AWS Certified Solutions Architect Associate [9] Amazon S3 Advanced

S3 Advanced
S3 MFA-Delete
MFA-삭제는MFA라고 하는 다요소 인증을 사용해 사용자로 하여금 장치(휴대전화 혹은 하드웨어 키 등)에서코드를 생성하도록 합니다.- MFA-삭제를 사용하려면 먼저 S3 버킷에서 버저닝을 활성화해야 합니다.
- MFA가 필요한 경우
- 영구적으로 객체 버전을 삭제
- 버킷에서 버저닝을 중단하는 경우
- MFA를 사용할 필요가 없는 경우
- 버저닝을 활성화
- 삭제된 버전을 목록화
- 마커를 붙여서 버전을 삭제하는 경우
오직 루트 계정인 버킷 소유자만이 활성화 및 비활성화를 할 수 있습니다.현재는 CLI를 통해서만 MFA-삭제를 사용합니다.
S3 기본 암호화 vs 버킷 정책
- S3 버킷에 객체를 푸시하고 객체가 암호화되도록 하기 위해서 :
버킷 정책을 사용해 암호화를 강제합니다.버킷 정책을 사용하면API 호출에서 암호화 헤더가 지정되지 않은 채 Amazon S3에 도달하면, 요청이 거부됩니다- 따라서
사용자의 S3 버킷에 푸시되는 모든 객체를 암호화하는 효과를 가져옵니다.
- Amazon S3의
기본 암호화 옵션을 사용하는 겁니다.- 암호화되지 않은 객체를 Amazon S3에 업로드하면 기본 암호화 옵션을 통해 암호화가 이루어지는 겁니다.
- 다만 암호화된 객체를 업로드할 때 재암호화가 되지는 않습니다.
- 중요한 점은
버킷 정책 방식이 기본 암호화보다 먼저 먼저 고려된다는 것입니다.
S3 Access Logs
감사 목적으로 모든 액세스를 S3 버킷에 로깅하는 경우,- Amazon S3로 보내지는 모든 요청은 계정과 승인 여부에 상관 없이 다른 S3 버킷에 로깅 되어 이후에 분석이 가능합니다.
- 데이터 분석 도구를 이용해서 분석
- Amazon Athena를 사용해 분석
- Warning (경고)
- 모니터링 중인 버킷을
로킹 버킷으로 설정하시면절대로 안 됩니다.- 로깅 루프가 생기게 되고 버킷의 크기가 기하급수적으로 커집니다.
- 모니터링 중인 버킷을
S3 복제 (CRR / SRR)
- 복제를 하려는 이유
- 재해가 발생할 경우를 대비해 다른 리전에 저장하는 것입니다.
- 내부적으로 비동기식 복제가 이루어져야 합니다.
- 소스 및 대상 버킷에 버저닝을 활성화해야 합니다.
- 복제는
비동기식이므로 백그라운드에서 이루어질 겁니다. - 복제를 실행하려면 S3에
적절한 IAM 권한을 제공해야 합니다.
- CRR
- 리전 간 복제
규정 준수및액세스 시 지연 시간 단축또는계정 간 복제등이 있습니다.
- SRR
- 동일 리전 간 복제
여러 계정에 걸친 로그 집계와프로덕션및테스트 계정 간의 실시간 복제
또는재해 복구입니다.
Note
- S3 복제를 활성화하면 버킷의 내부에서 활성화한 시점부터 새로운 객체만 복제될 것입니다.
- S3 배치 복제
- 기존 객체뿐만 아니라 S3 복제 메커니즘에서 실패한 모든 객체를 복제할 수 있습니다.
- DELETE 작업을 할 때,
- 소스에서 대상 버킷으로 삭제 마커를 복제할지 여부를 선택하는 옵션이 있습니다.
- 만약 특정한 버전 ID를 삭제하려고 한다면 악의적인 삭제를 막기 위해 복제되지 않을 겁니다.
