
UDF와 저장 프로시저
UDF (User-Defined Function)와저장 프로시저(Stored Procedure)는 데이터베이스 시스템에서 코드를 저장하고 실행하는 데 사용되는 두 가지 주요 개체입니다.
그러나 각각의 목적과 사용법이 다릅니다.
User-Defined Function
UDF를 사용하면,
Snowflake가 제공하는 기본 제공 시스템 정의 함수를 통해 사용할 수 없는 일부 작업을 수행할 수 있습니다.
목적
값을 반환하는 함수
특정 계산이나 로직을 수행하고 그 결과를 호출자에게 반환
일반적으로 SELECT 문에서 사용되어 특정 계산을 수행하거나 데이터를 변환
작성하는 방법
CREATE [ OR REPLACE ] [ { TEMP | TEMPORARY } ] [ SECURE ] FUNCTION [ IF NOT EXISTS ] <name> (
[ <arg_name> <arg_data_type> [ DEFAULT <default_value> ] ] [ , ... ] )
[ COPY GRANTS ]
RETURNS { <result_data_type> | TABLE ( <col_name> <col_data_type> [ , ... ] ) }
[ [ NOT ] NULL ]
LANGUAGE PYTHON
[ { CALLED ON NULL INPUT | { RETURNS NULL ON NULL INPUT | STRICT } } ]
[ { VOLATILE | IMMUTABLE } ]
RUNTIME_VERSION = <python_version>
[ COMMENT = '<string_literal>' ]
[ IMPORTS = ( '<stage_path_and_file_name_to_read>' [ , ... ] ) ]
[ PACKAGES = ( '<package_name>[==<version>]' [ , ... ] ) ]
HANDLER = '<function_name>'
[ EXTERNAL_ACCESS_INTEGRATIONS = ( <name_of_integration> [ , ... ] ) ]
[ SECRETS = ('<secret_variable_name>' = <secret_name> [ , ... ] ) ]
AS '<function_definition>'EXAMPLE.
CREATE OR REPLACE FUNCTION add_numbers(x int, y int)
RETURNS int
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
HANDLER = 'add_numbers_py'
AS
$$
def add_numbers_py(x, y):
return x + y
$$;
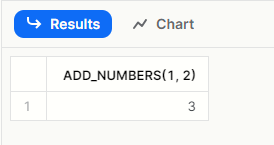
SELECT add_numbers(1, 2);UDF는 일반적으로 SELECT 문에서 사용됩니다.
저장 프로시저
저장 프로시저는
특정 작업 또는 일련의 작업을 수행하는 프로그램 단위로,
반환 값이 없을 수도 있습니다.
목적
주로 데이터베이스에서 데이터를 수정하거나 조작하는 데 사용됩니다.
작성하는 방법
매우 복잡하여 요약이 되지 않는다.
EXAMPLE
CREATE OR REPLACE TABLE employees(id NUMBER, name VARCHAR, role VARCHAR);
INSERT INTO employees (id, name, role) VALUES (1, 'Alice', 'op'), (2, 'Bob', 'dev'), (3, 'Cindy', 'dev');
CREATE OR REPLACE PROCEDURE filterByRole(tableName VARCHAR, role VARCHAR)
RETURNS TABLE(id NUMBER, name VARCHAR, role VARCHAR)
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python')
HANDLER = 'filter_by_role'
AS
$$
from snowflake.snowpark.functions import col
def filter_by_role(session, table_name, role):
df = session.table(table_name)
return df.filter(col("role") == role)
$$;
CALL filterByRole('employees', 'dev');
결론
UDF와 저장 프로시저는 각각의 목적에 맞게 선택되어야 합니다.
UDF는 주로 데이터 변환 및 계산에 사용되며,
저장 프로시저는 주로 데이터 조작이나 프로시저 내에 로직이 필요한 작업에 사용됩니다.

클라우드, 데이터, DevOps 엔지니어 지향 || 글보단 사진 지향