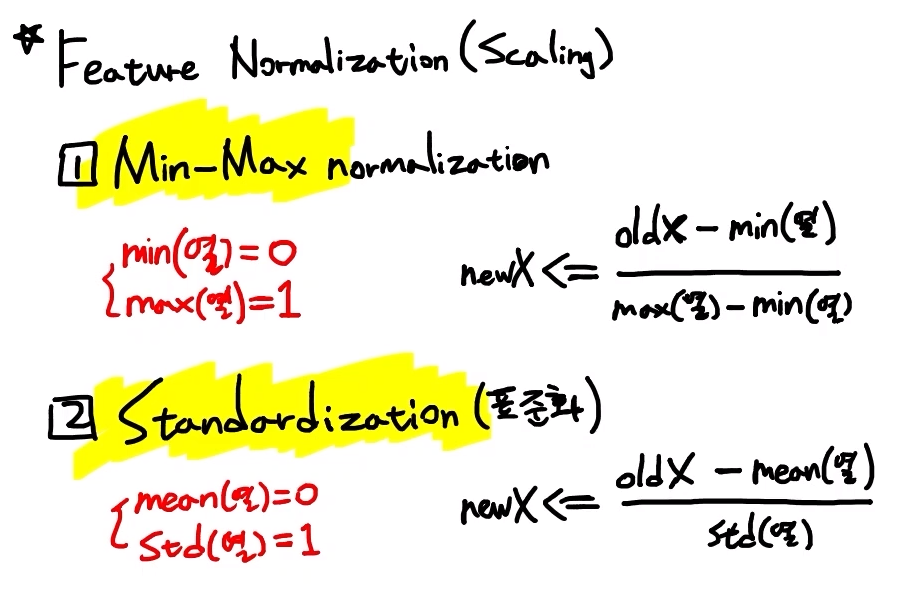
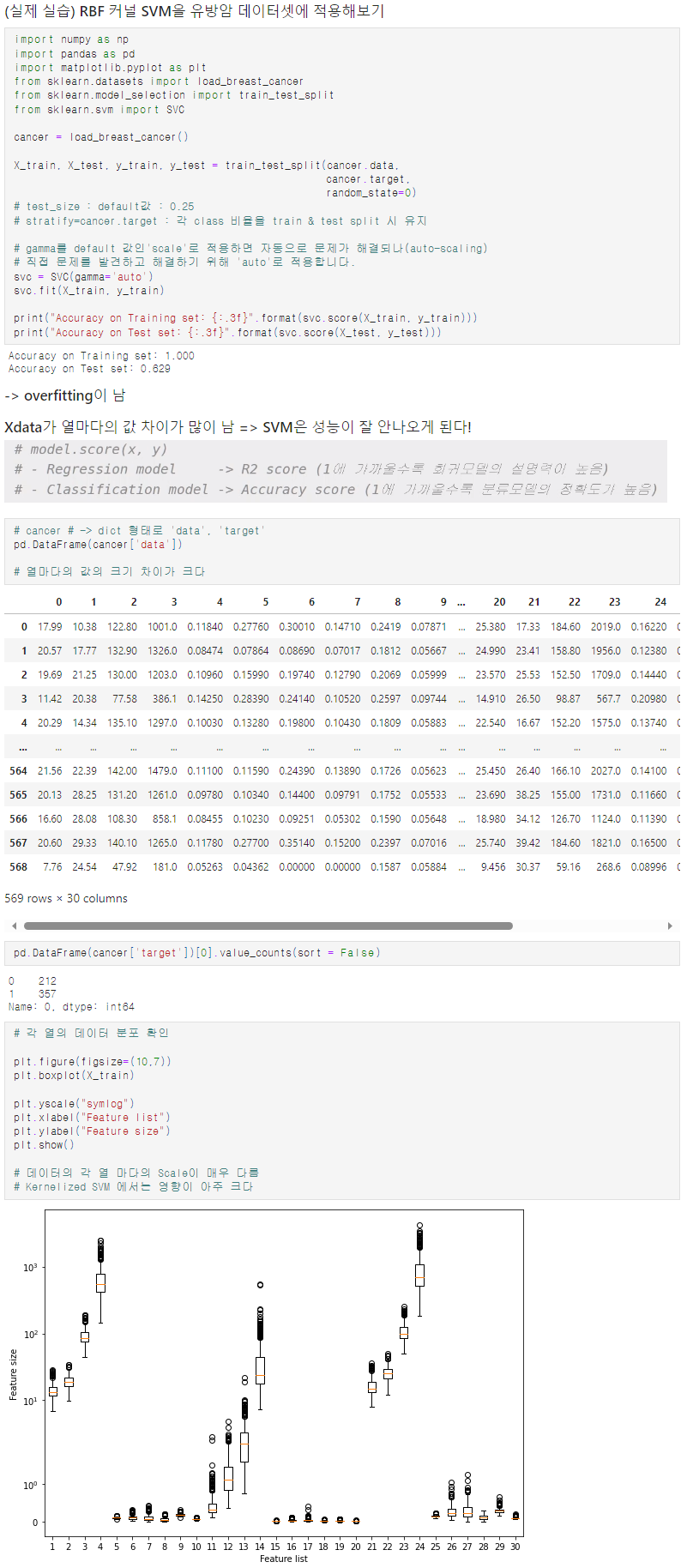
X data 열마다의 값 차이가 클 때!
