자료구조란?
데이터에 효율적으로 접근 하기 위한 자료의 구조, 관리, 저장 규격
데이터의 저장 구간을 효율적으로 설계 하기 위해서
다양한 자료구조를 알고 이해 할수 있으면 데이터를 보다 효율적으로 설계 하여
더 좋은 프로그램을 만들수 있다
시간 복잡도?
특정 알고리즘이 실행 되는데에 필요한 연산 시간의 총량
빅 오 표기법으로 표현됨(최악의 경우로 측정), n은 입력의 크기
공간 복잡도
알고리즘, 프로그램을 수행하는데 필요한 메모리 공간의 총량
<대표적인 자료구조>
-배열(array)
동일한 요소들이 나열된 자료형
인텍스를 통해 특정 위치의 값을 지정할 수 잇음
연속된 메모리 공간에 할당
++ 중간의 요소 하나를 지우는것이 어려움
++ 배열이 할당되는 시점에 전체 용량을 확보해야됨
-연결 리스트(linked list)
데이터 요소들을 노드 라는 단위로 연결하여, 저장하는 방식
노드는 데이터와 다음 노드를 가리키는 링크로 구성
추가와 삭제가 용이하며, 길이를 유동적으로 조절할 수 있음
++ 중간에 있는 어떤 값을 한번에 즉시 찾아낼 수가 없다고 함(링크를 하나씩 타고 넘어와야함)
-스택(stack)
순서를 가지는 자료형
LIFO(후입선출), 최근 들어온 데이터 순서대로 조회
push(현재 스택에 쌓아서 저장하는 과정) & pop(스택에 저장된 가장 마지막것을 꺼낸 행위)
실행취소, 인터넷 방문기록등
ex)웹페이지에서 뒤로가기를 하면 링크를 누르기 직전에 마지막 페이지로 이동하는 저장 메커니즘-큐(Queue) //줄서기
순서를 가지는 자료형
FIFO(선입선출),입력된 순서대로 조회
enqueue(큐에 새로운 요소를 집어 넣은 행위-> 데이터가 큐에 하나씩 적재됨)&dequeue(저장된 데이터 중에 가장 먼저 저장된 데이터를 꺼냄)
줄서기,예약 작업등-해시테이블(hash table) : 검색이 중요한 저장 할때 사용되는 자료 구조
key,value(키와 값)로 구성되는 자료구조
key는 별도의 연상(해싱)을 거쳐, 특정값으로 변환됨
이에 대한 값 저장소가 1:1로 매칭 -O(1)
키 충돌 문제가 발생할 수 있음.
시간 복잡도는 오더 숫자 1(데이터 양과 무관)
++ 핵심은 해시 알고리즘 // 해시: 주어진 키를 특정한 연산을 거쳐서 1대 1로 매칭되는 복잡한 값으로 만드는 연산
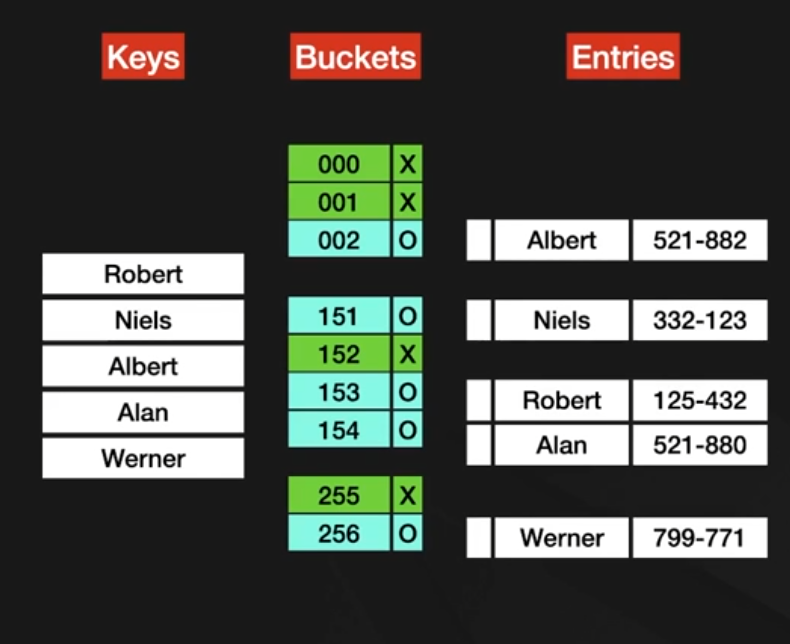
키: 데이터를 저장하고 찾기 위한 키
버킷: 각키의 해시결과와 실제 데이터가 연결되는 메모리 주소를 가지고 있는버킷
엔트리: 실제 데이터가 저장되는 엔트리
왜 이렇게 저장?