- 마지막으로 연쇄(Chaining) 복제가 존재하지 않습니다.
- 즉 버킷 1이 버킷 2에 복제되고 버킷 2가 버킷 3에 복제되면 버킷 1의 객체는 버킷 3으로 복제되지 않습니다.
S3 pre-signed URLs
SDK또는CLI를 사용해야 합니다.- 다운로드의 경우 쉬운 방법으로 CLI
- 업로드의 경우 쉬운 방법으로 SDK
- 기본적인 만료 시간은 3,600초, 즉 1시간입니다.
- 시간초과를 변경하려면 명령어 --expires-in에 파라미터, 인자, 초 단위로 시간을 지정하면 됩니다.
- 기본적으로 생성한 사람의 권한이 상속됩니다.
객체를 만든 이의 권한- 사용자들은 상황에 따라
GET이나PUT권한을 사용할 수 있습니다.
- 로그인한 사용자만이 S3 버킷의 프리미엄 영상을 다운로드하도록 승인.
- 파일을 다운로드할 사용자들의 목록이 지속적으로 변경될 경우.
- 사용자가 버킷의 특정 위치에만 파일을 업로드하도록 일시적으로 승인할 수도 있습니다.
S3 Storage Classes

- Amazon S3 Standard - General Purpose
- Amazon S3 Standard - Infrequent Access (IA)
- Amazon S3 One Zone - Infrequent Access
- Amazon S3 Glacier Instant Retrieval
- Amazon S3 Glacier Flexible Retrieval
- Amazon S3 Glacier Deep Archive
- Amazon S3 Intelligent Tiering
Amazon S3에서 객체를 생성할 때
클래스를 선택할 수도 있고 스토리지 클래스를 수동으로 수정할 수도 있습니다.
Amazon S3 수명 주기 구성을 사용해 스토리지 클래스 간에 객체를 자동으로 이동할 수도 있습니다.
- 내구성(Durability)
- Amazon S3로 인해 객체가 손실되는 횟수를 나타냅니다.
- Amazon S3는 매우 뛰어난 내구성을 제공합니다.
- 9가 11개 즉, 99.999999999%의 내구성을 보장합니다.
- Amazon S3에서 모든 스토리지 클래스의 내구성은 동일합니다
- 가용성(Availability)
- 서비스가 얼마나 용이하게 제공되는지를 나타냅니다.
- 스토리지 클래스에 따라 다릅니다.
- S3 Standard의 가용성은 99.99%인데요
즉, 1년에 약 53분 동안은 서비스를 사용할 수 없다는 의미죠
다시 말해 서비스를 사용할 때 몇 가지 에러가 발생한다는 뜻입니다.
- S3 Standard의 가용성은 99.99%인데요
Amazon S3 Standard - General Purpose
- 가용성은 99.99%
- 자주 액세스하는 데이터에 사용됩니다.
- 기본적으로 사용하는 스토리지 유형입니다.
지연 시간이 짧고처리량이 높습니다.- AWS에서 두 개의 기능 장애를 동시에 버틸 수 있습니다.
- 빅 데이터 분석
- 모바일과 게임 애플리케이션
- 콘텐츠 배포
Amazon S3 Infrequent Access
-
자주 액세스하지는 않지만 필요한 경우 빠르게 액세스해야 하는 데이터를 말합니다.
-
Amazon S3 Standard-Infrequent Access- S3 Standard보다
비용이 적게 들지만검색 비용이 발생합니다. - S3 Standard-IA의 가용성은 99.9%로 S3 Standard에 비해 약간 떨어집니다.
- S3 Standard보다
- 재해 복구
- 백업
Amazon S3 One Zone-Infrequent Access- One Zone-IA로도 불립니다.
단일 AZ 내에서는 높은 내구성을 갖지만 AZ가 파괴된 경우 데이터를 잃게 됩니다.- 가용성은 더 낮은 수준인
99.5%입니다.