- x data의 크기가 균일해야 한다 =? "feature Scaling"이 필요
- Tree 기반의 model은 필수적이지 않지만, SVM을 위한 data 전처리
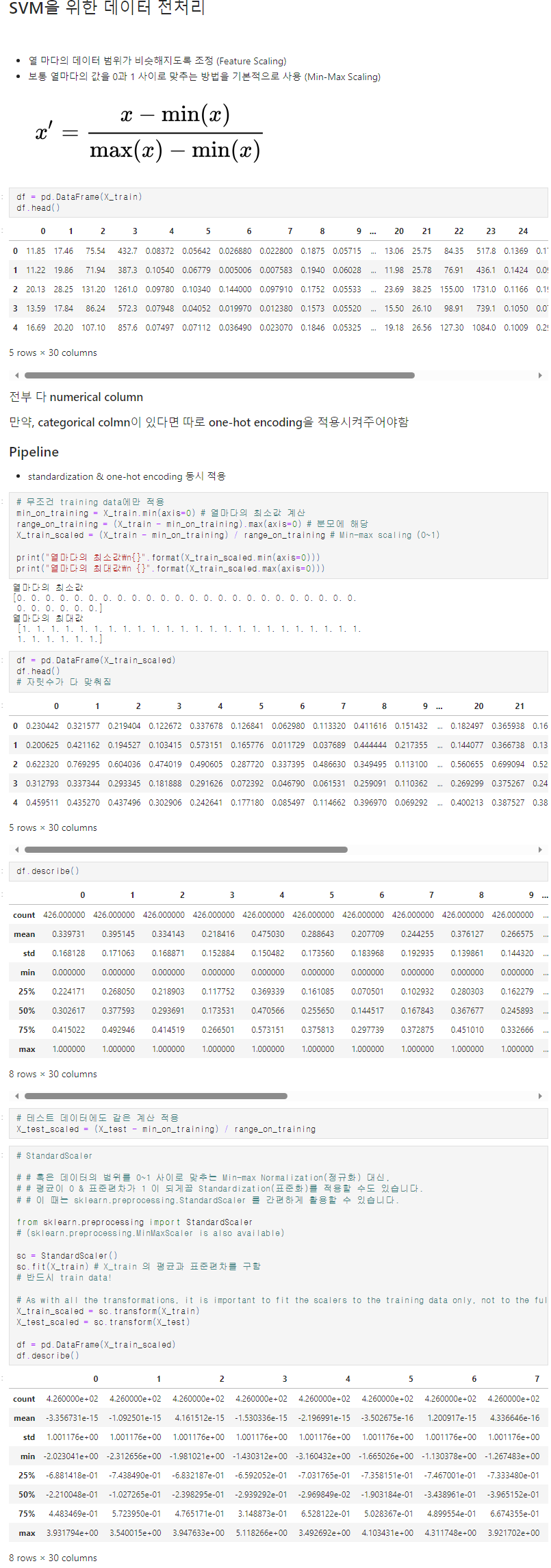
Feature Normalization 시, 절대로 Test Data는 건드리면 안 된다!
Train/Test split => Train Data만 적용시킨다!
