
참조
안드로이드 developer - Parse XML data
안드로이드 developer - XmlPullParser
개발자 블로그
깡썜의 안드로이드 프로그래밍
틀린 부분 댓글로 남겨주시면 수정하겠습니다..!!
XML 파싱
서버와 데이터 통신을 할 때 서버로부터 수신하는 문자열 데이터는 XML이나 JSON 데이터입니다. 이러한 데이터를 받고 XML, JSON을 파싱해서 원하는 결과를 추출하는 것입니다. 안드로이드 라이브러리에서 XML 파서가 제공되는데 이것을 사용하여 XML을 파싱하면 됩니다.
XML
XML은 주로 다른 종류의 시스템, 특히 인터넷에 연결된 시스템끼리 데이터를 쉽게 주고 받을 수 있게 하여 HTML의 한계를 극복할 목적으로 만들어졌습니다.
XML을 파싱하는 방법으로는 DOM 파서를 이용하거나 SAX 파서를 이용하거나 Pull 파서를 이용하면 됩니다. 안드로이드 공식 사이트에서는 Pull 파서를 이용하는 방법을 추천하고 있기에 DOM 파서와 SAX 파서는 설명만 하고 Pull 파서를 이용해 XML을 파싱하겠습니다.
DOM 파서
DOM 파서는 흔히 OOP(Object-Oriented Programming) 방식의 파서라고 부릅니다. XML 각 구성요소를 객체로 만들고 객체 간의 계층구조를 만들어 데이터를 추출하는 방식입니다.
<Root>
<A>
<A1></A1>
<A2></A2>
<A3></A3>
</A>
<B></B>
</Root>위의 XML을 파싱하면 객체가 여러 개 생성되고 각 객체에 데이터가 담기며, 전체 객체가 계층 구조로 만들어집니다.
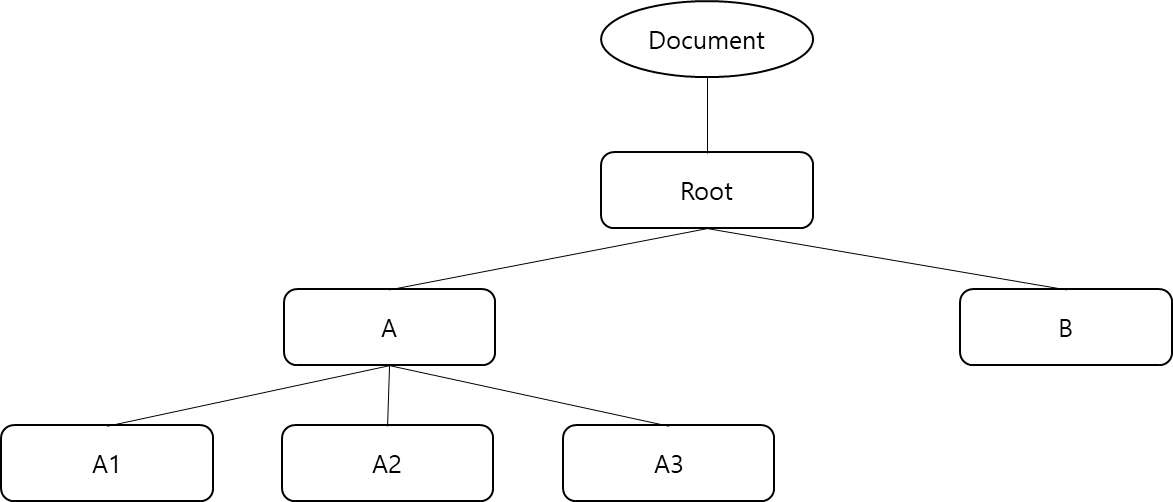
이 XML을 DOM을 통해 파싱하면 위와 같은 계층 구조가 만들어집니다. Document 객체는 XML 문서를 지칭하는 최상위 객체이며, 나머지 네모 박스는 각 태그에 해당하는 객체입니다. 이 객체에 각 태그의 이름과 속성등이 저장되어 이를 통해 데이터를 얻어오는 방식입니다.
SAX 파서
DOM 파서의 구조가 XML의 각 구성요소를 객체로 생성하여 파싱하는 OOP 방식이라면, SAX 파서는 이벤트 방식입니다. SAX 파서는 객체를 만들지 않고 단순히 이벤트만 발생시켜 등록된 이벤트 핸들러의 함수를 호출해주는 역할을 합니다.
