BiLSTM을 활용한 감정 분석
- 실행 환경 : 구글 Colab
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
%cd Mecab-ko-for-Google-Colab
!bash install_mecab-ko_on_colab190912.sh
import os import pandas as pd import numpy as np import matplotlib.pyplot as plt import urllib.request from collections import Counter from konlpy.tag import Mecab from sklearn.model_selection import train_test_split from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences # 데이터 로드 urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/steam.txt",filename="steam.txt") total_data = pd.read_table('steam.txt',names=['label','reviews']) print('len : ',len(total_data)) > len : 100000 total_data
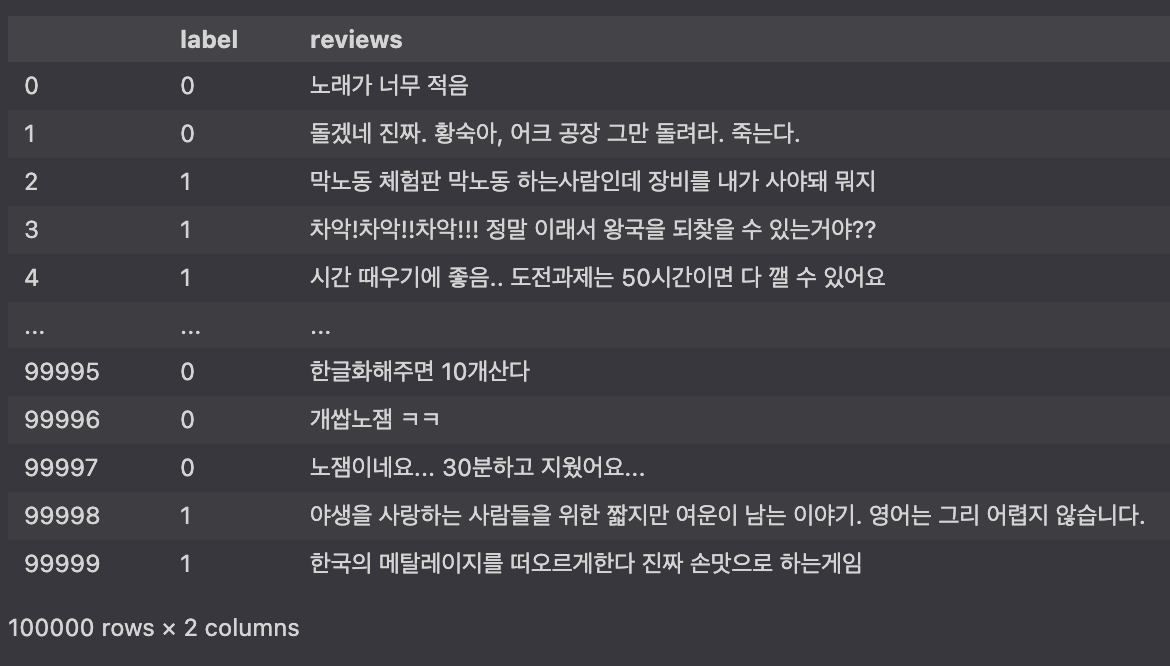
# 중복되지 않은 유니크한 리뷰 total_data['reviews'].nunique() > 99892
# 중복 데이터 제거 total_data.drop_duplicates(subset=['reviews'],inplace=True) print('len : ',len(total_data)) > len : 99892
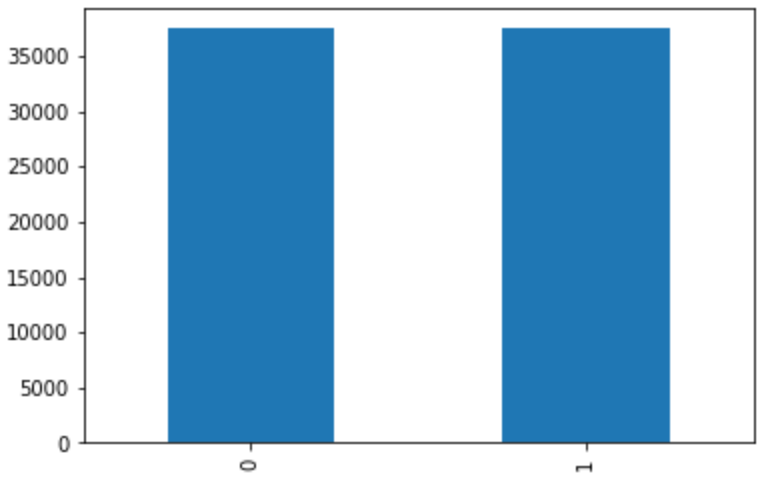
# 훈련 및 테스트 데이터 분리 train_data, test_data = train_test_split(total_data,test_size=0.25,random_state=2021) # 훈련 데이터 라벨 비율 확인 train_data['label'].value_counts() >0 37473 1 37446 Name: label, dtype: int64 train_data['label'].value_counts().plot(kind='bar')
# 정규표현식을 통해 한글을 제외한 모두 제거 train_data['reviews'] = train_data['reviews'].str.replace('[^ㄱ-ㅎㅏ-ㅣ가-힣]',"") # 위 과정을 통해서 빈 샘플이 생기지는 않는지 확인 train_data['reviews'].replace('',np.nan,inplace=True) print(train_data.isnull().sum()) > label 0 reviews 0 dtype: int64
# test 데이터에도 똑같이 적용 