브랜디를 소개합니다
브랜디는 20대 여성을 위한 쇼핑앱이다. 여성쇼핑앱에 그치지 않고 남성쇼핑앱 '하이버', 패션 창업인큐베이팅 서비스 '헬피'까지 서비스하며 사업 영역을 확장했다. 동대문 D2C(Direct to Consumer) 플랫폼 트랜디까지 동대문 패션 사업에 적극적으로 뛰어들고 있는 기업이다.
업계 최초로 100명 규모의 개발자 채용을 선언하는 등 빠른 성장을 이루고 있는 회사이다.
프로젝트 정보
총 4명의 백엔드 개발자가 한 팀이 되어 1달간 프로젝트를 진행했다. Flask를 이용하여 'Brandi' 서비스&어드민 페이지 구현했다. 프론트엔드 개발자는 참여하지 않았기 때문에 모든 프론트 구현은 팀장께서 혼자서 하셨다.
진행기간 : 2021.05.10 ~ 2021.06.03
팀원: 백승찬,김현영,서득영,이서진
깃허브 주소
서비스 페이지: https://github.com/poketsc/brandi-service
어드민 페이지: https://github.com/poketsc/brandi-admin
기술스택
Framework
- Flask(1.1.2)
Language
- Python(3.8)
DB
- Mysql
- 로컬 데이터베이스
ERD
- AqueryTool
Communication
- Github
- Slack
- Notion
통신
- Postman
우리팀이 구현한 기능
서비스
- 로그인
- 메인페이지
- 상품상세
- 장바구니
- 배송지
- 주문
- 주문완료
어드민
- 로그인
- 셀러가입
- 회원 관리 > 셀러 계정 관리 (마스터)
- 회원 관리 > 셀러 정보 수정
- 상품 관리 > 상품 등록
- 상품 관리 > 상품 관리
- 상품 관리 > 상품 관리 > 판매, 진열 적용
- 주문 관리 > 상품 준비 관리
- 주문 관리 > 상품 준비 관리 > 배송 처리
- 주문관리 > 주문상세
내가 구현한 기능
서비스
- 상품상세
- 장바구니
- 배송지
- 주문
- 주문완료
진행방식
이번 인턴쉽 프로젝트에서도 다른 프로젝트때와 마찬가지로 Agile(애자일)의 대표 관리 Practice인 Scrum(스크럼) 방법으로 프로젝트를 진행하였다. Scrum은 특정 개발 언어나 방법론에 의존적이지 않으며, 제품 개발 뿐만 아니라 일반적인 프로젝트 관리에도 사용 가능한 프로세스 프레임워크이다. Scrum은 작은 주기(Sprint)로 개발 및 검토를 하며 효율적인 협업 방법을 제공한다. 정보처리기사 공부를 할때 Waterfall 방식과 애자일 방식을 배웠던 기억이 난다. 이번 인턴쉽 프로젝트가 내가 한 다른 프로젝트와 달랐던 점은 백엔드개발자만 있었다는 점이다. 프론트엔드 기능은 전부다 구현이 되어있었기 때문에 우리가 API를 모두 프론트와 통신할수 있었다. 우리 팀은 매일 아침 9시 30분에 만나서 15분~20분간 회의를 진행하였다. 프로젝트를 시작하고 매주 월요일에 중간점검을 가졌다. 우리가 처음 생각했던 기능들을 다 구현할수 있을지 확인하기 위해서였다.
1주차
우리는 모두 Django 프레임워크만 사용해본 개발자들이였다. 우리는 Flask에 대한 이해가 부족했고 Django와는 다르게 Flask는 아키텍처 패턴부터 전부다 구현해야 했다. 득영님이 Flask의 초기세팅을 담당했다. 득영님이 Flask 초기세팅을 혼자서 했기 때문에 고생을 많이 했다. 서진님이 Postman을 활용해서 프론트와 어떻게 통신해서 결과값을 어떻게 주고 받을지에 대해 문서작업을 했고 현영님과 나는 AqueryTool을 사용해서 데이터 모델링을 했다. 이번 데이터 모델링에서 다른 프로젝트와 달랐던 점은 이력관리를 고려했다는 점이다. 우리는 점이력과 선분이력 중에 어떤 방식으로 이력관리를 할지 고민했고 선분이력을 선택했다. 이번에 점 이력이 아닌 선분이력을 선택한 이유는 시작 시점과 종료 시점을 관리함으로써 과거 특정 시점의 데이터 조회를 손쉽게 할 수 있는 장점이 있기 때문이였다. 이번 데이터모델링은 실제 현업에서 사용하는 방법과 유사하게 구현했다. 이력관리로 인해 테이블의 개수가 2배는 늘어난것 같다.

