
Pandas 소개
Anaconda
conda install pandas
Pandas의 특징
1) 빠르고 효율적이며 다양한 표현력을 갖춘 자료구조
- 실세계 데이터 분석을 위해 만들어진 파이썬 패키지
2) 다양한 형태의 데이터에 적합
- 이종 자료형의 열을 가진 테이블 데이터 시계열 데이터
- 레이블을 가진 다양한 행렬 데이터
3) 핵심 구조
- 시리즈 : 1차원 구조를 가진 하나의 열
- 데이터프레임 : 복수의 열을 가진 2차원 데이터
4) 판다스가 잘 하는일
- 결측 데이터 처리
- 데이터 추가 삭제, 데이터 정렬과 다양한 데이터 조작
Pandas로 할 수 있는 일
1) 데이터 불러오기 및 저장하기
2) 데이터 보기 및 검사
3) 필터, 정렬 및 그룹화
4) 데이터 정제
CSV
테이블 형식의 데이터를 저장하고 이동하는 데 사용되는 구조화된 텍스트 파일 형식
쉼표로 구분한 변수
데이터 읽는 방법
import csv
f = open('d:/ddata/weather.csv') # csv 파일을 열어서 f에 저장한다.
data = csv.reader(f)
for row in data:
print(row)
f.close()
# 결과
# ['일시', '평균기온', '최대풍속', '평균풍속']
# ['2010-08-01', '28.7', '8.3', '3.4']
CSV 헤더를 제거하는 방법
import csv
f = open('d:/data/weather.csv') # csv 파일을 열어서 f에 저장한다.
data = csv.reader(f) # csv의 reader() 함수를 이용해서 읽는다.
header = next(data) # 헤더를 제거한다.
for row in data: # 반복 루프를 사용하여 데이터를 읽는다.
print(row)
f.close() # 파일을 닫는다.
CSV에서 원하는 데이터를 뽑기

import csv
f = open('d:/data/weather.csv') # CSV 파일을 열어서 f에 저장한다.
data = csv.reader(f) # reader() 함수를 이용하여 읽는다.
header = next(data) # 헤더를 제거한다.
for row in data: # 반복 루프를 사용하여 데이터를 읽는다.
print(row[3], end =',') # 평균풍속만 출력하고, 쉼표를 연결한다.
f.close() # 파일을 닫는다.
반복문을 사용하여 import한 데이터의 네번 째 열의 원소 값 중에서 최대값을 구하자.
# 위의 코드 import .. 부터 header =.. 까지가 생략되었다.
max_wind = 0.0
for row in data: # 반복 루프를 사용하여 데이터를 읽는다.
if row[3] == '' : # 평균 풍속 데이터가 없는 경우 0을 처리
wind = 0
else:
wind = float(row[3]) # 평균 풍속 데이터를 실수로 변환해 저장
if max_wind < wind : # 최대 풍속을 갱신하는지 검사
max_wind = wind: # 현재까지의 최대 풍속보다 크면 새로 기록
print('지난 10년간 울릉도의 최대 풍속은', max_wind, 'm/s')
# 결과
# 지난 10년간 울릉도의 최대 풍속은 14.9 m/s
울릉도는 몇 월에 바람이 가장 강할까?
import csv
import matplotlib.pyplot as plt
f = open('d:/data/weather.csv') # CSV 파일 열어 f에 저장
data = csv.reader(f) # reader() 함수로 읽기
header = next(data) # 헤더를 제거
monthly_wind = [ 0 for x in range(12)] # 매당 풍속을 담을 리스트, 초기화 0
days_counted = [0 for x in range(12)] # 각 달마다 측정된 일수, 초기화 0
for row in data:
month = int(row[0][5:7]) # 0번 열에서 달 정보 추출
if row[3] != '': # 풍속 데이터 존재하는지 확인
wind = float(row[3]) # 풍속을 얻어 온다.
monthly_wind[month-1] += wind # 해당 달에 풍속 데이터 추가
days_countd[month1] += 1 # 해당 달의 일수를 증가
for i in range(12):
monthly_wind[i] /= days_counted[i] # 일수로 나누어 월평균 구하기
plt.plot(monthly_wind, 'blue')
plt.show()
f.close() # 파일을 닫는다.