- 온프레미스 데이터를 2차 백업
- 재생성 가능한 데이터를 저장
Amazon S3 Glacial Storage Classes
콜드 스토리지아카이빙과백업을 위한저비용 객체 스토리지입니다.비용=스토리지+검색
Amazon S3 Glacier Instant Retrieval밀리초 단위로 검색이 가능합니다.최소 보관 기간이90일이기 때문에분기에 한 번 액세스하는 데이터에 아주 적합합니다.
Glacier Flexible Retrieval (이전엔 Amazon S3 Glacier)Expedited는 데이터를 1~5분Standard는 데이터를 3~5시간Bulk는 데이터를 5~12시간최소 보관 기간은 역시90일입니다.
Glacier Deep ArchiveStandard는 데이터를 12시간Bulk는 데이터를 48시간- 비용이 가장 저렴합니다.
- 최소 보관 기간도 180일.
S3 Intelligent Tiering
- 사용 패턴에 따라 액세스된 티어 간에 객체를 이동할 수 있게 해줍니다.
- S3 Intelligent-Tiering에는 검색 비용이 없습니다.
- S3 Intelligent Tiering은 알아서 객체를 이동시켜 주기 때문에 편하게 스토리지를 관리할 수 있어요.
* **`FrequentAccess 티어`**는 `자동`이고 `기본 티어`입니다. * **`Infrequent Access 티어`**는 `30일 동안 액세스하지 않는 객체 전용 티어`입니다. * **`Archive Instant Access 티어`**도 `자동`이지만 `90일 동안 액세스하지 않는 티어 전용`입니다 * **`Archive Access 티어`**는 **`선택 사항`**이며 `90일에서 700일 이상`까지 구성할 수 있고 * **`Deep Archive Access 티어`**는 `180일에서 700일 이상` `액세스하지 않는 객체`에 구성할 수 있습니다.
S3 스토리지 간의 객체의 전환
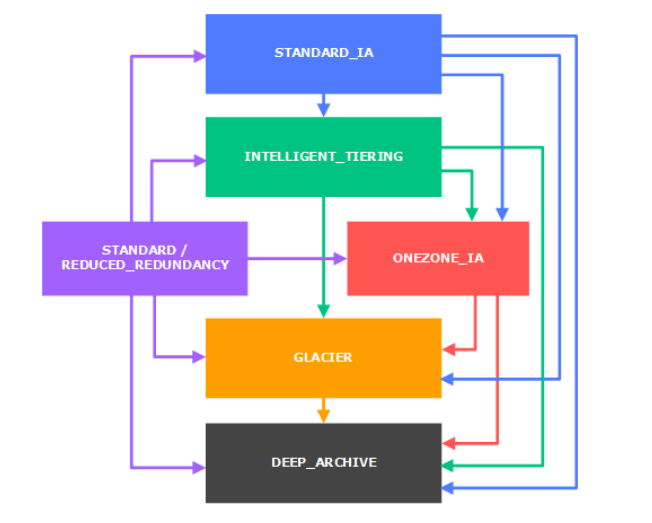
- 드물게 액세스하는 객체의 경우에는 맨 상단의 STANDARD_IA로 보냅니다.
- 실시간으로 필요한 게 아닌 아카이브 객체는 기본적으로는 GLACIER나 DEEP_ARCHIVE로 보내집니다.
- 객체의 클래스 간 이동은
수동으로 할 수도 있지만수명 주기 구성을 사용해 자동으로 할 수도 있습니다.
S3 수명 주기 규칙
전환 작업객체를 한 스토리지 클래스에서 다른 스토리지 클래스로 전환하는 데에 도움을 주는 작업입니다.- 객체를 생성 60일 후 Standard IA 클래스로 보내고
6개월 후에는 아카이빙을 위해 Glacier로 옮긴다고 하면 간단하고 자연스러운 과정입니다.
