1. 데이터 전처리(Data Preprocessing)
- 데이터를 사용하고자 하는 목적에 맞게 변형하는 작업

이미지 출처 : https://www.analyticsvidhya.com/blog/2021/08/data-preprocessing-in-data-mining-a-hands-on-guide/
빅데이터는 광범위한 정보를 담고있기에 분석시 모든 특성을 반영하기 어렵고, 용량적으로도 부하가 커 효율적으로 활용하기 위해 간결성을 갖춰놓아야 한다.
따라서, 원데이터를 그대로 사용하기보다 원하는 형태로 가공하는 과정을 거치는데,이를 데이터 전처리라고 한다.
이는 일종의 필터링작업으로 볼 수 있는데, 기껏 시간과 돈을 들여 수집한 데이터를 허비하지 않고 솎아내기 위해 데이터와 산업에 대한 이해도가 요구된다.
2. 도메인 지식(Domain Knowledge)

이미지 출처 : https://thenounproject.com/icon/expert-2263180/
도메인 지식이란 전문화된 학문/분야의 지식을 뜻하며, 이해도로 표현할 수 있다.
전처리 과정에서 도메인 지식 없이 기계적으로 어떤 데이터를 줄이거나 재구성한다면 데이터에 녹아 있는 정보가 유실된다.
따라서, 어떤 데이터가 군더더기인지 알아봐야 하고, 데이터에 포함된 의미와 이를 어떻게 재구성해야 하는지 계획을 세우는데 있어 분석가의 배경지식이 영향을 미친다.
ex) 같은 단어이지만 배경지식에 따라 해석이 다름
이미지 출처 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=corncake123&logNo=220432526573
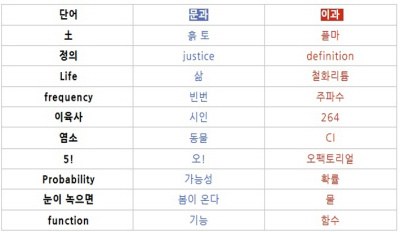
데이터를 효율적이고 정확하게 활용하기 위해 전문화된 이해도를 갖추도록 하자.
3. 예고(데이터 전처리 시리즈)
데이터 전처리의 유사어들은 많이 존재하지만, 개인적인 각색을 통해
데이터 가공(Data Manipulation)과 데이터 정제(Data Cleanging)
로 나누어 알아보겠다.
- 개인적 각색 :
- 1) 데이터 가공 : 부족한 정보를 외부에서 가져와 합치거나(Integration), 데이터의 형태를 변환(Transformation, Reduction)
- 2) 데이터 정제 : 원 데이터 내에서 잡음(Noisy), 결측치(Missing Values), 이상치(Outlier)를 처리
Today_Summary : 야생의 데이터를 좋은 원료로 가공하기 위해 전문지식을 갖추자

암묵지를 형식지로 풀어내는 데이터사이언티스트