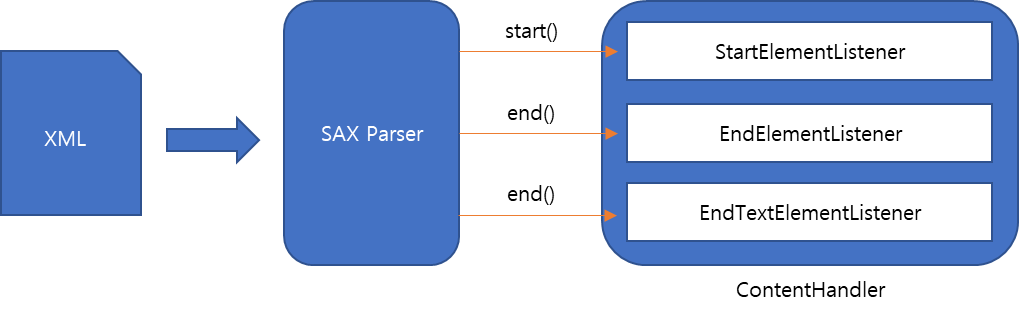
코드에서 특정 Element(태그)의 이벤트 핸들러를 등록해 놓으면 SAX 파서가 주어진 XML을 위부터 순서대로 해석하다가 특정 태그를 만나면 등록된 이벤트 핸들러의 함수를 호출해 주는 개념입니다.
Pull 파서(XmlPullParser)
Pull 파서도 SAX와 마찬가지로 이벤트 중심의 파서입니다. XML 구성요소를 순서대로 파싱하면서 각 이벤트 타입이 발생하고, 발생한 이벤트 타입에 맞는 개발자 코드가 실행되는 구조입니다. SAX 파서와 다른 점은 SAX 파서는 파싱이 시작되면 등록된 모든 이벤트 핸들러가 실행되어 XML 문서끝까지 파싱되는데, Pull 파서는 특정 위치까지 파싱되어 내용을 처리한 후 계속 파싱할 것인지 멈출 것인지를 개발자가 제어할 수 있는 특징이 있습니다.
XmlPullParser를 이용하여 XML을 파싱하면 되는데 XmlPullParser는 위의 사진과 같이 인터페이스입니다. 그렇다고 이 인터페이스를 상속받은 클래스를 생성하고 그 클래스에 XmlPullParser에 선언된 함수들을 모두 구현해야 할 필요는 없습니다. 안드로이드에서 제공되는, XmlPullParser 인터페이스의 XML 파싱 기능이 구현된 클래스가 두 가지 있습니다.

XmlPullParserFactory.newPullParser()를 통해 만드는 KXmlParser와 Xml.newPullParser()를 이용해 만드는 ExpatPullParser 이 둘을 사용하면 됩니다.
XML 파서 초기화
위의 두 파서는 자신의 인스턴스를 생성하는 역할을 담당하는 특정 클래스의 함수 호출을 통해 생성됩니다. 즉, KXmlParser는 XmlPullParserFactory.newPullParser() 함수를 통해 생성되고, ExpatPullParser는 Xml.newPullParser() 함수 호출을 통해 생성됩니다.
KxmlParser 생성
XmlPullParserFactory를 통해 XmlPullParser 인스턴스는 아래와 같이 만듭니다.
try {
val parserFactory = XmlPullParserFactory.newInstance()
val kXmlParser = parserFactory.newPullParser()
} catch(e: Exception) {
}ExpatPullParser 생성
Xml 클래스의 newPullParser() 함수를 통해 XmlPullParser 인스턴스는 아래와 같이 만듭니다.
try {
val parser = Xml.newPullParser()
} catch(e: Exception) {
}두 가지 파서의 초기화 방법은 다르지만, 초기화를 통해 얻어지는 XML 파서의 인스턴스는 XmlPullParser 타입으로 참조가 가능합니다. 그러므로 XML 파서 생성 과정 외에, 실질적인 XML 데이터 파싱 과정은 파서 종류에 상관이 없습니다.
XML 파서 입력 스트림 지정
XML 파서의 입력 스트림을 지정하기 위해서 XmlPullParser의 setInput() 함수를 사용하는데 InputStream 또는 Reader를 매개변수로 주면 파싱을 시작하게 됩니다. 메서드는 아래와 같이 오버로딩 되어있고 상황에 맞게 선택하면 됩니다.
- setInput(Reader in)
- setInput(InputStream inputStream, String inputEncoding)
// assets 폴더안에 있는 XML 파일을 열어 InputStream 객체 생성
val inputStream: InputStream = assets.open("test.xml")
// inputStream 지정
parser.setInput(inputStream, null)위의 예제는 assets 폴더 안에 있는 XML 파일을 열고 setInput()의 매개변수로 지정한 것입니다.
XML 데이터 파싱
위에서 언급하였듯이 Pull 파서 또한 SAX 파서와 마찬가지로 이벤트 방식입니다. 핵심은 이벤트를 넘어가며 이벤트의 타입을 얻어와 그 타입을 검사하여 자신에게 필요한 것인지를 확인하는 방식으로 파싱하는 것입니다. 이벤트 타입은 아래와 같습니다.
