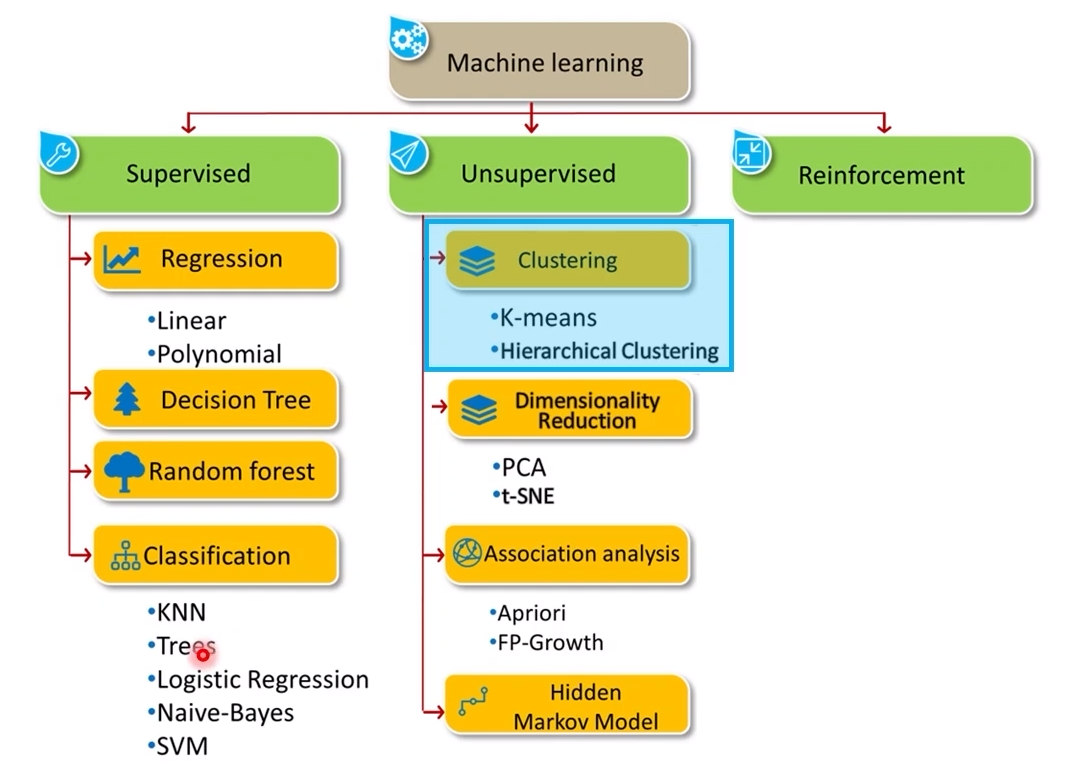
비지도 학습 -> y data가 필요 X
- Clustering
- 차원 축소
- k 개의 중심값 알고리즘
- 임의의 값 설정 => 평균 내기 => 평균으로 중심축 바꾸기 => 중심이 일정해질 때까지 반복
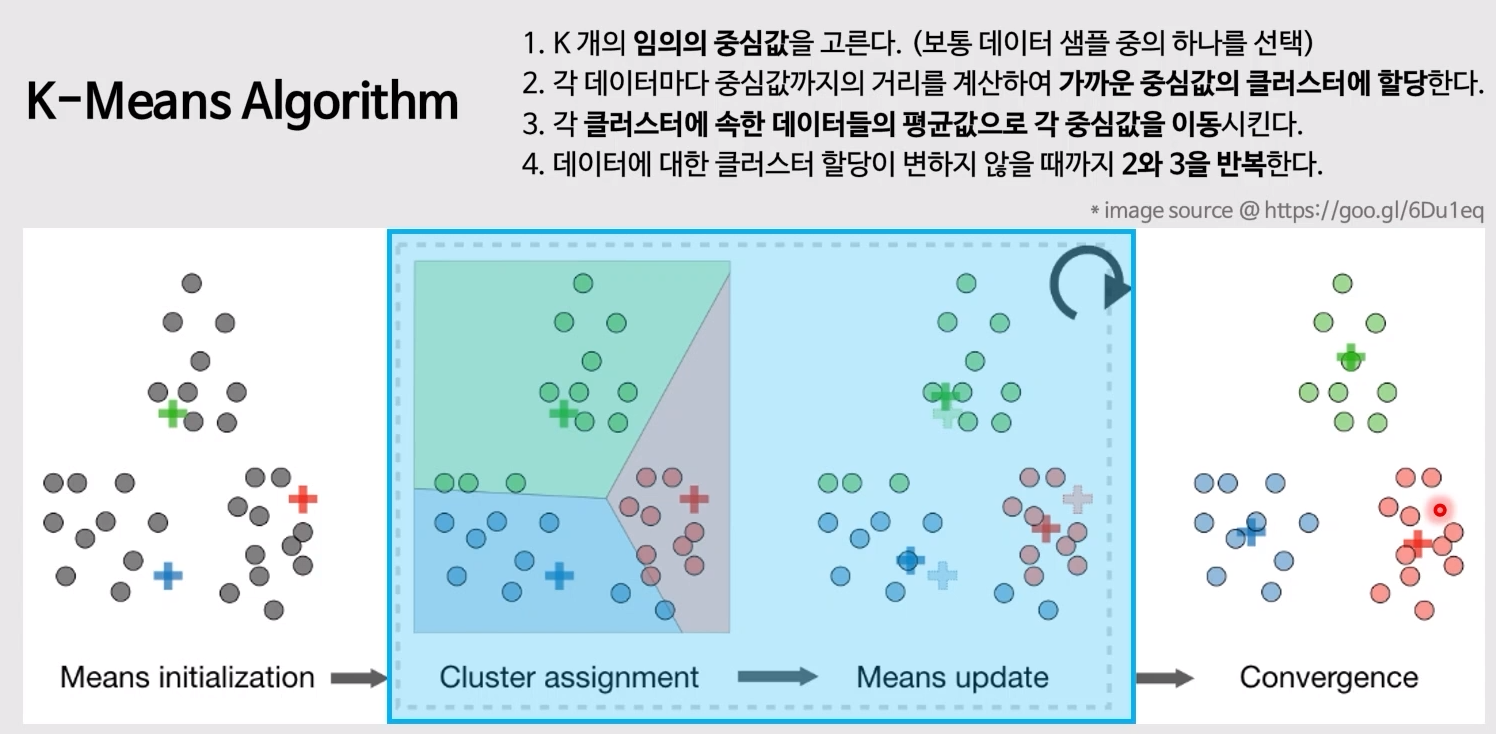
- 마지막에 결정된 군집 분포에 의해 새로운 data가 들어오면 분류 가능!
- cluster의 수, x data의 열이 많아질수록 연산량, 계산 시간이 증가 => x data를 직접 바라보고, 중요한 열을 선택 가능
- k - means clustering이 너무 오래 걸릴 때 사용할 수 있는 대안