- 객체를 생성 60일 후 Standard IA 클래스로 보내고
- 만료 작업
- 일정 기간이 지난 후
객체를 삭제하는 겁니다.- 액세스 로그 파일들이 일 년이 지나서 더 이상 필요가 없어지면 파일들이 전부 일 년이 넘었으니 만료, 즉 삭제해 달라고 요청하는 식입니다.
- 파일의 오래된 버전을 삭제하는 데에도 사용됩니다.
- 버저닝이 가능하다면,
- 완료되지 않은 다중 파트 업로드를 정리하는 데에도 사용됩니다.
- 특정 접두어에 규칙을 적용할 수도 있습니다.
- 특정 객체 태그를 위해 규칙을 생성할 수도 있습니다.
- 일정 기간이 지난 후
S3 애널리틱스
Standard로부터Standard_IA로 언제 객체를 보낼지 결정하기 위해S3 애널리틱스를 설정할 수 있습니다.- 즉 며칠 후에 객체를 보내는 것이 가장 좋을지 계산하는 것.
ONEZONE_IA또는GLACIER에 대해 작동하지는 않습니다.- 이 보고서를 활성화하면 매일 업데이트됩니다.
- 처음 활성화할 때는 첫 시작까지 24~48시간이 소요됩니다.
- 수명 주기 규칙을 구축하거나 개선하기 위한 아주 좋은 첫 번째 단계
- S3 애널리틱스를 활성화 하는 것입니다.
S3 Baseline Performance
- 기본적으로
Amazon S3는자동으로 아주 많은 수의 요청을 처리하도록스케일링이 가능하며
S3에서 첫 바이트를 얻기까지 100-200ms 정도로지연 시간이 굉장히 짧습니다.- 요청으로 환산하면
접두어 및 초당 3,500개의 PUT/COPY/POST/DELETE 요청을 처리하며
접두어 및 초당 5,500개의 GET/HEAD 요청을 버킷 내에서 처리하는 속도입니다.
- 요청으로 환산하면
- 버킷 내의
접두어의 개수에는제한이 없습니다.
S3 KMS Limitmation
- KMS 암호화하는 경우 KMS 제한에 의해 영향을 받을 수 있습니다.
- 파일을 업로드하면,
KMS Limitmation이GenerateDataKey KMS API를호출할 것입니다. - SSE-KMS를 통해 S3에서 파일을 다운로드하는 경우에는
Decrypt KMS-API를호출하게 됩니다. - KMS는 기본적으로 초당 요청에 대한 할당량을 가지고 있습니다.
- 이보다 많은 양이 필요한 경우에는 서비스 할당량 콘솔을 통해 할댱량 증가를 요청할 수 있습니다.
S3 Performance

- Multi-part Upload (분할 업로드)
- 100MB가 넘는 파일은 분할 업로드가 권장
- 5GB가 넘는다면 분할 업로드가 필수입니다.
- 병렬화를 통해 전송 속도를 높이고 대역폭을 극대화합니다.
- S3 Transfer Acceleration
- 업로드와 다운로드를 위한 것입니다.
- 파일을 AWS의 엣지 로케이션으로 파일을 전송함으로써 전송속도를 높입니다.
- 엣지 로케이션에서는 데이터를 대상 리전의 S3 버킷으로 보내 줍니다.
- Transfer Acceleration은 분할 업로드와 호환됩니다.
S3 Byte-Range Fetch
- 파일의 특정 바이트 범위를 얻어 GET를 마비시키는 방식입니다.
바이트 범위를 얻는 데 실패한 경우- 작은 바이트 범위를 얻는 작업을 다시 시도함으로써
실패에 대한 복원성을 가지게 되므로 이 방식은 다운로드의 속도를 높이는 데에 사용됩니다.