test_data.drop_duplicates(subset=['reviews'],inplace=True) test_data['reviews'] = test_data['reviews'].str.replace('[^ㄱ-ㅎㅏ-ㅣ가-힣]','') test_data['reviews'] = test_data['reviews'].replace('',np.nan) print(test_data.isnull().sum()) > label 0 reviews 0 dtype: int64
# 불용어 정의 # 불용어란 : 불용어(Stop word)는 분석에 큰 의미가 없는 단어를 지칭합니다. # 예를 들어 the, a, an, is, I, my 등과 같이 문장을 구성하는 필수 요소지만 문맥적으로 큰 의미가 없는 단어가 이에 속합니다. stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게', '만', '게임', '겜', '되', '음', '면']
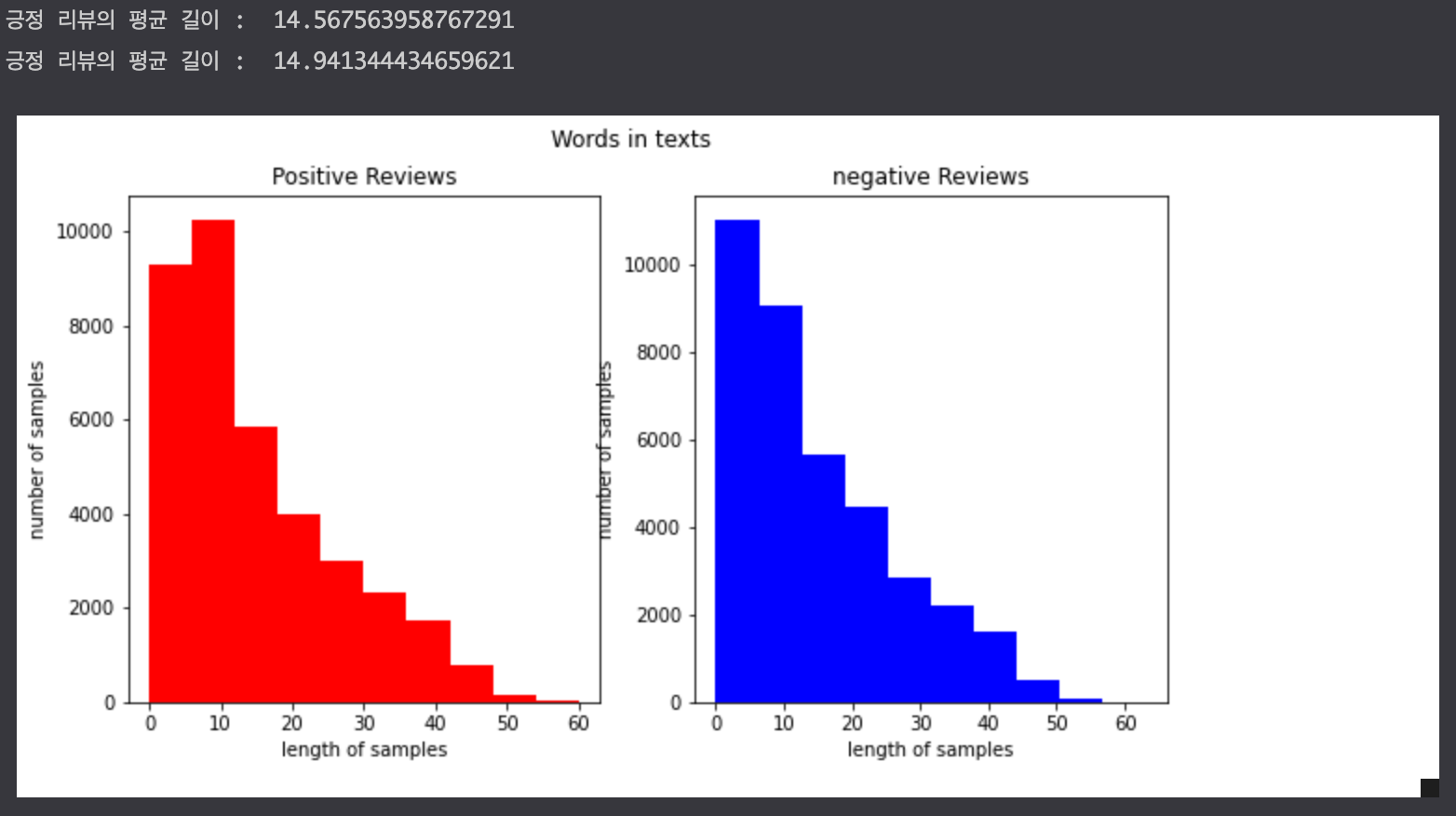
# tokenize # 형태소 분석기 메캅을 사용하여 토큰화 작업을 수행한다. mecab = Mecab() train_data['tokenized'] = train_data['reviews'].apply(mecab.morphs) train_data['tokenized'] = train_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords]) test_data['tokenized'] = test_data['reviews'].apply(mecab.morphs) test_data['tokenized'] = test_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords]) # 단어와 길이 분포 확인하기 # 긍정 리뷰에는 주로 어떤 단어들이 많이 등장하고, 부정 리뷰에는 주로 어떤 단어들이 등장하는지 두 가지 경우에 대해서 각 단어의 빈도수를 계산 negative_words = np.hstack(train_data[train_data.label==0]['tokenized'].values) positive_words = np.hstack(train_data[train_data.label==1]['tokenized'].values) ># Counter()를 사용해서 각 부정 단어에 대한 빈도수 카운트 negative_word_count = Counter(negative_words) print("부정 : ",negative_word_count.most_common(20)) > 부정 : [('안', 7796), ('없', 6823), ('있', 5663), ('는데', 5603), ('같', 4056), ('로', 4049), ('할', 3807), ('거', 3716), ('해', 3567), ('나', 3567), ('너무', 