
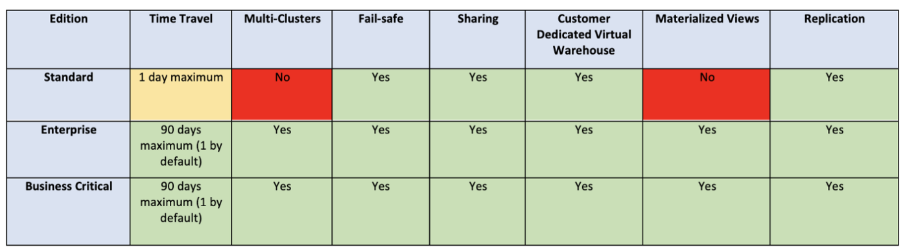
요금제 비교

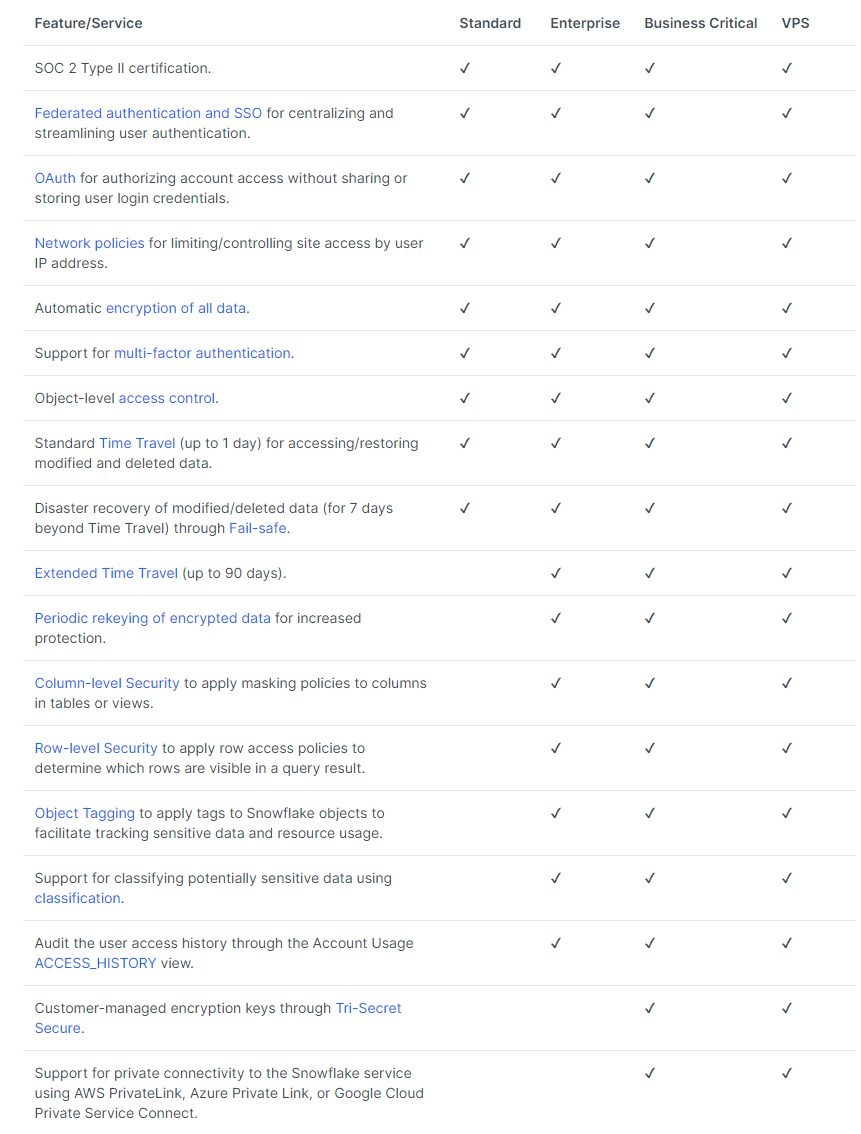
Warehouse 정책

File Format

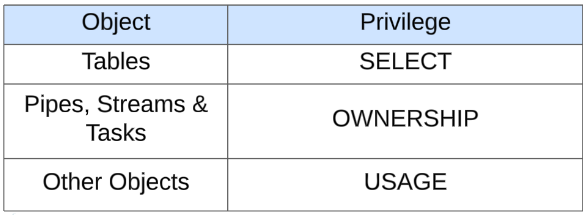
Clone시 필요한 권한 (Privileges)
Micro-Partitioning의 이점
기존의 정적 파티션과 달리,
마이크로 파티션은 사용자가 사전에 명시적으로 정의하거나 유지 관리할 필요가 없으므로 자동으로 파생됩니다.