배열에서 있었던 중간에 요소를 추가하거나 제거하는 것에 더 유연하게
기존 버킷 사이즈와 새로 데이터가 얼마나 들어왔는지 무관하게 운영이 되기 때문에 -트리(Tree)
계층 및 분기 구조를 가지는 자료구조
루트(root):맨 위의 노드를 칭함,parent/children(부모/자식): 계층 구조를 가지는 두 노드 간의 관계
디텍토리/ 파일 구조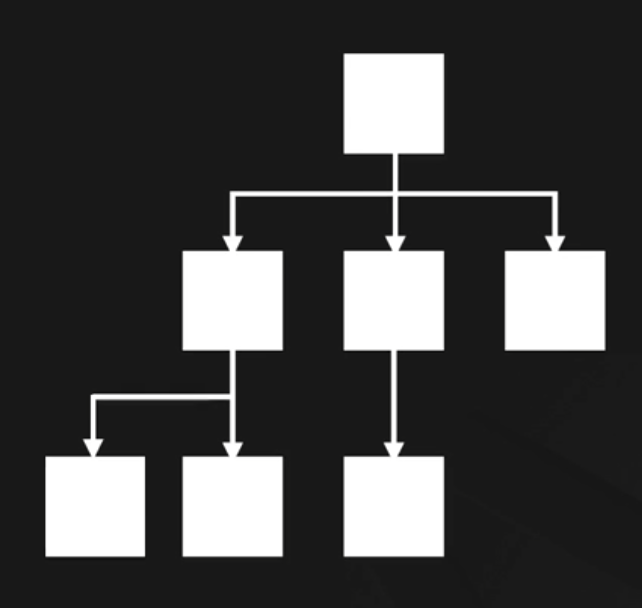
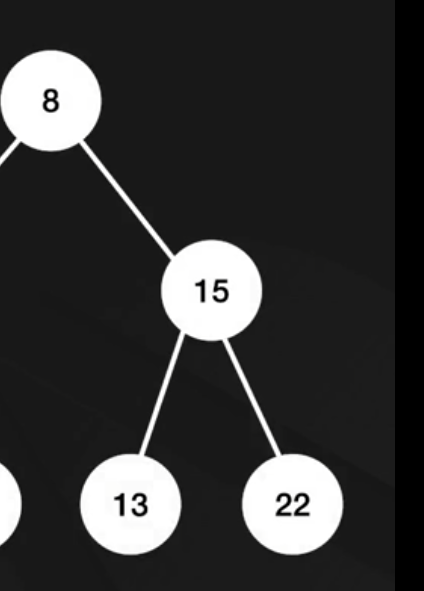
-이진 트리(binary Tree) : 원래 트리구조를 검색 목적으로 변경한 형태
자식 노드가 최대 2개로 구성된 트리
이진 탐색 트리: 왼쪽자식은 부모보다 작고, 오른쪽 자식은 부모보다 큼
O(logn) : 전체 데이터를 순회할 필요가 없음
균형잡힌 이진 트리
++ 잘 짜여진 이진 탐색 트리를 통해서 우리는 검색에 대한 성능을 보다 크게 가져갈수 있음
chan