Pandas의 데이터 구조 : Series와 DataFrame

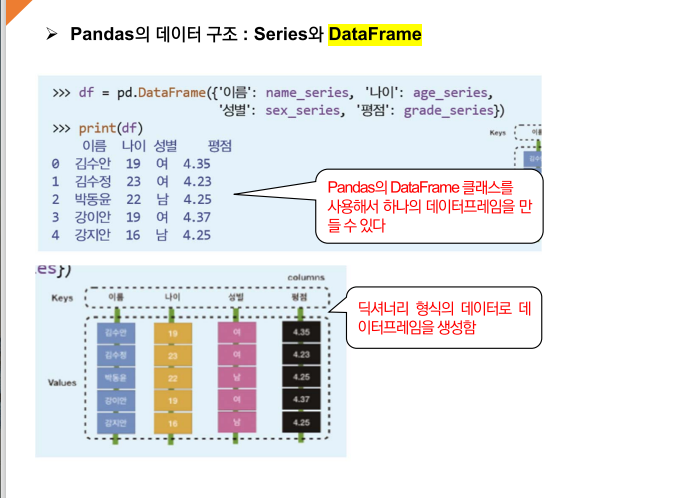
Pandas로 데이터 읽기
import pandas as pd
df = pd.read_csv('d:/data/countries.csv')
df
데이터를 설명하는 인덱스와 컬럼스 객체
import pandas as pd
df = pd.read_csv('d:/data/countries.csv',index_col = 0)
print(df)
열을 기준으로 데이터 선택하기
특정한 열만 선택하려면 아래와 같이 대괄호 안에 열의 이름을 넣으면 된다.
import pandas as pd
df_my_index = pd.read_csv('d:/data/countries.csv', index_col = 0)
df_no_index = pd.read_csv('d:/data/countries.csv')
print(df_my_index['population'])
print(df_no_index['population'])
import pandas as pd
df_my_index = pd.read_csv('d:/data/countires.csv', index_col = 0)
print(df_my_index[['area','population']])
데이터 가시화하기
import pandas as pd
import matplotlib.pyplot as plt
countires_df = pd.read_csv('d:/data/countires.csv',index_col = 0)
countires_df['population'].plot(kind='bar', color=('b','darkorange','g','r','m'))
plt.show()
Pandas에서도 슬라이싱으로 행 선택이 된다.
처음 행 : head()
마지막 행 : tail()
countires_df.head()
df.loc["row","column"] # 행과 열의 이름
df.iloc[i,j] # row, column의 인덱스 값
새로운 열 생성
import pandas as pd
import matplotlib.pyplot as plt
countires_df = pd.read_csv('d:/data/countries.csv', index_col = 0)
countires_df['density'] = countires_df['population'] / countires_df['area']
print(countires_df)
데이터를 간편하게 분석할 수 있는 기능
데이터프레임이 저장한 데이터를 간단히 분석할 때, describe() 함수를 호출한다.