마이크로 파티션은 크기가 작으며(50~500MB, 압축 전), 이를 통해 매우 효율적인 DML 및 세분화된 Pruning을 통해 보다 빠른 쿼리를 수행할 수 있습니다.
마이크로 파티션은 값 범위가 겹칠 수 있으며 균일하게 작은 크기와 결합하여 skew를 방지하는 데 도움이 됩니다.
컬럼은 종종 컬럼 저장소라고 하는 마이크로 파티션 내에 독립적으로 저장됩니다.
- 이렇게 하면 개별 열을 효율적으로 검색할 수 있으며,
쿼리에 의해 참조되는 열만 검색됩니다.
마이크로 파티션은 불변하는 객체이며, Time Travel이 서포트 한다.
마이크로 파티션은 객체 저장소에서 가상 웨어하우스로에 I/O 양을 줄일 수 있다.
Run a Query
Default Time
2 days
MAXIMUM TIME
7 days
Directory Table
스테이지 상에 계층화된 암묵적 객체인 Snowflake 테이블
- (not a separate database object)
- (A directory table has no grantable privileges of its own.)
표준 SQL 문을 사용하여 스테이지 내 파일의 메타데이터 및 내용을 조회할 수 있습니다.
FILE URL 사용된다.
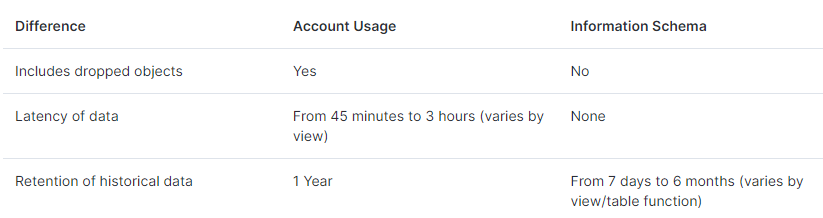
Account Usage
당신의 계정과 모든 reader 계정 포함하여
historical usage data 포함, 객체 메타데이터 쿼리 가능
View의 기간 : 1년
Dropped된 객체의 Records는 각 View에 포함된다.
Data Latency : 45분 ~ 3시간
Schemas
- ACCESS_HISTORY
- QUERY_HISTORY
- COPY_HISTORY
- FILE_FORMATS
- LOAD_HISTORY
등등...왠만한 정보는 모두 갖추고 있다.
Differences Between Account Usage and Information Schema
Masking Policies in ACCOUNT_USAGE
MASKING POLICIES
POLICY_REFERENCES
RESOURCE_MONITORS VIEW
This view is only available in the READER_ACCOUNT_USAGE schema.
Which Permission for Warehouse Resize
MODIFY
OTHERS
- MONITOR
- OPERATE
- USAGE
Materialized View
Snowflake내에서 자동으로 명백하게 View의 내용을 갱신한다.
- 오직 하나의 테이블만 쿼리할 수 있다.
- Self-Join을 포함해, Join을 지원하지 않는다.
- UDF, Window functions, HAVING, ORDER BY, LIMIT, Group By, Nesting Subqueries, Minus, EXCEPT, INTERSECT를 포함하지 못한다.
- 많은 집계함수를 허용하지 않는다.
COPY INTO시, 다중 파일로...
SINGLE = FASLE 옵션 설정
Search Optimization Service
특정 유형의 룩업 및 분석 질의의 성능을 크게 향상시킬 수 있는 기능
특정 쿼리의 성능 향상이 목적
- Selective Point Lookup queries
- Substring, Regular Expression search
다음 Predicates를 사용하는
VARIANT, OBJECT, and ARRAY (semi-structured) 열의 필드에 대한 쿼리
- Equality predicates.