- test data는 채점용으로만 사용하기에, 채점을 진행할 때에, train data를 계산할 때의 계산 식과 값을 활용해야한다! (열의 최소, 최댓값 => train data의 최소 최대값으로!)
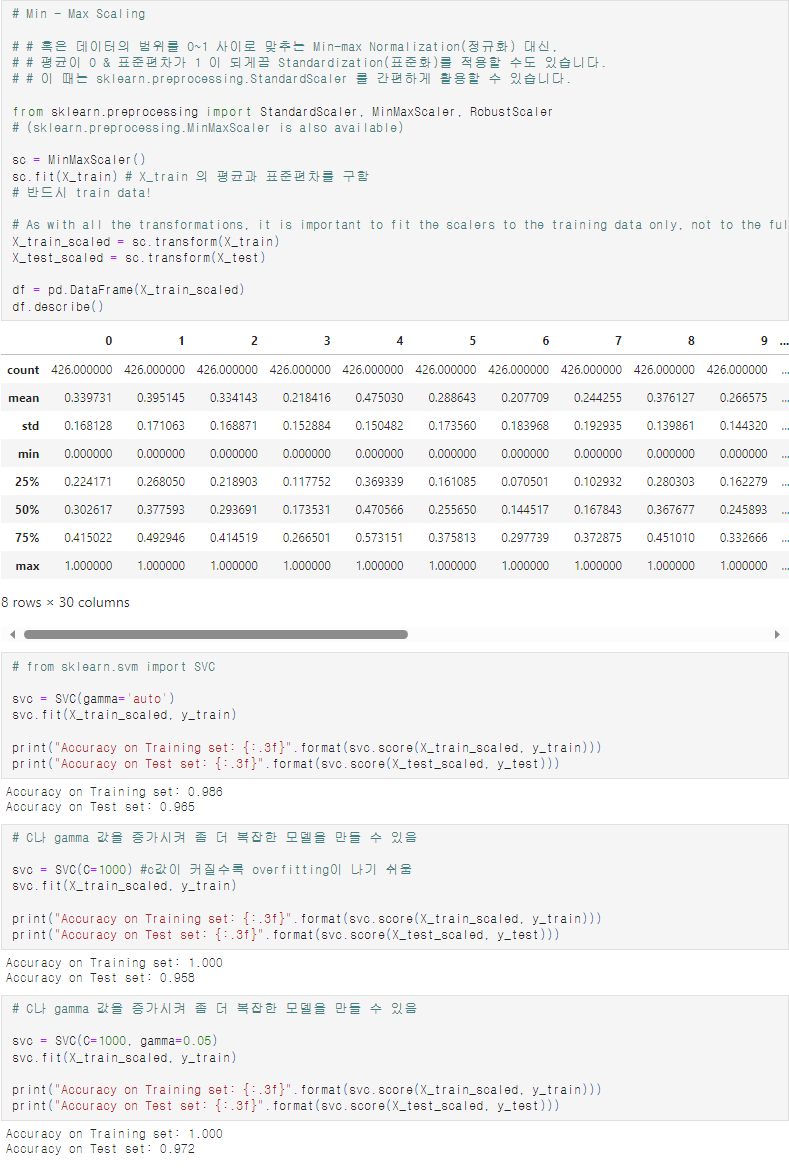
- Standardization을 적용시키는 것 : standard scaling
# step1
sc = sklearn.preprocessing.StandardScaler()
# step2
# 전처리 도구이기에, x data만 입력값으로 넣어준다.
# 단, X data 전체가 아닌 train data만을 넣어준다.
sc.fit(train_X)
# train X 에 포함된 모든 열에 대한 계산값을 저장
# step3
train_X_scaled = sc.transform(trainX)
# 이후 model.fit()에 사용
test_X_scaled = sc.transform(test_X)
# 이후 model.predict()에 사용
# 이후 model.score( ,test_Y)에 사용
- 새로운 data 1행이 추가되었을 때
=> [ [ ] ] 입력값 개수를 맞추고, 대괄호로 2번 감싼 형태로 입력값을 넣어주어야함!- feature scaling을 마치고, model.predict에 넣어주어야함!

- model을 만들고 저장할 때에는 standard scaler도 같이 저장해주어야함!
pipeline : standardization & one-hot encoding 동시 적용
일반적으로는 standardization이 성능이 더 잘 나온다

Kyunghee univ. IE 21