우리가 구현한 데이터모델링이다. 1주차에 완성한 모델링은 아니다. 기능을 구현하면서 많은 컬럼 추가와 관계 수정이 있었다. 우리는 처음으로 역정규화를 사용했는데 역정규화(denormalization)는 정규화된 데이터베이스에서 성능을 개선하기 위해 사용되는 전략이다. 일부 컬럼의 데이터를 중복 추가함으로써 데이터베이스의 읽기 성능을 개선하려는 의도였다. 팀장님께서 역정규화를 하는데 있어서 명확한 이유가 있어야 한다고 하셨다.
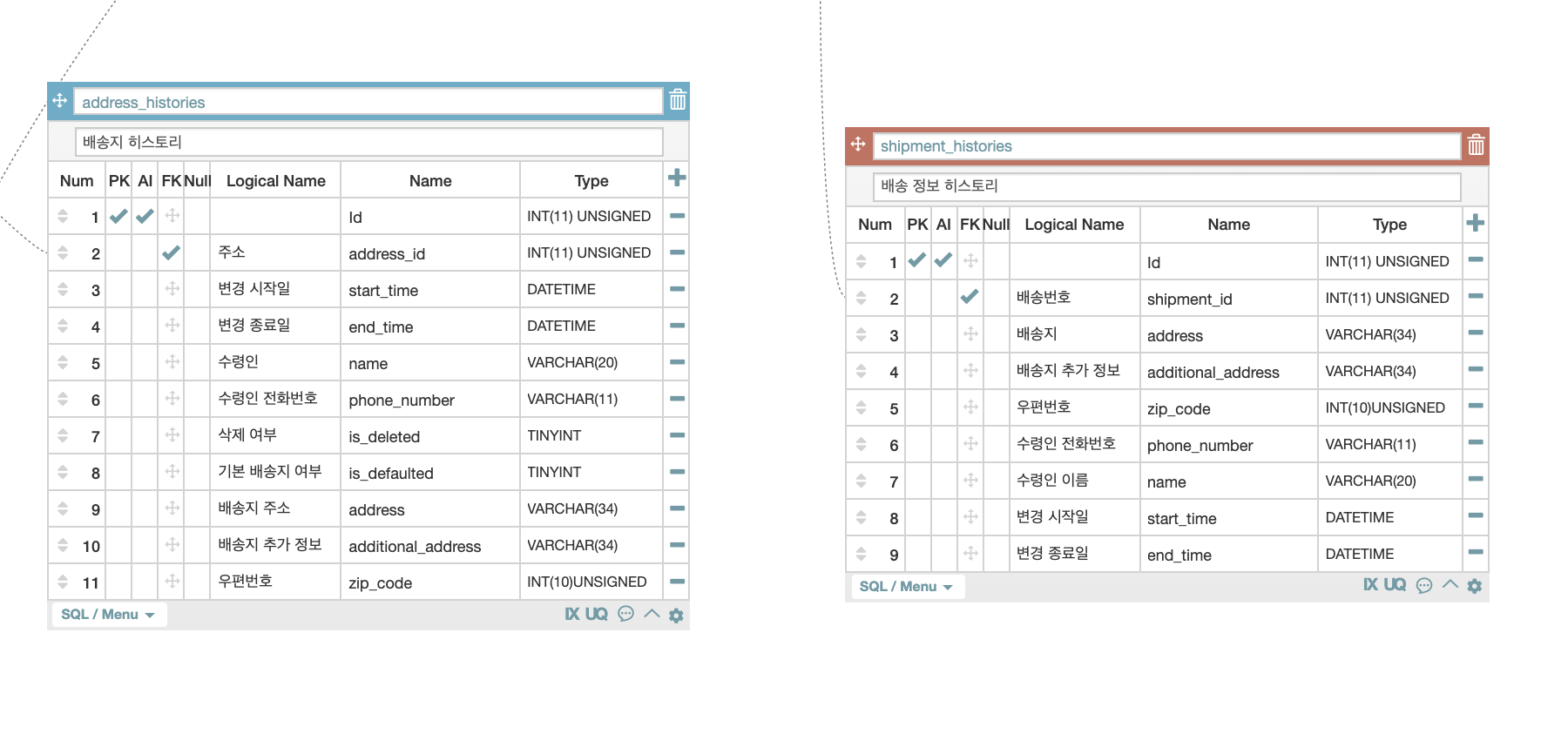
위에 테이블에서 address_histories 테이블에 있는 배송지주소, 배송지추가정보, 우편번호가 shipment_histories 테이블에도 있는것을 볼수있다. shipment_histories에도 똑같은 컬럼을 추가한 이유는 유저가 address 정보를 바꾸면 주문 했을 당시에 주소를 알수가 없어서 중복 추가 했다. 이 역시도 수정을 통해 완성된 모습이다. 한번에 완벽하게 데이터모델링을 하는것은 아직 불가능한것 같다. 많은 경험이 필요한것 같다.