- START_DOCUMENT: 해당 파서가 XML 문서의 맨 처음에 표시됩니다. 파싱의 시작
- START_TAG: XML 시작 태그(ex.
<TAG> - END_TAG: XML 끝 태그(종료 태그)(ex.
</TAG> - TEXT: XML에 포함된 문자 데이터(ex.
<TAG>TEXT</TAG> - END_DOCUMENT: XML 문서의 끝. 더이상의 이벤트가 없음을 알림
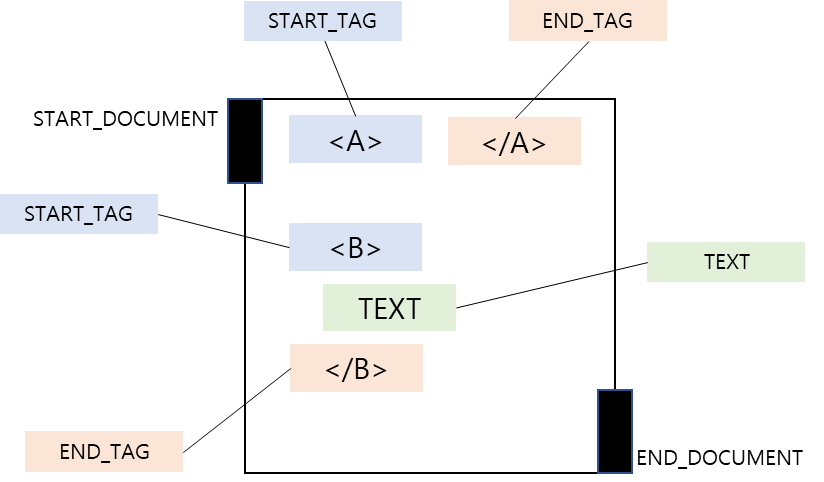
파싱하기 위해서는 두 개의 주요 메서드가 존재합니다. next() 메서드와 nextToken() 메서드입니다. next() 메서드는 파서를 다음 이벤트로 넘어가는 것이고 nextToken() 메서드는 next() 메서드와 비슷하지만 추가 이벤트 유형(COMMENT, CDSECT, DOCDECL 등)이 사용가능할 때 사용하는 메서드입니다.
xml 파일
<current>
<city id="1835848" name="Seoul">
<coord lon="126.98" lat="37.57"/>
<country>KR</country>
<sun rise="2017-03-28T21:21:49" set="2017-03-29T09:52:15"/>
</city>
<temperature value="11.01" min="7" max="13" unit="metric"/>
</current>xml을 파싱하는 간단한 코드
// getEventType() 메서드를 사용해 이벤트 타입을 얻어오는데
// 처음으로 호출되므로 START_DOCUMENT가 호출
var eventType = parser.eventType
var done = false
// eventType이 End_Document가 아니고 done이 false일 경우 반복
while(eventType != XmlPullParser.END_DOCUMENT) {
// 이름을 저장하기 위한 변수
var name: String? = null
// eventType이 START_TAG인 경우
if(eventType == XmlPullParser.START_TAG) {
// getName() 메서드를 사용해 현재 요소(태그)의 이름을 반환
name = parser.name
// 태그의 이름이 city인 경우
if(name == "city") {
// getAttributeValue를 사용해 첫 번째 매개변수 및
// 두 번째 매개변수로 식별된 특성 값 획득
cityView.text = parser.getAttributeValue(null, "name")
} else if(name == "temperature") {
temperatureView.text = parser.getAttributeValue(null, "value")
}
}
// 다음 이벤트로 넘기기
eventType = parser.next()
}xml 데이터를 파싱하는 코드입니다.
- XmlPullParser.getEventType() 메서드를 사용하여 현재의 이벤트 타입을 획득합니다
(가장 먼저 호출되었기에 시작에 해당하는 START_TAG가 호출) - while문 안에서 이벤트 타입을 확인하며 END_DOCUMENT(XML 문서의 끝)이 아닐 때까지 반복문을 돌립니다
- eventType이 START_TAG(시작태그, 위의 xml 예제에서는 current, city 등)라면 XmlPullParser.getName()을 호출하여 현재 요소의 이름을 획득합니다
- 이름이 자신이 원하는 데이터인 경우(위의 예에서는 city, temperature) XmlPullParser.getAttributeValue() 메서드를 호출하여 속성값을 획득합니다(city 태그 안에 있는 name 속성을 획득)
- 그리고 while문의 마지막에 XmlPullParser.next()를 호출하여 다음 이벤트로 넘어갑니다.