- ARRAY_CONTAINS
- ARRAYS_OVERAP
- CHECK NULL
Search Access Path라는 데이터 구조 생성
- 테이블을 스캔할 때 일부 마이크로 파티션을 건너뛸 수 있도록
테이블의 각 마이크로 파티션에서 찾을 수 있는 열 값을 추적합니다.
테이블에 해당 서비스를 추가 및 삭제하려면...
You must have OWNERSHIP privilege on the table.
You must have ADD SEARCH OPTIMIZATION privilege on the schema that contains the table.
Search Optimization Service는 마이크로 파티션의 데이터 구성과는 무관합니다.
Data Exchange
Data Exchange는 선택한 구성원 그룹 간의 데이터를 안전하게 공동 작업할 수 있는 자체 데이터 허브입니다.
Granting administrator privileges in a Data Exchange
Data Exchange 관리자 계정
계정 관리자 (ACCOUNTADMIN Role을 가진 사용자)가
Data Exchange를 관리할 수 있다.
- 멤버 추가 및 삭제
- 승인 목록 요청 승인 및 거부
- 프로필 승인 요청 승인 및 거부
- 카테고리 보여주기
Clustering keys
클러스터링 키는 DML 작업을 차단하지 않고
시간이 지남에 따라 지정된열을 정렬한다.
Why Flattening?
Better Pruning and Less Storage Consumption
다음 데이터를 포함한다면,
객체 및 주요 데이터를 별도의 관계 열로 평탄화
- 날짜와 Timestamp
- 문자열이 포함된 숫자
- Array (배열)
Inbound Shares in Snowflake Account
2개,
ACCOUNT_USAGE, SAMPLE_DATA shares
Resource Monitor를 서포트하는 동작
Notify
Notify and Suspend
Notify and Suspend Immediately
Network Policy
Account, User can be set
BLOCKED IP ADDRESS LIST FIRST
다른 계정끼리의 공유
Zero-Copy Cloning은 다른 계정끼리 공유할 수 없다.
따라서, Data Sharing을 사용해야한다.
ACCESS_HISTORY retain
365 days
Result Cache
RESULT_SCAN 테이블 함수는
Query Result Cache에 접근 및 필터링을 할 수 있다.
ORGADMIN
계정을 생성 및 관리하는 역할,
웹 인터페이스 또는 SQL를 통해,
Commands are not blocking operation
COPY, INSERT
- 해당 명령줄은 리소스를 Lock하지 않는다.
Query Profile
Query의 세부 정보를 제공한다.
Query Profile helps ---
- Join 폭발
- ALL 없는 UNION
- 메모리에 맞추기에 너무 큰 쿼리 (Spilling)
- 비효율적인 가지치기 (Pruning)
데이터 공유 시,
다른 리전, 다른 CSP = Replication
URL
파일 접근을 가능하게 한다.
Scoped URL
Stage에 대한 권한 승인 없이 Staged 파일에 대한 임시 접근 가능
- 지속된 쿼리 결과 기간이 종료되면 URL이 만료됩니다. 24시,
- Scoped URL을 생성한 사용자만이 접근할 수 있다.
FILE URL
파일 집합에 대한 데이터베이스, 스키마, 스테이지 및 파일 경로를 식별하는 URL
- Stage에서 충분한 권한을 가진 Role만 파일에 액세스할 수 있습니다.
Pre-Signed URL
웹 브라우저를 통해 파일에 액세스하는 데 사용되는 단순 HTTPS URL.
- 미리 서명된 액세스 토큰을 사용하여 이 URL을 통해 사용자가 파일에 임시로 액세스할 수 있습니다.
- 액세스 토큰의 만료 시간은 구성 가능합니다.
Task로 다중 SQL문 실행하기.
다중 SQL문을 실행하는
저장 프로시저를 사용하고
Task로 해당 저장 프로시저를 실행한다.CREATE TASK mytask .... AS call stored_proc_mulitiple_statements_inside();