AqueryTool 주소 : https://aquerytool.com:443/aquerymain/index/?rurl=4ee0ca00-2098-427d-b86d-cfad789e32c0
password : 7vu8c5
2주차
Flask 초기세팅, API 문서작업, 데이터 모델링을 끝내고 우리는 API 기능 구현을 시작했다. 백앤드 api의 아키텍처에는 여러가지가 있을것이지만 우리는 가장 널리 사용되는 레이어드 아키텍처에 맞게 프로젝트를 3가지 section으로 나누었다.
view
프로젝트에서 backend endpoint경로를 처리해주는 부분이다. 클라이언트에게서 온 request를 처리했다. db를 열고 닫는다.
service
api에서 로직을 담당하는 영역이다. 프론트로부터 받는 키값에 대한 에러처리를 제외한 대부분의 에러처리는 service영역에서 처리했다.
model
raw query를 사용해서 데이터베이스와 직접적으로 통신하는 영역이다.
내가 처음으로 구현한 API 기능은 장바구니(POST) 였다.
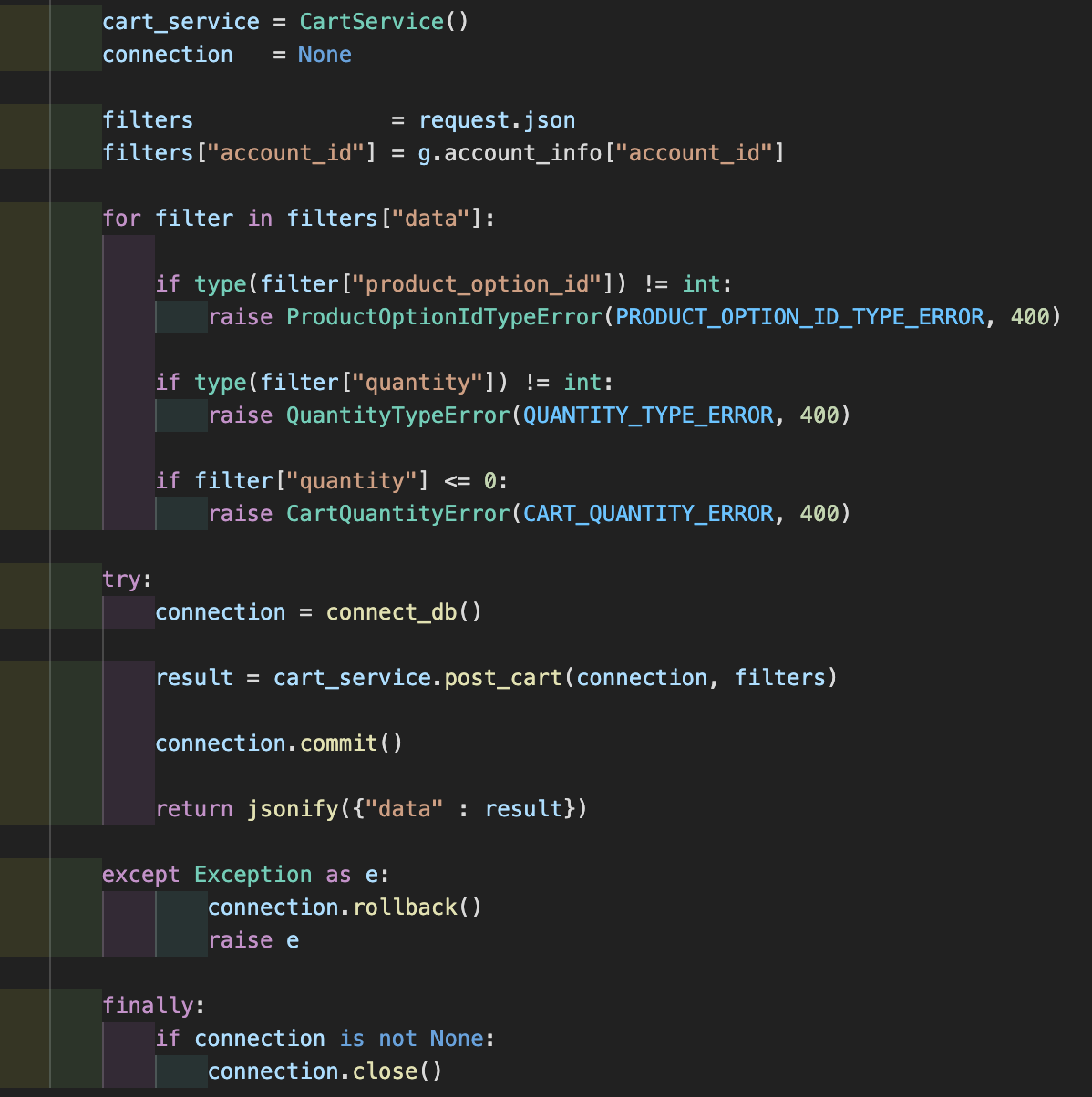
view에서 먼저 프론트로부터 받은 데이터 형식이 올바른지 확인해주었다. 여러개의 상품이 한번에 담길수 있어서 for문으로 각각의 상품에 대한 형식을 체크했다. 그렇게 체크가 끝난후에 db를 열어주고 로직을 담당하는 post_cart 함수를 실행한다.