- 작은 바이트 범위를 얻는 작업을 다시 시도함으로써
파일의 일부를 회수하는 경우- 만약 S3에 있는 파일의 첫 50바이트가 파일에 대한 정보를 제공하는 헤더라는 사실을 알고 있다면 헤더 요청을 바로 보낼 수 있습니다.
헤더에 해당하는 첫 50바이트를 바이트 범위 요청으로 전송함으로써 해당 정보를 빠르게 얻을 수 있을 겁니다.
- 만약 S3에 있는 파일의 첫 50바이트가 파일에 대한 정보를 제공하는 헤더라는 사실을 알고 있다면 헤더 요청을 바로 보낼 수 있습니다.
S3 Select 및 Glacial Select
- 적은 데이터, 즉 요청한 데이터의 하위 세트를 SQL을 통해 서버 측 필터링을 수행하여 회수하려 하는 것입니다.
- SQL의 쿼리는 행과 열로 필터링하는 데에만 사용됩니다.
- 클라이언트 측에서는 네트워크와 CPU 비용이 절감됩니다.
- S3가 선택과 필터링을 해서 필요한 것만을 전달합니다.
- S3에서의 서버 측 데이터 필터링을 줄이려면 S3 Select와 Glacier Select를 떠올리세요.
- Glacier에서도 작동하는 기능입니다 쿼리가 좀 더 복잡한 경우
S3에서 무서버로 처리되는데 이후의 강의에서 다룰 Amazon Athena입니다.
- Glacier에서도 작동하는 기능입니다 쿼리가 좀 더 복잡한 경우
S3 Event Notification
- 객체가
생성,삭제,복원및복제가 발생한 경우. - 이벤트를 필터링할 수도 있습니다.
- Amazon S3에서 발생하는 특정 이벤트에 자동으로 반응하게 할 수 있습니다.
- SNS, SQS, Lambda 함수
- 원하는 만큼 S3 이벤트를 생성하고 원하는 대상으로 보낼 수 있습니다.
- 이벤트가 대상에 전달되는 시간은
일반적으로 몇 초밖에 안 걸리지만 가끔 1분 이상 걸릴 수도 있습니다.
Amazon EventBridge
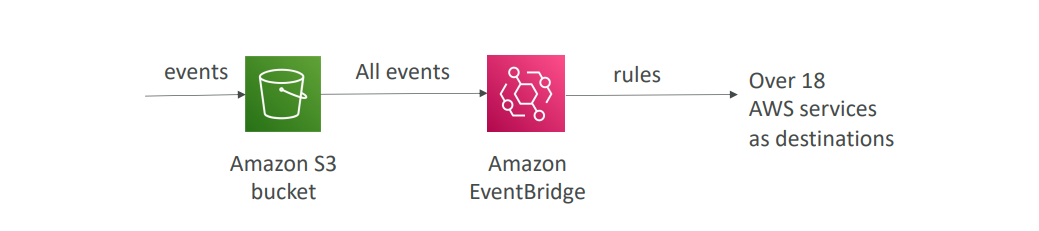
- S3 이벤트 알림 기능을 크게 향상시켜 줍니다.
- 고급 필터링 옵션을 이전보다 훨씬 더 많이 사용할 수 있습니다. (JSON)
- 동시에 여러 수신지에 보낼 수도 있습니다.
- Amazon EventBridge에서 제공하는 기능을 사용할 수도 있습니다.
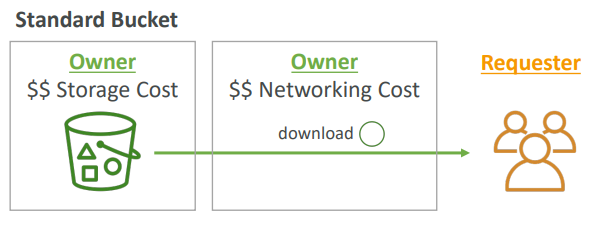
S3 요청자 지불
- 일반적으로는
버킷 소유자가 버킷과 관련된 모든 Amazon S3 스토리지 및 데이터 전송 비용을 지불합니다.
