pandas method로 진행하는 EDA
- 데이터를 다루고 파악하기 용이한 문법

데이터의 형태는 매우 다양(csv, json, API, ect..)하지만 대부분의 과정에서 데이터를 Table구조(표 형태)로 변형하여 확인한다.
행(가로)과 열(세로)의 간단한 구성이지만, 묶거나 분리하거나 정렬하는 등 확인을 거쳐가며 체계적인 작업이 용이하기 때문이다.
Table 형태의 데이터를 다룰때 필수적인 pandas의 내장method를 이용하여 데이터의 전신을 파악할 수 있다.
Colab환경에서 Pandas library를 통해 Table구조를 기반으로 한 EDA를 실습해보자.
실습데이터 : tips_na
-
seaborn 라이브러리를 통해 불러 올 수 있는 tips 데이터에 인위적으로 결측치, 이상치를 첨가한 데이터셋
-
total_bill: 총 합계 요금표
tip: 팁
sex: 성별
smoker: 흡연자 여부
day: 요일
time: 식사 시간
size: 식사 인원
1) 데이터 구성 미리보기 :
head(), tail()
1.1) head()
1.2) tail()
- head()와 tail()은 각각 데이터의 상단 5개, 하단 5개를 불러와 어떤 구성으로 되어있는지 미리보기 위해 사용된다.
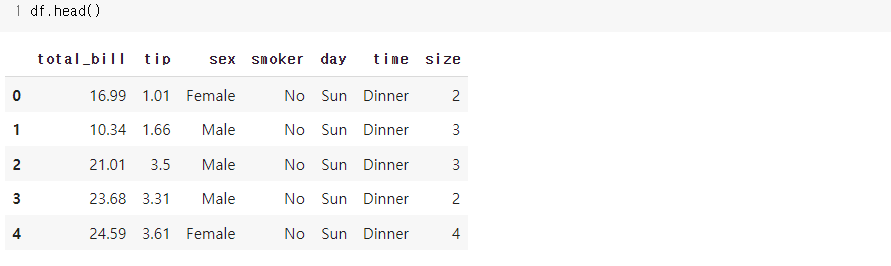

데이터를 핸들링하는 과정에서 원하는대로 편집 되었는지 간략히 확인
2) 데이터 요약정보 확인하기 :
shape, dtypes, info()
2.1) shape
- shape을 통해 데이터의 전체 형태(행, 열)을 알 수 있다.
(244 행, 7개 열) 형태2.2) dtypes
- 데이터 변수(열)들의 타입(자료형태)을 보여준다.
(total_bill = 소숫점형태, size = 정수형태, sex = 객체형태)- head()로 확인했을때 tip 은 숫자였는데, 객체형태로 확인된다면, 하나라도 객체형 데이터가 삽입되어있다는 것을 간접적으로 알 수 있다.
2.3) info()
- 데이터의 기본 정보(데이터 형태, 결측치여부, 변수타입, 메모리)를 보여준다.


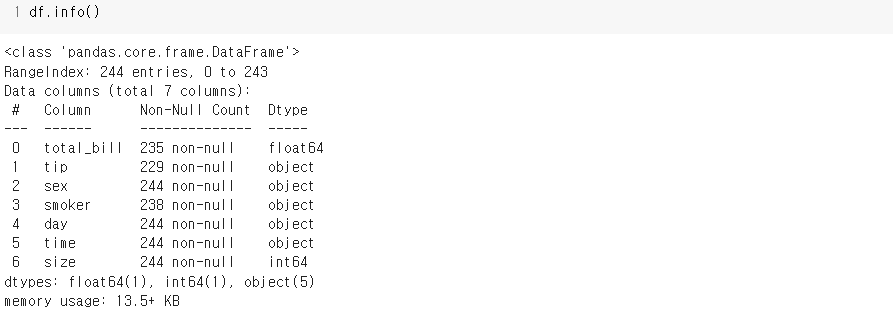
데이터의 형태, 구성에 대해 확인하고, 이상한 점을 대략적으로 파악
3) 통계정보 확인하기 :
count(), value_counts(), mean(), median(), max(), min(), std(), describe(), corr()
3.1) count()
- 각 변수별 몇개의 값이 채워져 있는지 보여준다.
(244개의 행이 있으나, 이보다 작은 값을 가진 변수의 경우 값이 없는 결측치가 존재한다는 것을 간접적으로 알 수 있다.)3.2) value_counts()
- 특정 열의 고유값 갯수를 확인한다.
(전체 데이터를 예시로 들기엔, 광범위하여 smoker 변수로 한정. No 145개, Yes 93개 값을 지닌다.)