import pandas as pd
weather = pd.read_csv('d:/data/weather.csv',index_col = 0, encoding='CP949')
print(weather.descirbe())
print('평균 분석 ')
print(weather.mean())
print('표준편차 분석 ')
print(weather.std())
데이터 집계 분석
weather = pd.read_csv('d:/data/weather.csv',index_col = 0, encoding='CP949')
weather.count()
# 결과
# 평균기옥 3653
# 최대풍속 3649
# 평균풍속 3647
# dtype : int64
weather['최대풍속'].count()
# 3649
weather[['최대풍속','평균풍속']].count()
# 최대풍속 3649
# 평균풍속 3647
# dtype : int64
weather[['최대풍속','평균풍속']].mean()
# 최대풍속 7.911099
# 평균풍속 3.936441
# dtype : float64
weather.mean()[['최대풍속', '평균풍속']]
# 최대풍속 7.911099
# 평균풍속 3.936441
# dtype: float64
판다스로 울릉도의 바람 세기 분석

import pandas as pd
import matplotlib.pyplot as plt
weather = pd.read.csv('d:/data/weather.csv',encoding='CP949')
monthly = [None for x in range(12)] # 달별로 구분된 12개의 데이터프레임
monthly_wind = [0 for x in range(22)] # 각 달의 평균 풍속을 담을 리스트
# 마지막에 해당 행의 데이터가 측정된 달을 기록한 열을 추가
weather['month'] = pd.DatatimeIndex(weather['일시']).month
for i in range(12):
monthly[i] = weather[weather['month'] == i + 1] # 달별로 분리
monthly_wind[i] = monthly[i].mean()['평균풍속'] # 개별 데이터 분석
plt.plot(monthly_wind, 'red')
plt.show()
csv 모듈을 사용하는 것보다 간결하고 강력
import csv
import matplotlib.pyplot as plt
f = open('d:/data/weather.csv') # CSV 파일 열어 f에 저장
data = csv.reader(f) # reader() 함수로 읽기
header = next(data) # 헤더를 제거
monthly_wind = [0 for x in range(12)] # 매달 풍속을 담을 리스트, 초기화 0
days_counted = [0 for x in range(12)] # 각 달마다 측정된 일수, 초기화 0
for row in data:
month = int(row[0][5:7]) # 0번 열에서 달 정보 추출
if row[3] != '': # 풍속 데이터 존재하는지 확인
wind = foat(row[3]) # 풍속을 얻어 온다.
monthly_wind[month-1] += wind # 해당 달에 풍속 데이터 추가
days_counted[month-1] += 1 # 해당 달의 일수를 증가
for i in range(12):
monthly_wind[i] /= days_counted[i] # 일수로 나누어 월평균 구하기
plt.plot(monthly_wind, 'blue')
plt.show()
f.close() # 파일을 닫는다.
데이터를 특정한 값에 기반하여 묶는 기능 : 그룹핑 groupby()
울릉도는 몇 월에 바람이 가장 강할까? groupby() 활용
import pandas as pd
import matplotlib.pyplot as plt
import datatime as dt
weather = pd.read_csv('d:/data/weather.csv', encoding'CP949)
means = weather.groupby('month').mean()
means['평균풍속'].plot(kind = 'bar')
plt.show()
필터링 (조건에 맞게 골라내기)
weather['최대 풍속'] >= 10.0 : weather 데이터프레임에서 '최대풍속' 레이블로 되어 있는 열의 값이 10.0을 넘는지 확인하여 참과 거짓을 얻는 방법
weather[weather['최대 풍속'] >= 10.0] : 최대 풍속 레이블로 되어 있는 열의 값이 10.0을 넘는지 확인하여 참 값을 얻는 방법
weather[weather['평균풍속'].isna()] : 조건을 이용하여 데이터프레임의 일부를 가져오는 것
pandas.DataFrame.dropna(axis=0, how='any', inplace=False) : 빠진 값을 찾고 삭제하기(dropna)
빠진 데이터를 깨끗하게 메우기 : fillna
import pandas as pd
weather = pd.read.csv('d:/data/weather.csv',index_col = 0, encoding='CP949')
weather.fillna(0, inplace = True) # 결손값을 0으로 채움, inplace를 True로 설정해 원본 데이터 수정
print(weather.loc['2012-02-11'])
# 결과
# 평균 기온 -0.7
# 최대 풍속 0.0
# 평균 풍속 0.0
# Name: 2012-02-11, dtype: float64
# 빠진 데이터를 깨끗하게 메우기
weather['최대풍속'].fillna(weather['최대풍속'].mean(), inplace = True)
print(weather.loc['2012-02-11'])
# 평균기온 -0.70000
# 최대풍속 7.911099
# 평균풍속 NaN
# Name: 2012-02-11, dtype: float64
데이터 구조를 변경 : pivot
import pandas as pd
df_1 = pd.DataFrame({'item' : ['ring0','ring0','ring1','ring1'],
'type' : ['Gold','Silver','Gold','Bronze'],
'price' : [20000, 10000, 50000, 30000]})
df_2 = df_1.pivot(index='item',columns='type', values='price')
print(df_2)
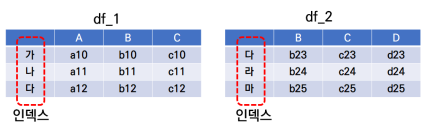
concat() 함수로 데이터프레임을 합친다.
