인공지능 학문은 '예측'에서부터 시작한다.
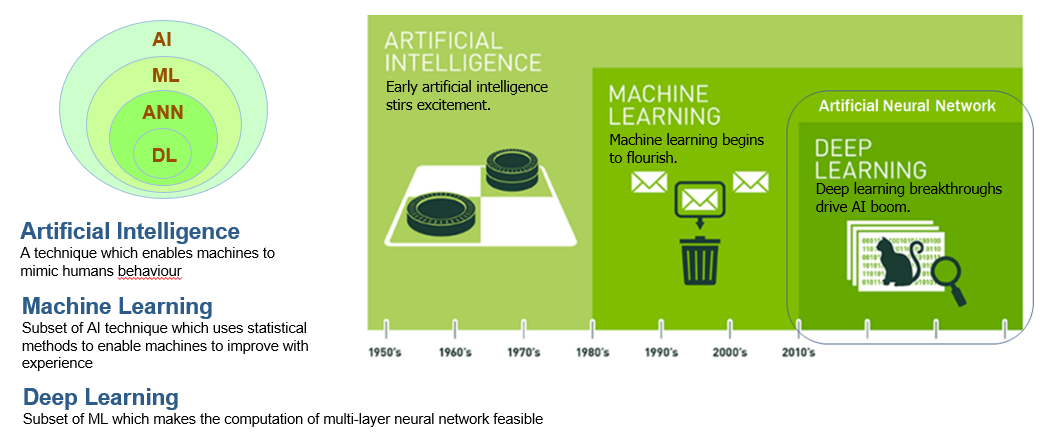
머신러닝은 인공지능의 하위 학문으로 기계가 스스로 학습할 수 있도록 통계적 식을 제공하여 연산할 수 있도록 하는 AI 기술의 하위집합니다.
머신러닝(machine learning)은 컴퓨터가 학습할 수 있도록 하는 알고리즘(처리 방법)과 기술을 개발하는 분야로, 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단이나 '예측'한다.
인공지능의 4가지 유형
- 지도 학습 (Supervised Learning)
- 정답이 있는 데이터를 활용해 데이터를 학습시킨다.
- 종류 : 분류, 회귀
- 비지도 학습 (Unsupervised Learning)
- 정답이 없는 데이터를 군집화하여 새로운 데이터에 대한 결과를 예측하는 방법
- 종류 : 클러스터링, k-means
- 준지도 학습 (Semi supervised)
- 지도 학습과 비지도 학습의 중간에 해당하는 기술로, 명확한 정답이 존재하나 정답이 있는 데이터를 구하기 힘들 때 사용
- 강화 학습 (Reinforcement Learning)
- 주어진 환경에서 어떤 행동을 취하고 이로부터 어떤 보상을 얻으면서 학습을 진행
- 개념 : 에이전트, 환경, 상태, 행동, 보상
딥러닝(Deep Learning)
딥러닝은 머신러닝의 한 분야로, 뇌의 뉴런과 유사한 정보 입력층 계층을 활용해 데이터를 학습하는 방법이다. 딥러닝은 추 후 딥러닝 항목에서 다룬다.
빅데이터 분석 절차
머신러닝은 기본적으로 대량의 데이터인 빅데이터를 학습데이터로 사용한다. 예측모델에서 주로 지도학습을 사용하는데 이때 학습에 사용되는 속성을 '독립변수'라고 하고 이에 따르는 정답 data를 '종속변수'라고 한다.
일반적으로 머신러닝을 활용한 빅데이터의 분석절차는 다음과 같다.
- 기획
- 데이터수집
- 데이터전처리 (통계적 데이터분석)
- 모델선택과 학습
- 평가 및 적용
다음의 순서를 거쳐 만들어진 데이터 예측 모델들은 통상적으로 95%가 넘으면 상용화가 가능하다고 본다. 하지만 현업에서는 대략 70%이상의 정확도만 보이면 만족한다고 한다.
우연이 99%이상의 정확도가 나온다고 하여도 이것이 완벽한 모델이라고는 장담할 수 없다. 우리가 그것을 신뢰할 수 있는지, 문제가 있다면 어떤걸 고쳐야 하는지 확인하는 과정이 중요하다.

창헌의 개발블로그