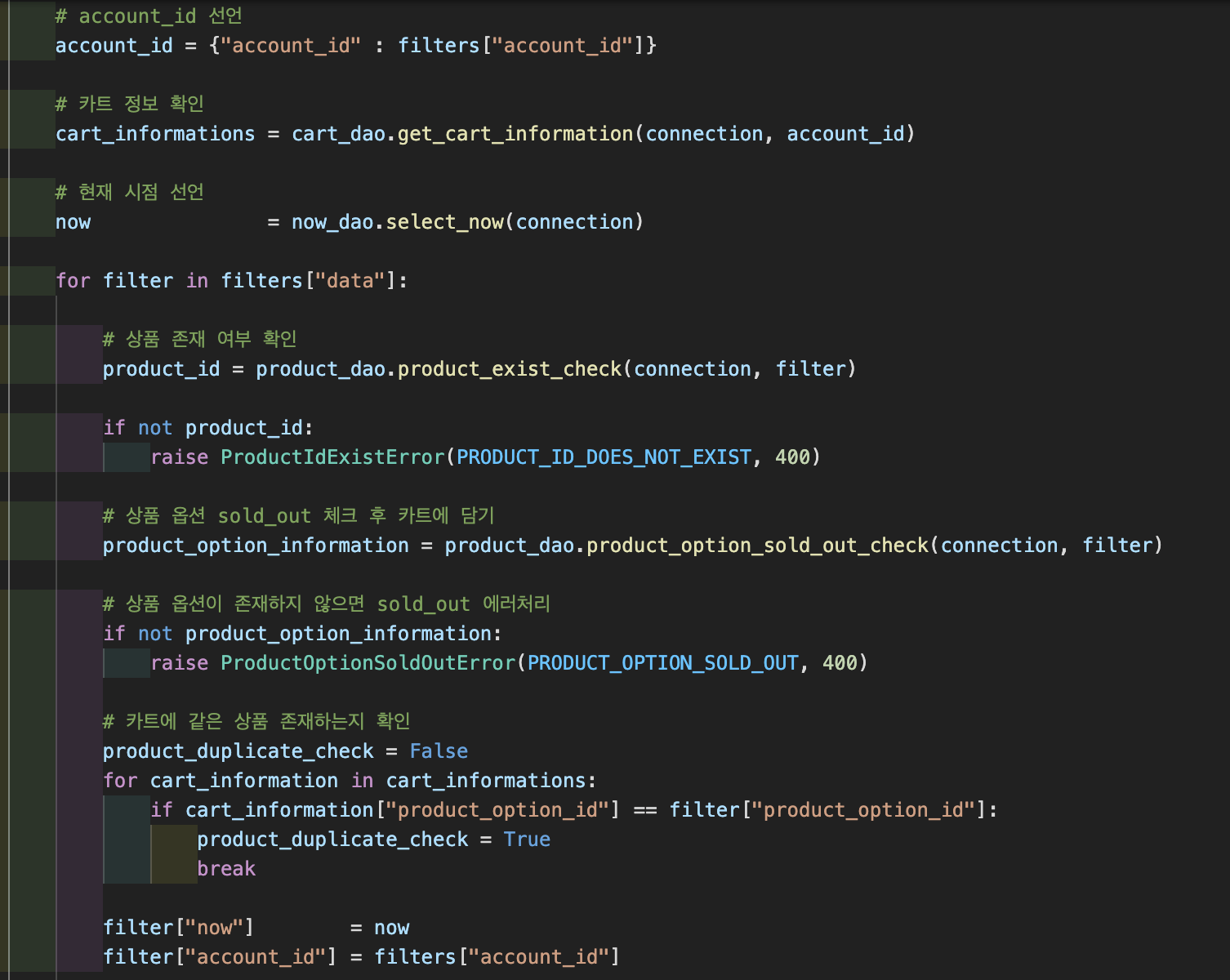
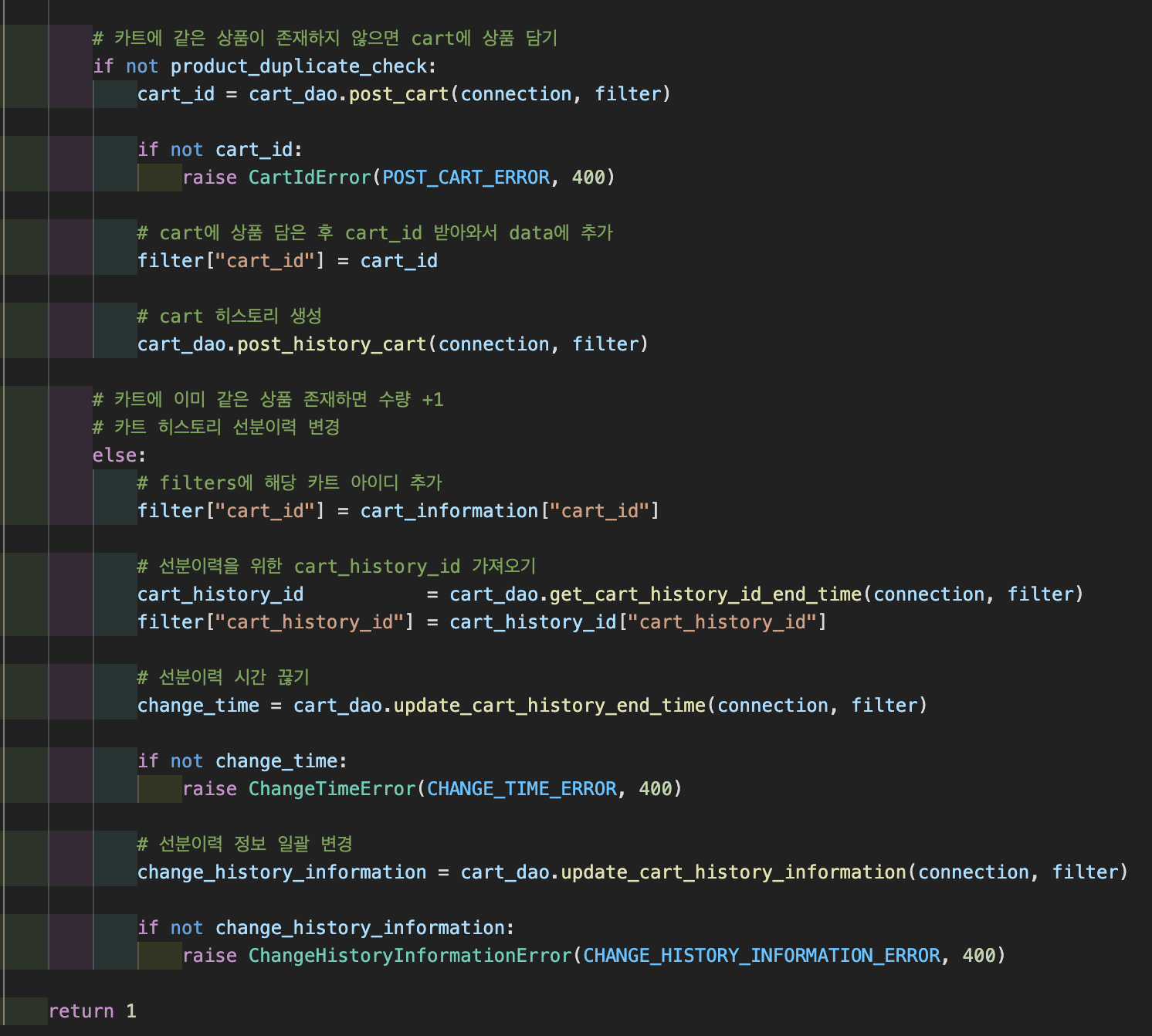
서비스 부분에서는 여러가지 경우의 수가 존재하기 때문에 if, else 문으로 경우의 맞게 처리하였다. 여기서 나는 하나의 dao 에서는 하나의 query문만을 쓰기 위해서 여러개의 dao를 만들어서 호출했다.
