list comprehensions
리스트 컴프리헨션을 사용하면 가독성이 좋아지는 장점도 있지만 일반적인 for문을 사용해서 리스트를 만들때보다 출력되는 속도가 빨라지는 장점이 있다.
1.다음과 같은 도시목록의 리스트가 주어졌을때, 도시이름이 S로 시작하지 않는 도시만 리스트로 만들 때 리스트 컴프리헨션을 사용하여 함수를 작성해 보세요.
cities = ["Tokyo", "Shanghai", "Jakarta", "Seoul", "Guangzhou", "Beijing", "Karachi", "Shenzhen", "Delhi" ]
cities_no_s = [ i for i in cities if i[0] != 'S']
print(cities_no_s)2.다음과 같은 도시, 인구수가 튜플의 리스트로 주어졌을때, 키가 도시, 값이 인구수인 딕셔너리를 딕셔너리 컴프리헨션을 사용한 함수를 작성해 보세요.
population_of_city = [('Tokyo', 36923000), ('Shanghai', 34000000), ('Jakarta', 30000000), ('Seoul', 25514000), ('Guangzhou', 25000000), ('Beijing', 24900000), ('Karachi', 24300000), ( 'Shenzhen', 23300000), ('Delhi', 21753486) ]
dict_info_city = {population_of_city[i][0]:population_of_city[i][1] for i in range(len(population_of_city))}
print(dict_info_city)1번, 2번 출력값

이터레이터
이터레이터는 값을 순차적으로 꺼내올 수 있는 객체 입니다.
기본적으로 리스트에는 iter 함수가 존재한다.
만약 l = [1,2,3] 이라는 리스트가 있다고 가정하고 dir(l)을 입력하면 아래와 같이 리스트에 어떠한 함수가 있는지 확인해 볼 수 있는데, iter가 목록에 있는것을 확인할 수 있다.
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']__iter__() 함수를 출력해보면
print(l.__iter__())
<list_iterator object at 0x7fd0ed1c9f10>
이터레이터 객체임을 확인할 수 있다.
그리고 L2 = l.__iter__() 이터레이터를 변수에 담고 dir를 확인해보면
print(dir(L2))
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
print문으로 확인해보면 next 함수가 들어있는 것을 확인할 수 있다. __next__ 함수는 이름처럼 다음 요소를 하나씩 꺼내오는 함수이다.
__next__함수를 호출하면서 동작을 확인해보면, 리스트안에 1,2,3 3개의 값이 들어있으므로 3번이상 호출한다.
print(iterator_L.__next__())
print(iterator_L.__next__())
print(iterator_L.__next__())
print(iterator_L.__next__())1,2,3 이 출력되고 StopIteration 이 발생하는 것을 확인할 수 있다. 즉, 리스트의 인덱스를 벗어나서 가져올 값이 없으면 StopIteration이 발생하는 것을 알 수 있다.
딕셔너리도 반복가능한 객체라서 앞서본 리스트와 같이 iter함수와 next함수를 사용할 수 있고 파이썬 기본함수인 iter, next 또한 사용할 수 있습니다. 다음의 간단한 키를 출력하는 딕셔너리에 대한 for 문을 while문으로 구현해 보세요.
D = {'a':1, 'b':2, 'c':3}
for key in D.keys():
print(key)코드:
d = iter(D)
while True:
try:
i = next(d)
except StopIteration:
break
print(i, end=' ')이렇게 while문으로 구현을 해보면 StopIteration이 발생 했을때 break 시켜주면 a b c 가 출력되는것을 확인할 수 있다.
제너레이터
파이썬에서 보통의 함수는 값을 반환하고 종료 하지만 제너레이터 함수는 값을 반환하기는 하지만 산출(yield)한다는 차이점이 있다. 그리고 제너레이터는 쉽게 얘기하면 이터레이터를 생성해주는 함수라고도 볼 수 있다.
다음 코드를 보면 함수안에서 yield를 사용하여 리스트의 제곱을 산출하는 함수가 있고, 이 함수를 print문으로 확인해보면 generator object 임을 확인할 수 있다.

아래의 코드를 분석해보겠습니다.

