMoney());
existing.plusOrderCount(incoming.getMonthlyOrderCount());
return existing;
});
}
synchronized (this) {
// JdbcTemplate batch upsert 실행
List<MonthlySalesSummary> mergedItems = new ArrayList<>(summaryMap.values());
jdbcTemplate.batchUpdate(
UPSERT_SQL,
mergedItems,
1000,
(ps, item) -> {
ps.setLong(1, item.getUser().getId());
ps.setString(2, item.getYearMonth());
ps.setInt(3, item.getMonthlyOrderCount());
ps.setLong(4, item.getMonthlySpendMoney());
}
);
}
};
}synchronized 키워드를 사용해 JdbcTemplate의 upsert를 순차적으로 처리함으로써 동시성 문제와 데드락 가능성을 방지했습니다.
만약 병렬 스레드에서 upsert를 동시에 실행할 경우, 아래와 같은 교착 상태(Deadlock)가 발생할 수 있습니다.
예시
- ThreadA는
user1의 통계 정보를 먼저 업데이트한 뒤,user2의 정보를 업데이트하려고 합니다.- 동시에 ThreadB는
user2의 정보를 먼저 업데이트하고, 이어서user1의 정보를 업데이트하려고 합니다.- 이때 각 스레드가 서로 상대방이 점유한 리소스를 기다리는 상황이 되어 데드락이 발생합니다.
이처럼 업데이트 대상 유저가 교차될 경우, MySQL의 InnoDB 락 순서에 따라 교착 상태가 발생할 수 있으므로, Writer 단에서 동기화를 적용해 upsert를 순차 처리하는 것이 안전합니다.
실습 전체 코드
package chan.springbatch.springbatchex.config.job.sales;
import chan.springbatch.springbatchex.config.job.sales.reader.OrdersReader;
import chan.springbatch.springbatchex.domain.order.Orders;
import chan.springbatch.springbatchex.domain.summary.MonthlySalesSummary;
import jakarta.persistence.EntityManagerFactory;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.transaction.PlatformTransactionManager;
import java.time.YearMonth;
import java.util.*;
@Slf4j
@Configuration
@RequiredArgsConstructor
public class MultiThreadedMonthlySalesSummaryJobConfig {
private static final int CHUNK_SIZE = 1000;
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final EntityManagerFactory emf;
private final JdbcTemplate jdbcTemplate;
private final TaskExecutor taskExecutor;
@Bean
public Job multiThreadedMonthlySalesSummaryJob() {
return new JobBuilder("multiThreadedMonthlySalesSummaryJob", jobRepository)
.start(multiThreadedStep())
.build();
}
@Bean
public Step multiThreadedStep() {
return new StepBuilder("multiThreadedStep", jobRepository)
.<Orders, MonthlySalesSummary>chunk(CHUNK_SIZE, transactionManager)
.reader(ordersPagingReader())
.processor(multiThreadedOrderToSummaryProcessor())
.writer(summaryWriterV2())
.taskExecutor(taskExecutor) // 멀티 스레드 설정
.build();
}
@Bean
@StepScope
public ItemStreamReader<Orders> ordersPagingReader() {
return new OrdersReader(emf);
}
@Bean
public ItemProcessor<Orders, MonthlySalesSummary> multiThreadedOrderToSummaryProcessor() {
return order -> {
var user = order.getUser();
var month = YearMonth.from(order.getOrderAt());
long total = order.getOrderItems().stream()
.mapToLong(i -> (long) i.getQuantity() * i.getPrice())
.sum();
return MonthlySalesSummary.builder()
.user(user)
.yearMonth(month.toString())
.monthlySpendMoney(total)
.monthlyOrderCount(1)
.build();
};
}
@Bean
@StepScope
public ItemWriter<MonthlySalesSummary> summaryWriterV2() {
String UPSERT_SQL = """
INSERT INTO monthly_sales_summary(user_id, year_month_value, monthly_order_count, monthly_spend_money)
VALUES (?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
monthly_order_count = monthly_order_count + VALUES(monthly_order_count),
monthly_spend_money = monthly_spend_money + VALUES(monthly_spend_money)
""";
return items -> {
Map<String, MonthlySalesSummary> summaryMap = new HashMap<>();
for (MonthlySalesSummary item : items) {
String key = item.getUser().getId() + "_" + item.getYearMonth();
summaryMap.merge(key, item, (existing, incoming) -> {
existing.accumulateSpendMoney(incoming.getMonthlySpendMoney());
existing.plusOrderCount(incoming.getMonthlyOrderCount());
return existing;
});
}
synchronized (this) {
// JdbcTemplate batch upsert 실행
List<MonthlySalesSummary> mergedItems = new ArrayList<>(summaryMap.values());
jdbcTemplate.batchUpdate(
UPSERT_SQL,
mergedItems,
1000,
(ps, item) -> {
ps.setLong(1, item.getUser().getId());
ps.setString(2, item.getYearMonth());
ps.setInt(3, item.getMonthlyOrderCount());
ps.setLong(4, item.getMonthlySpendMoney());
}
);
}
};
}
}
마무리
여기까지 총 6개의 실습을 완료하며 Spring Batch를 학습해보았습니다.
약 한 달여 간 공식 문서를 참고하고, 다양한 시나리오를 직접 설계해보며 실습을 진행했습니다.
Spring Batch를 배우기 전에는 단순한 스케줄러와 함께 서비스 애플리케이션 내에서 배치 작업을 처리해왔습니다. 당시에는 큰 불편함을 느끼지 못했지만, 이번 학습을 통해 배치 시스템에 특화된 Spring Batch의 장점들을 직접 체감할 수 있었습니다. 특히 상태 관리, 재시작, 예외 스킵 처리, 그리고 확장성 측면에서 훨씬 더 유연하고 안정적인 아키텍처를 구성할 수 있다는 점이 인상 깊었습니다.
또한 성능 모니터링을 직접 추가해본 경험도 매우 유익했습니다.
이전까지는 단순히 쿼리 수나 알고리즘 복잡도를 기준으로 성능을 추정했었지만,
이번 실습에서는 실제 메트릭 기반의 측정을 통해 성능을 수치로 비교하고 분석할 수 있었습니다.
이를 통해 병목 지점을 파악하고, 개선 효과를 정량적으로 확인하는 과정이 무척 인상 깊었습니다.