3.3) max(), min(), mean(), median(), var(), std()
- max()로 데이터 프레임 내 각 변수들의 최대값을 알 수 있다.
(값이 object 자료형일땐 첫번째 글자의 아스키코드를 기준으로 최대,최소값이 결정)
- 수치형 변수에 대해서만 보기 위해선 "numeric_only = True" 조건을 추가


- min()으로 데이터 프레임 내 각 변수들의 최소값을 알 수 있다.

- mean()으로 데이터 프레임 내 각 변수들의 평균값을 알 수 있다.

- median()으로 데이터 프레임 내 각 변수들의 중앙값을 알 수 있다.

- var()로 데이터 프레임 내 각 변수들의 분산을 알 수 있다.

- std()로 데이터 프레임 내 각 변수들의 표준편차를 알 수 있다.

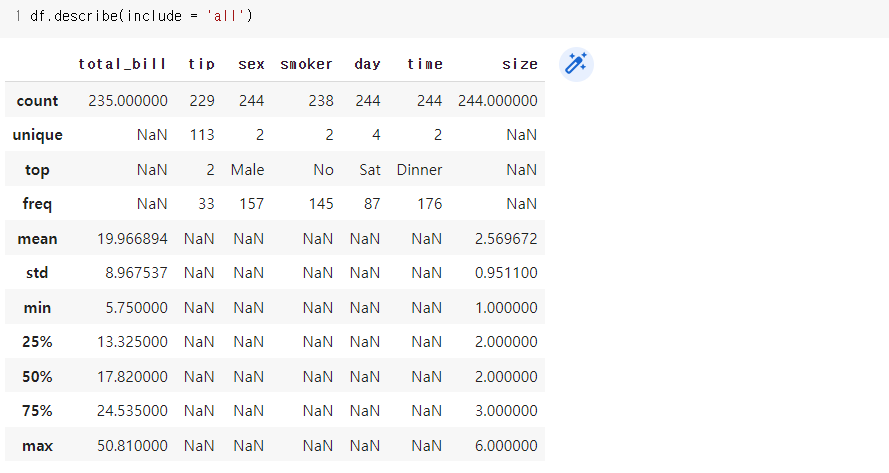
3.4) describe()
- 값의 수, 고유값의 수, 최빈값, 빈도수, 평균, 표준편차, 최소값, 사분위수, 최대값 순으로 출력되며, 자료형에 적합하지 않으면 'NaN'으로 생략된다.
3.5) corr()
- 수치형 변수간의 상관계수(비례관계의 정도)를 확인할 수 있다.
상관계수 의미 0.7~1.0매우 높은 음/양의 상관관계0.3~0.7높은 음/양의 상관관계0.1~0.3약한 음/양의 상관관계0.0~0.1상관관계 없음- total_bill과 size는 높은 양의 상관관계이다.
(식사인원이 증가할수록 총 지출금액이 증가한다.)

값들의 분포, 관계에 대해 대략적으로 확인
이 외에도 다양한 내장메소드들이 있으며, 조합에 따라 부분적으로 확인 하는 것 또한 가능하다.
표 형태의 데이터를 가장 간편히 다룰 수 있는 도구로 꼭 익혀놓아야 할 가치가 있으니, 아래 Reference를 참고하여 학습을 진행하길 바란다.
Today_Summary : 재료를 손질하기 위해 pandas로 요목조목 살펴보자.
References

암묵지를 형식지로 풀어내는 데이터사이언티스트