리스트 컴프리헨션으로 출력했을때와 제너레이터로 출력했을때의 차이점은?
L = [ 1,2,3] 가 있다고 가정해보면,
comprehension_list=
sleep 1s
sleep 1s
sleep 1s
1
2
3
generator_exp=
sleep 1s
1
sleep 1s
2
sleep 1s
3
두개의 출력값이 다르다는것을 확인할 수 있는데 컴프리헨션 리스트인 경우에는 lasy_return이 3번 출력되면서 return 되는 num을 리스트에 저장시킨 후 print_iter 함수를 통해서 한번에 출력된다.
반면에 제너레이터는 값을 저장하지 않고 한번씩 번갈아 가면서 출력되는것을 볼 수 있다. 쉽게 말하면, lazy_return 을 통해서 1이 출력이 되면 바로 print_iter에 1을 대입시켜 출력하고 다시 lazy_return 값을 출력시켜 2의 값을 바로 print_iter 함수에 대입해 한번씩 번갈아 가면서 값을 출력 시킨다. 이 반복을 리스트 길이 만큼 반복한다.
제너레이터를 사용하는 이유는 무엇일까?
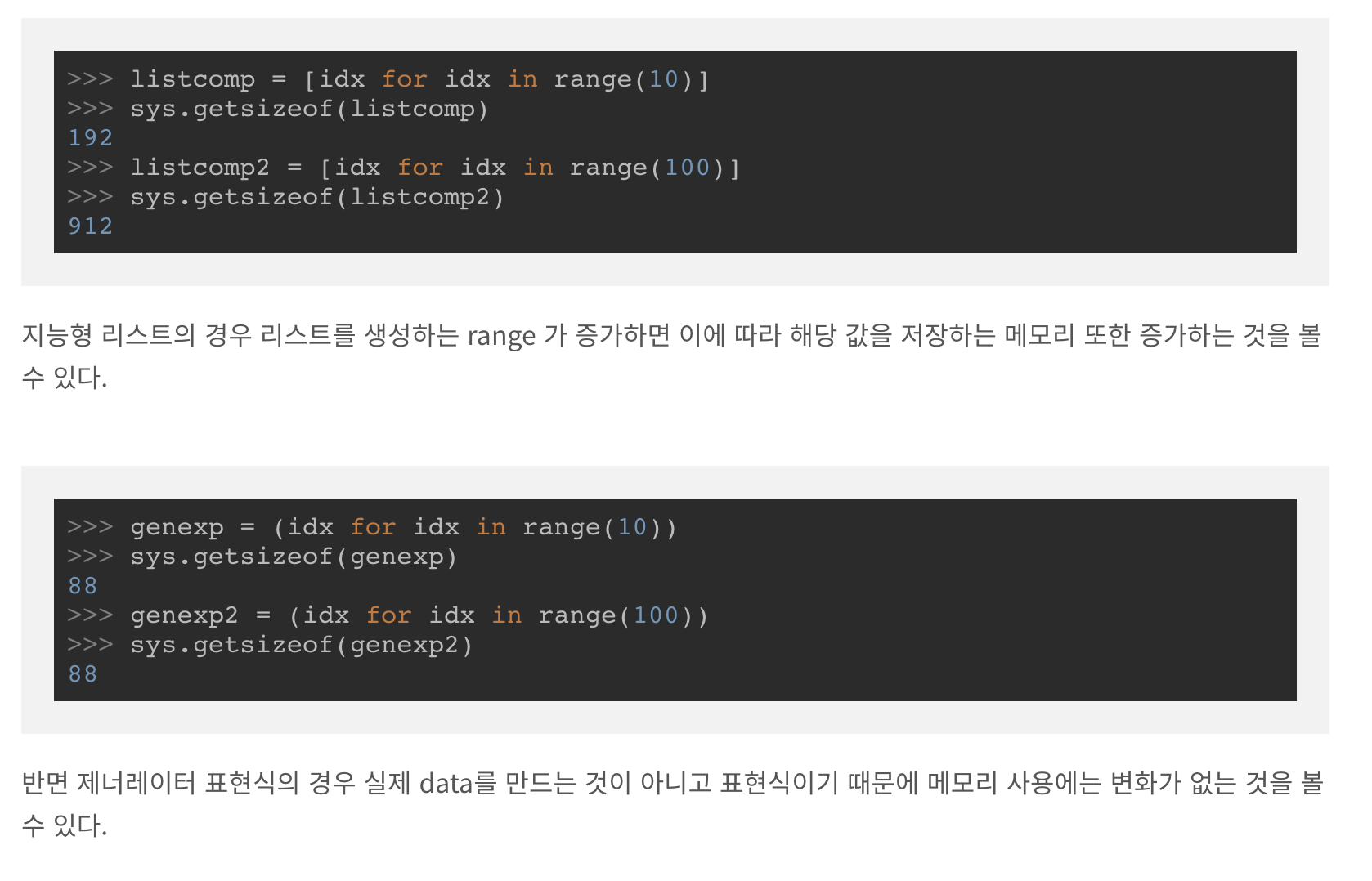
위에서 처럼, 리스트 컴프리헨션을 사용했을때와 제너레이터를 사용했을때의 메모리 사용값을 확인해보면 제너레이터는 실제 데이터를 만드는것이 아니기 때문에 10개, 100개, 1000개의 값들을 넣어도 리스트 컴프리헨션과 달리 메모리 사용이 증가하지 않는것을 확인할 수 있다.
lambda expressions
람다는 인라인 함수를 정의할 때 사용하며 익명 함수(anonymous functions) 또는 람다 표현식(lambda expression)이라고 부른다.
람다 표현식을 잘 사용하면 코드가 깔끔해지는 장점이 있다.
다음과 같이 비밀번호의 길이와 대문자가 포함된것을 확인하는 간단한 함수가 있다.

이함수에 있는 if문 두개를 람다표현식을 이용하여 다음과 같은 형식으로 작성해 보세요.
아래의 lambdas 리스트안에 두개의 람다표현식을 작성해야하며 주석으로 표시된 프린트가 출력결과로 나와야 합니다.

람다의 기본 문법:

lambdas = [lambda x: "SHORT_PASSWORD" if len(x) < 8 else None,
lambda x: "NO_CAPITAL_LETTER_PASSWORD" if not any(c.isupper()
for c in x) else None]이렇게 람다 식으로 코드를 작성하면 print값이 잘 나온다.
SHORT_PASSWORD
NO_CAPITAL_LETTER_PASSWORD
True