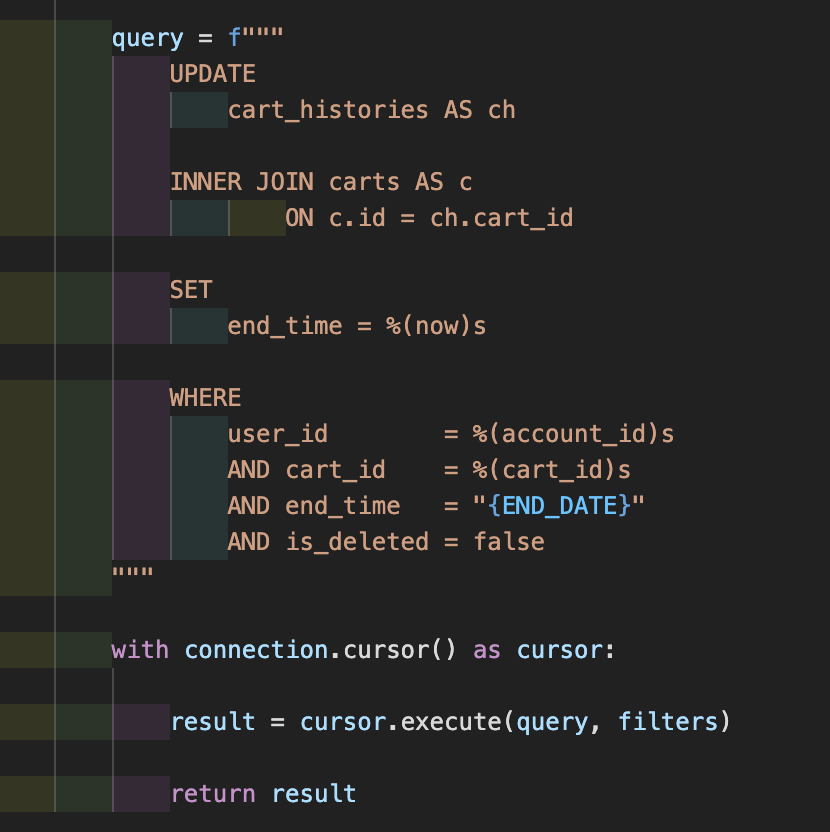
이 코드는 dao에서 선분 이력을 관리하기 위한 코드이다. 장바구니에 같은 상품이 이미 존재하면 시간을 업데이트 하기 위해서 만든 쿼리문이다.
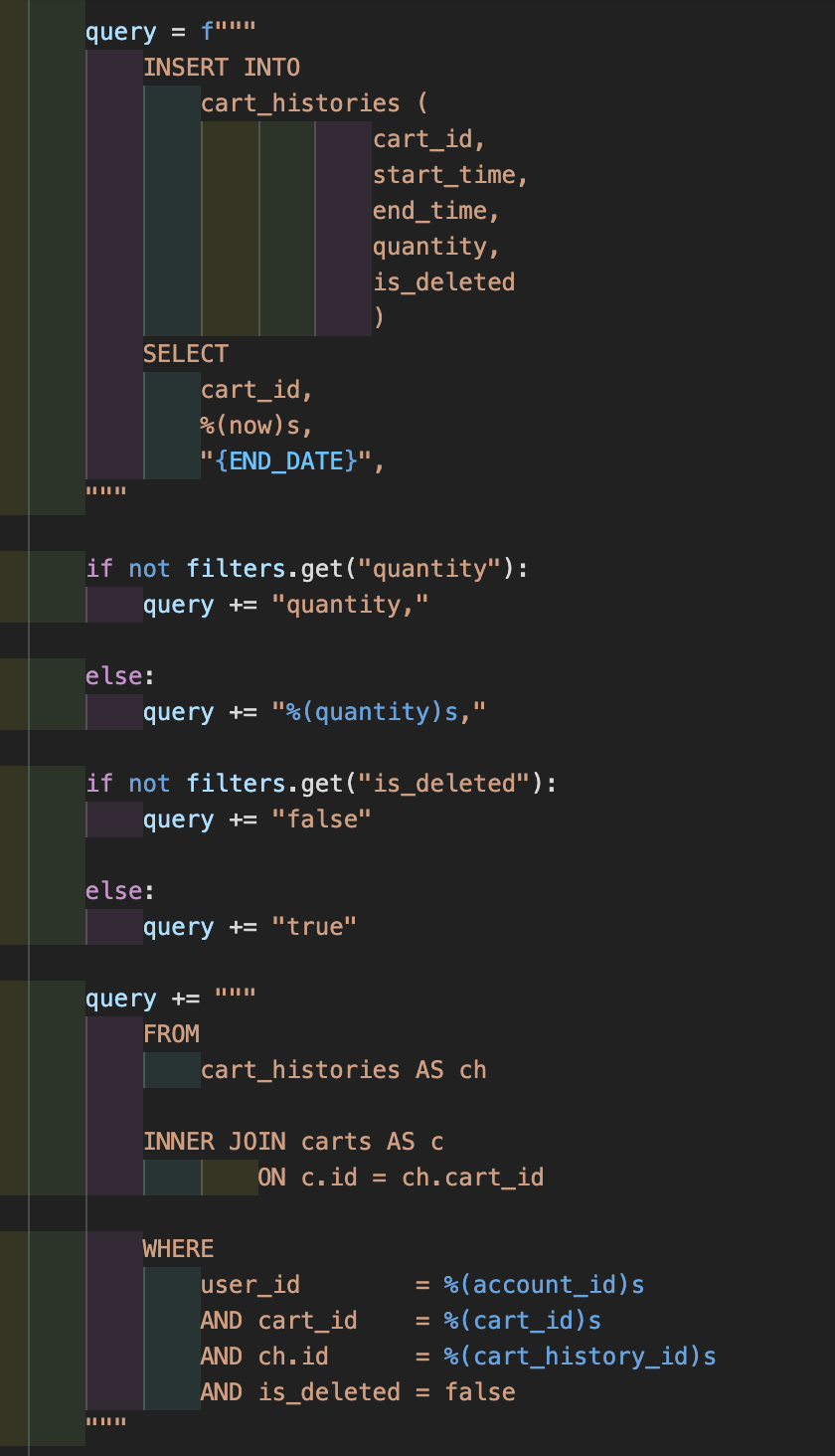
이 코드는 시간을 업데이트 한 정보를 복사한 후 수정하기 위한 코드이다. 재사용성을 위해서 조건문을 사용했다. 어떻게 이력을 관리할까를 고민하다가 이렇게 두개의 dao를 통해서 이력관리를 하였다. 이 한개의 기능을 구현하는데 오랜 시간이 걸렸다. 처음 사용해본 레이어드 아키텍쳐였고 프로젝트에 raw query를 처음 사용해보았기 때문에 익숙하지 않았다.
3주차
3주차때는 2주차때와 다르게 속도가 많이 빨라졌다. 처음 접해본 Flask라서 이해하는데 시간이 좀 걸렸던것 같다. 프레임워크는 어려운것은 없다고 생각한다. 다만 익숙하지 않을뿐이다. 내가 구현한 기능들의 대부분은 3주차에 다 만든것 같다. 그리고 본격적으로 팀장님과 기능을 붙여보기 시작했다. 3주차에 제일 기억에 남는것은 Postman의 거짓말이였다! Postman에서 잘 작동되던 코드가 프론트와 통신할때는 제대로 작동되지 않았다.
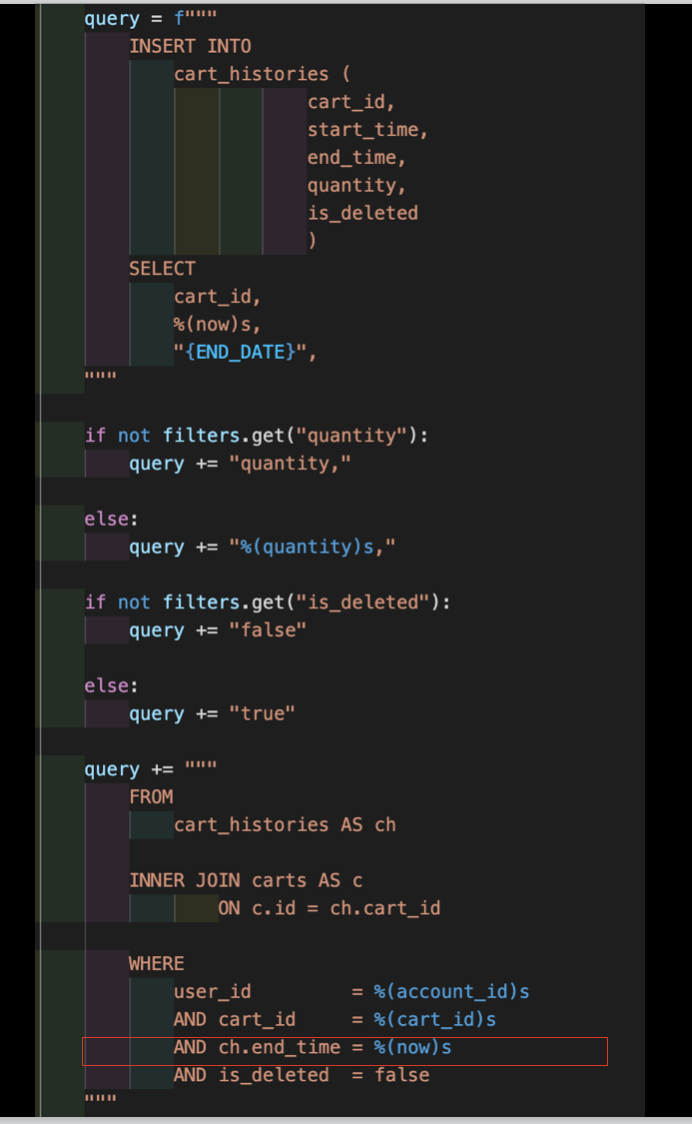