df_1 = pd.DataFrame({'A' : ['a10', 'a11', 'a12'],
'B' : ['b10','b11','b12'],
'C' : ['c10','c11','c12']}, index = '가','나','다')
df_2 = pd.DataFrame({'B' : ['b23','b24','b25'],
'C' : ['c23','c24','c25'],
'D' : ['d23','d24','d25']}, index = ['다','라','마'])
df_3 = pd.concat([df_1,df_2]) # df_1, df_2 두 데이터프레임을 합쳐서 df_3을 생성
print(df_3)

import pandas as pd
df_1 = pd.DataFrame{{'A' : ['a10','a11','a12'],
'B' : ['b10','b11','b12'],
'C' : ['c10','c11','c12']},index=['가','나','다']}
df_2 = pd.DataFrame{{'B' : ['b23','b24','b25'],
'C' : ['c23','c24','c25'],
'D' : ['d23','d24','d25']},index=['다','라','마']}
print(pd.concat([df_1, df_2], axis = 0, join = 'outer'))
print(pd.concat([df_1, df_2], axis = 0, join = 'inner'))
print(pd.concat([df_1, df_2], axis = 1, join = 'outer'))
print(pd.concat([df_1, df_2], axis = 1, join = 'inner'))
데이터베이스 join 방식의 데이터 병합 - merge
df_3 = df_1.merge(df_2, how='outer',on='B')
print(df_3)
인덱스를 키로 활용하여 merge 적용해 보기
df_1.merge(df_2, how = 'outer', left_index = True, right_index = True)
df_3 = df_1.merge(df_2,how='outer',left_index = True, right_index = True)
print(df_3)

import pandas as pd
df_1 = pd.DataFrame({'A' : ['a10','a11','a12'],
'B' : ['b10','b11','b12'],
'C' : ['c10','c11','c12']}, index = ['가','나','다'])
df_2 = pd.DataFrame({'B' : ['b23','b24','b25'],
'C' : ['c23','c24','c25'],
'D' : ['d23','d24','d25']}, index = ['다','라','마'])
print('left outer \n', df_1.merge(df_2, how='left', on='B'))
print('right outer \n', df_1.merge(df_2, how='right', on='B'))
print('full outer \n', df_1.merge(df_2, how='outer', on='B'))
print('inner \n', df_1.merge(df_2, how='inner', on='B'))

데이터를 크기에 따라 나열 : sort_values
import pandas as pd
import matplotlib.pyplot as plt
countries_df = pd.read_csv('d:/data/countries.csv',index_col=0)
sorted = countries_df.sort_values('population')
print(sorted)
countries_df = pd.read_csv('d:/data/countires.csv',index_col = 0, encoding='CP949')
countires_df.sort_values(['population','area'],ascending = False, inplace = True)
print(countires)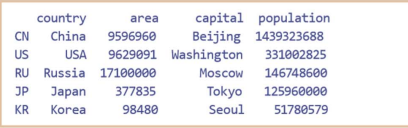
How to create plots in pandas
import pandas as pd
import matplotlib.pyplot as plt
참고 자료
- 따라하며 배우는 파이썬과 데이터 과학, 생능 출판사 강의자료
- Python 수업 자료
