피처 스케일링(feature scaling)은 서로 다른 변수의 값에 대한 범위를 일정한 수준으로 맞추는 작업
- 표준화(Standardization)
- 정규화(Normalization)
- Min-Max Normalization을 정규화, Z-Score Normalization을 표준화라고도 부른다.
-
표준화: 데이터의 피처들 각가의 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환해주는 것입니다.
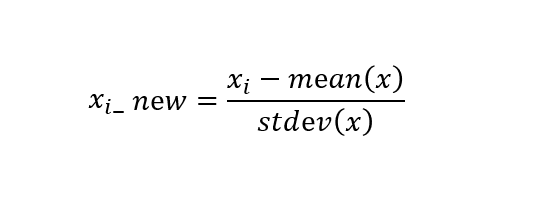
-
정규화: 서로 다른 피처들의 크기를 통일하기 위해 크기를 변화해주는 것입니다. 예를들어 A피처는 값이 0~100KM 거리를 나타내고 B피처는 0~100,000,000,00으로 금액을 나타낸다고 했을때 이 변수들을 동일한 크기의 단위로 값을 최소 0~ 최대 1의 값으로 변환한다고 생각하면 됩니다.
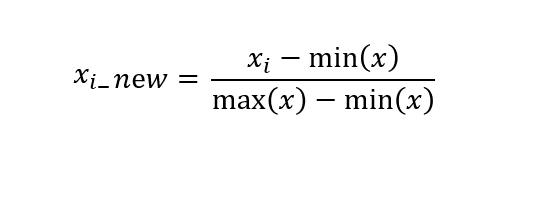
StandardScaler
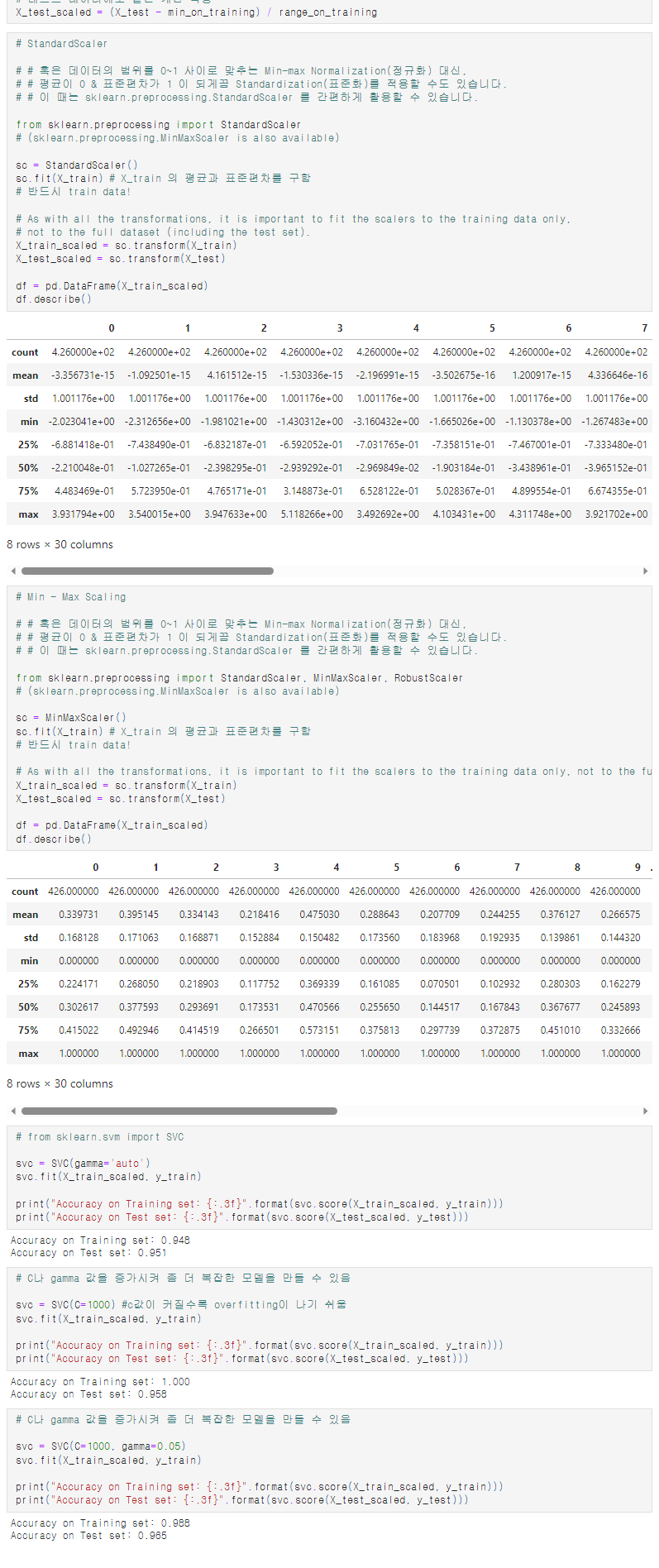
- StandardScaler은 표준화를 쉽게 지원해 주는 함수입니다. 다시 설명하자면 피처들을 평균이 0이고 분산이 1인 값으로 변환을 시켜줍니다.