이 코드는 2주차때 수정하기 전 처음 만든 코드이다. where절에 ch.end_time = %(now)s 로 설정했을때 Postman에서는 문제가 없이 잘 돌아갔지만 프론트와 통신하는 과정에서 여러번의 요청이 들어왔을때 같은 시간으로 입력되서 데이터가 생성되는것을 알았다. 이론상으로는 같은 시간이 찍힐수가 없다고 생각했지만 문제가 발생했다.

문제를 해결하기 위해서 ch.id = %(cart_history_id)s를 넣는 방법을 택했다. primary Key를 이용하기 때문에 훨씬 안정적인 방법이였다. 이렇게 수정한 후에는 원하는대로 정상적으로 작동했다. 지금까지 Postman에서 잘 작동된 기능들은 프론트와 통신할때 문제를 발생시키지 않았다. 하지만 이번 경험을 통해서 100% 신뢰할 수 없다는 것을 깨달았다.
4주차
4주차에는 내가 구현한 모든 기능들을 프론트와 통신하고 주석을 다는데 시간을 썼다. 내가 그동안 했던 프로젝트에서는 주석을 사용하지 않았지만 이번 프로젝트에서는 각 코드가 어떤 의미를 갖는지, 어떤 데이터 값을 받고, 어떤 데이터를 결과값으로 리턴하는지 설명했다. 주석을 사용하면 코드는 깔끔해보이지는 않지만 어떤 의미로 기능을 구현했는지, 호출한 함수는 어떤 함수인지를 시간이 지난 후에도 좀더 쉽게 이해할수 있었다. 