- 비지도 학습은 정답을 맞추기 위한 model이 아니므로, train / test split X
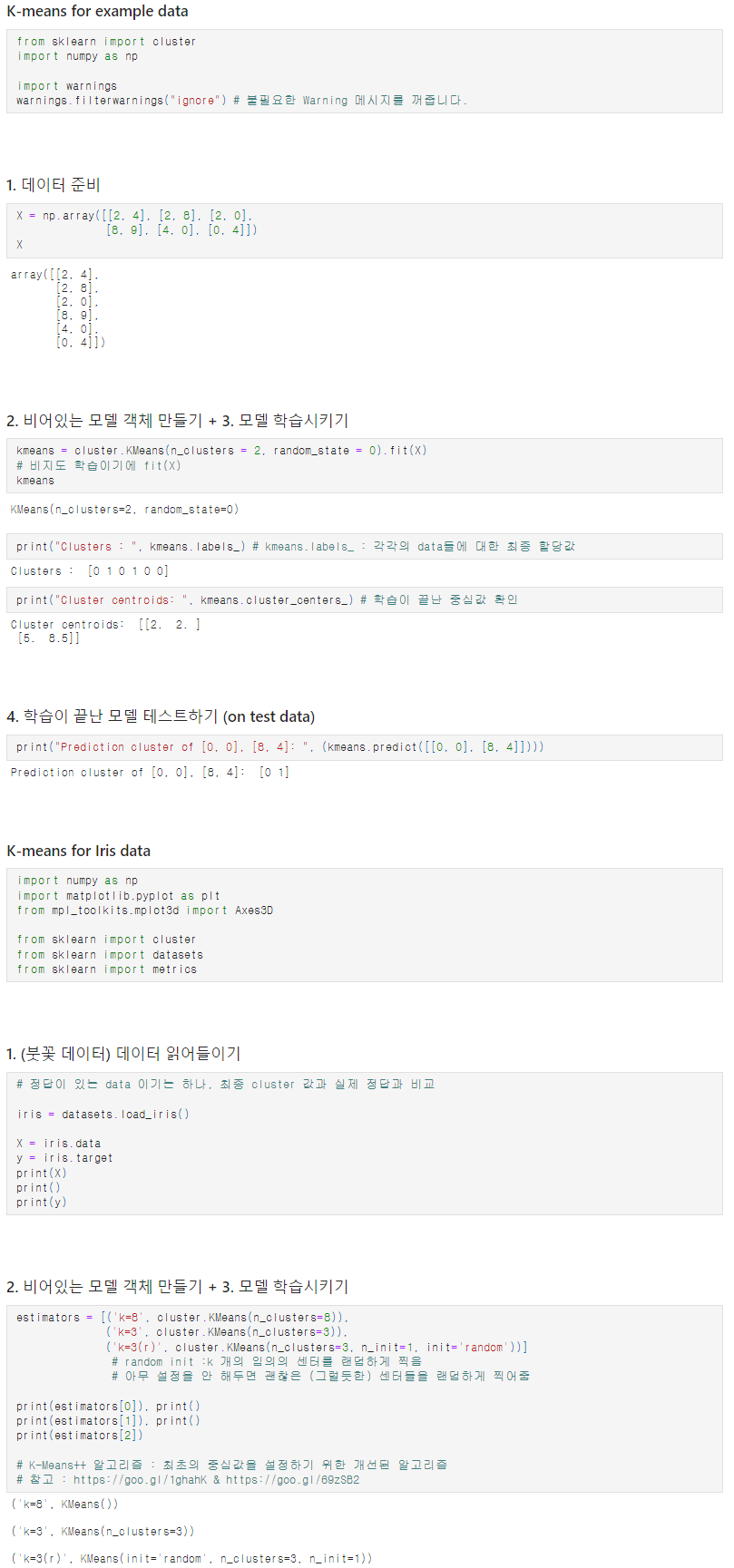

Ground Truth : 실제 data

Kyunghee univ. IE 21