- 서포트 벡터 머신(Support Vector Machine), 선형 회귀(Linear Regression), 로지스틱 회귀(Logistic Regression)과 같은 가우시안 분포를 가지고 있다고 가정을 하고 구현된 ML 알고리즘들은 표준화를 적용하는 것이 예측 성능 향상에 중요한 요소로 작용될 수 있습니다.
from sklearn.datasets import load_iris
import pandas as pd
iris=load_iris()
iris_data=iris.data
iris_df=pd.DataFrame(data=iris_data, columns=iris.feature_names)
# StandardScaler을 사용해서 표준화
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(iris_df)
iris_scaled=scaler.transform(iris_df)
# StandardScaler() 객체를 생선한 후 fit(), transform()을 호출스케일링 변환 시 주의사항
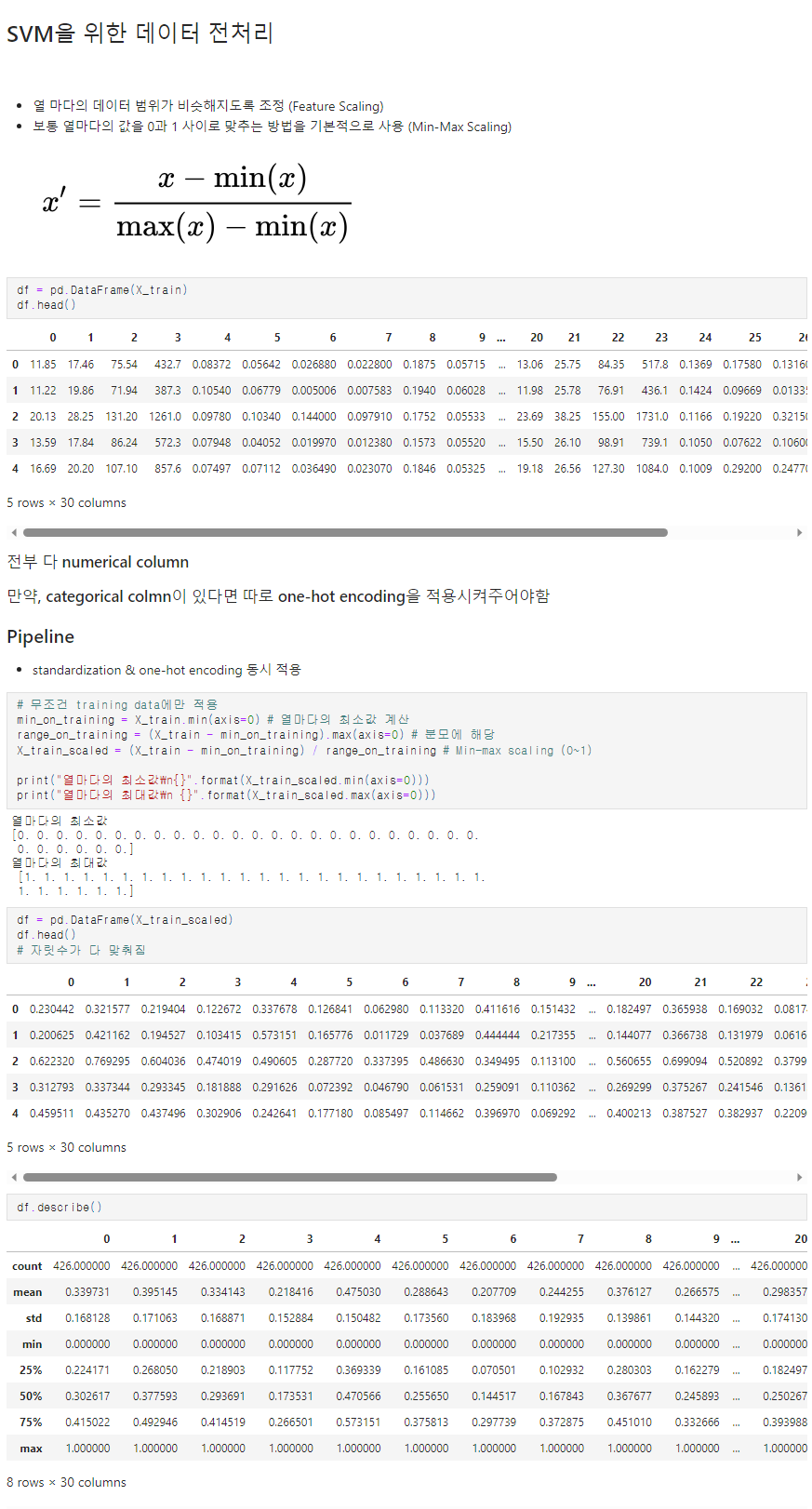
- 데이터의 스케일링을 적용할때 fit(), transform(), fit_transform() 함수를 사용한다.