마지막날 내가 인턴쉽을 통해 배우고 구현한 기능들을 ppt로 만들어서 발표했다. ppt를 만드는데 시간을 좀더 투자했다면 더 멋진 발표가 되었을텐데 시간이 부족했다. 그 부분에서 많은 아쉬움이 남는다. 발표를 하면서 기억에 남는 질문은 왜 이력을 관리할때 END_DATE = '9999-12-31 23:59:59' 로 설정했는지 물어보셨다. 일반적으로 '9999-12-31 23:59:59'가 아닌 Null로 처리를 한다고 말씀해주셨다.
느낀점
내가 했던 마켓컬리, 여기어때 프로젝트는 2주짜리 짧은 프로젝트였지만 이번 프로젝트는 가장 길었던 1달짜리 프로젝트였다. 이전 프로젝트 경험으로 이번 프로젝트에서는 완성도 높은 결과물을 기대했다. 하지만 raw query, flask, 선분이력으로 인해서 새롭게 공부해야되는 내용들이 너무 많았다. 데이터모델링 과 flask 초기세팅에 많은 시간이 들어가면서 실제로 기능을 구현하고 프론트와 통신하는 시간이 부족했다. 결국에는 프레젠테이션을 준비하는 시간도 부족했다. 어떤 새로운 문제가 발생했을때 고민하는데 시간을 너무 많이 투자하면 그만큼 완성도가 떨어질 수 있겠다라는 생각을 했다. 우리가 해야하는 프로젝트는 시간이 정해져있었다. 시간을 효율적으로 분배하고 너무 많은 고민보다는 빠른 판단력이 필요했던 것 같다. 기업협업을 통해서 많이 성장한 것 같다. 앞으로는 효율적인 sql 작성을 위해서 책을 읽으면서 공부할 것이다.