예를 들어 봅시다
버킷 셋이 있고 그 안에 객체를 보관하고 있습니다.
그리고 요청자, 즉 사용자가 버킷으로부터 파일을 다운로드합니다.
그러면 네트워킹 비용 역시 버킷 및 객체 소유자에게 청구됩니다.그러나 수많은 대형 파일이 있고 일부 고객이 이를 다운로드하려고 하면
여러분은 요청자 지불 버킷을 활성화 해야 할 겁니다
- 이 경우 버킷 소유자가 아니라 요청자가 객체 데이터 다운로드 비용을 지불합니다.
다시, 예를 들어 봅시다
소유자가 여전히 버킷의 객체 스토리지 비용을 부담하겠지만
요청자가 객체를 다운로드하면 이제 그 요청자가 다운로드와 관련된 네트워킹 비용을 지불하게 됩니다._대량의 데이터 셋을 다른 계정과 공유하려고 할 때 매우 유용합니다.
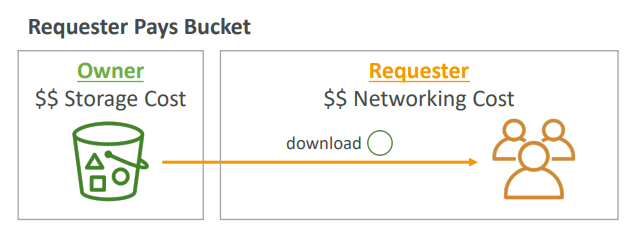
- 그렇게 하려면 요청자가 익명이어서는 안됩니다_
- 요청자가 AWS에서 인증을 받아야 합니다.
Glacier Vault lock
- 이는 한 번 쓰고 여러 번 읽는 WORM 모델을 적용하기 위함입니다.
- 미래의 편집에 대한 정책을 잠금으로써 더 이상 변경될 수 없도록 하는 것입니다.
규정 준수와데이터 보존을 위해 이 방식을 사용합니다
S3 Object Lock (객체 잠금)
- WORM 모델을 적용합니다.
- 이는 특정 시간 동안의 객체 버전 삭제를 막습니다.
- 객체 보존을 위한 두 가지 옵션
- Retention Period
- 특정 기간 동안 객체를 잠금니다.
- Legal Hold
- 객체 보존 만료일이 정해지지 않습니다.
- Retention Period
- S3 객체 잠금의 모드 측면
- 거버넌스 모드
- 사용자에게 특별한 권한이 부여되지 않았다면 객체 버전을 무효화 또는 삭제하거나 잠금 설정을 변경할 수 없도록 하는 것입니다.
- 규정 준수 모드
- AWS 계정의 루트 사용자를 포함한 어떤 사용자도 보호된 객체 버전을 무효화하거나 삭제할 수 없도록 하는 것입니다.
보존 모드를 변경할 수 없고보존 기간도 단축할 수 없습니다.- 객체에 대한 보다 높은 수준의 제한입니다.
- 거버넌스 모드
Amazon Athena
- 아마존 S3에 저장된 객체에 대해
분석을 수행하는 서버리스 쿼리 서비스입니다.- SQL 언어로 이러한 파일들을 쿼리합니다.
- 파일의 포맷은 CSV, JSON, ORC, Avro, Parquet 등 다양합니다.
- Athena의 가격은 스캔된
데이터 TB당 5달러입니다. - 압축되거나 컬럼형으로 저장된 데이터를 사용할 경우 비용을 절감할 수 있습니다.
- 사용 사례
- 비즈니스 인텔리전스 분석
- 보고 VPC
- ELB 로그의 Flow Logs 분석
시험에서 SQL 사용, 데이터 분석 서버리스 등의 키워드가 나오면
Amazon Athena를 생각해 보시면 됩니다

클라우드, 데이터, DevOps 엔지니어 지향 || 글보단 사진 지향