- 학습 데이터로 fit(), transform()을 적용하고 테스트 데이터에서 다시 fit()을 수행하지 않고 학습데이터로 fit() 적용한 결과를 이용해서 transform()을 적용해야 한다는 것입니다.
→ 그 이유는 테스트 데이터로 다시 새로운 스케일링 기준을 만들어 버리면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 달라지기 때문입니다.
- 스케일러 객체 만들어주기
- fit : 데이터 스케일링의 기준 만들기
- transform : 기준이 만들어진 스케일러로 스케일링하기
from sklearn.preprocessing import MinMaxScaler
import numpy as np
train_array=np.arange(0,11).reshape(-1,1)
test_array=np.arange(0,6).reshape(-1,1)
# 학습 데이터를 0~11, 테스트 데이터를 0~5까지의 값을 가지게 ndarray를 만들어 줍니다.
sclaer=MinMaxScaler()
scaler.fit(train_array)
train_scaled=scaler.transform(train_array)
print('원본 train_array:', np.round(train_array.reshape(-1),2))
print('scale이 적용된 train_array:', np.round(train_scaled.reshape(-1),2))
#Out
"""
원본 train_array: [ 0 1 2 3 4 5 6 7 8 9 10]
scale이 적용된 train_array: [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
# MinMaxScaler 객체의 fit()과 transform()적용하여
# 1->0.1, 2->0.2로 변환게 된 것을 확인하였습니다
"""테스트 데이터의 fit()을 다시 적용
scaler.fit(test_array)
test_scaled=scaler.transform(test_array)
print('원본 test_array:', np.round(test_array.reshape(-1),2))
print('scale이 적용된 test_array:', np.round(test_scaled.reshape(-1),2))
# output
"""
원본 test_array: [0 1 2 3 4 5]
scale이 적용된 test_array: [0. 0.2 0.4 0.6 0.8 1. ]
"""ML 모델은 학습 데이터를 기반으로 학습이 되기 때문에 반드시 ㅔ스트 데이터는 학습 데이터의 스케일링 기준을 따라야 합니다. 따라서 테스트 데이터에는 다시 fit()을 적용해서는 안됩니다.
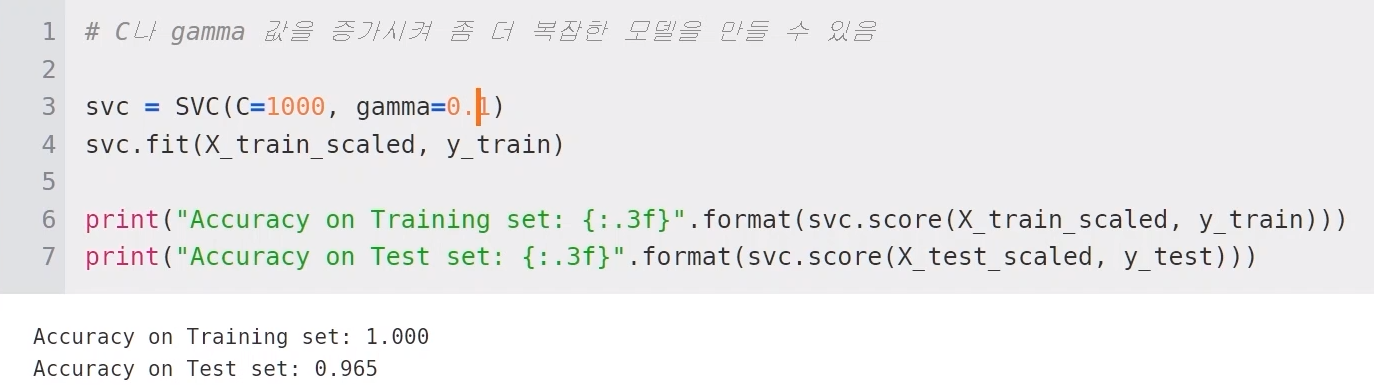
=> C나 gamma 값을 증가시켜서 좀 더 복잡한 model을 만들 수 있지만, 매번 c, gamma값을 구하기는 어려움 => "hyper parameter"
GridSearch
HPO
== Hyper-parameter Optimaization
== Hyper-parameter Tuning
== Model Tuning
3가지의 HPO 방법
1. grid search : 후보군을 만들어 놓고, 후보군들 사이를 cross시켜서 최적의 조합을 찾아내는 기법
2. Randomized Search HPO : C 값의 후보를 분포로 해당 값이 나올 수 있는 구간을 입력해줌
3, Bayesian - Search HPO : by 베이즈 통계학
빈도주의 통계학 VS 베이즈 통계학
- 빈도주의 통계학 : 실험 결과를 해석 => 확률 계산
- 베이즈 통계학 : 사전 확률 => 가설로 어떤 확률값을 생각 => 실험 진행하면서 사전 확률을 수정하면서 사후확률로! (실험을 통해 믿음을 수정)

Kyunghee univ. IE 21