3474), ('으로', 3370), ('기', 3239), ('했', 3235), ('어', 3138), ('지만', 2990), ('습니다', 2933), ('않', 2888), ('좋', 2886), ('것', 2875)] # Counter()를 사용해서 각 긍정 단어에 대한 빈도수 카운트 positive_word_count = Counter(positive_words) print("긍정 : ",positive_word_count.most_common(20)) > 긍정 : [('있', 9668), ('좋', 6230), ('습니다', 5078), ('지만', 4750), ('할', 4689), ('재밌', 4563), ('해', 4195), ('없', 4126), ('으로', 3794), ('수', 3762), ('로', 3755), ('보', 3742), ('는데', 3618), ('기', 3541), ('것', 3308), ('같', 3255), ('안', 3252), ('어', 3055), ('나', 2978), ('네요', 2972)] # 긍정과 부정에 대한 유의미한 길이 차이가 있어보이지 않는다. fig,(ax1,ax2) = plt.subplots(1,2,figsize=(10,5)) text_len = train_data[train_data['label']==1]['tokenized'].apply(lambda x:len(x)) ax1.hist(text_len,color='red') ax1.set_title('Positive Reviews') ax1.set_xlabel('length of samples') ax1.set_ylabel('number of samples') print('긍정 리뷰의 평균 길이 : ',np.mean(text_len)) text_len = train_data[train_data['label']==0]['tokenized'].apply(lambda x:len(x)) ax2.hist(text_len,color='blue') ax2.set_title('negative Reviews') fig.suptitle('Words in texts') ax2.set_xlabel('length of samples') ax2.set_ylabel('number of samples') print('긍정 리뷰의 평균 길이 : ',np.mean(text_len)) plt.show()
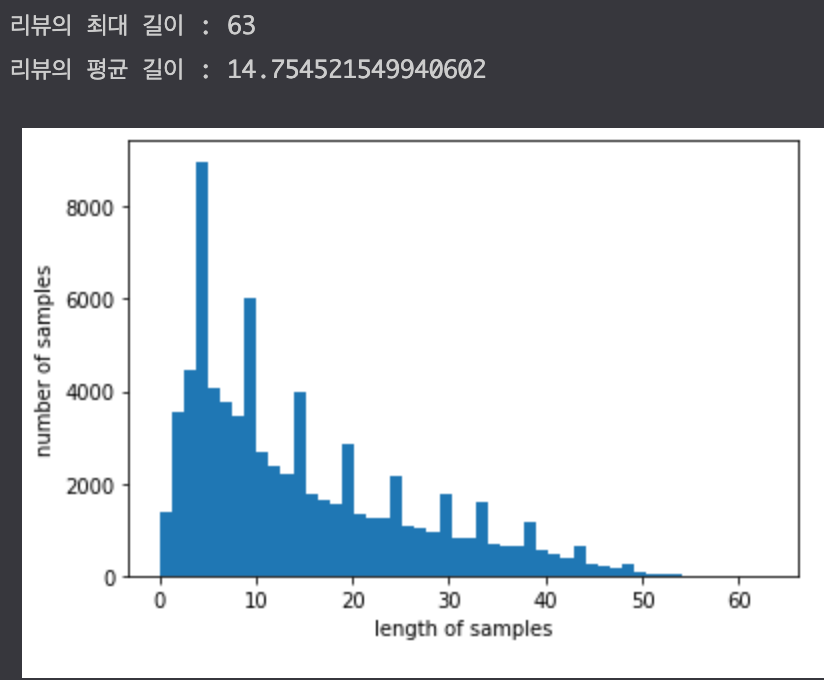
x_train = train_data['tokenized'].values y_train = train_data['label'].values x_test = test_data['tokenized'].values y_test = test_data['label'].values # 정수 인코딩 # 기계가 텍스트를 숫자로 처리할 수 있도록 훈련 데이터와 테스트 데이터에 정수 인코딩을 수행 # 훈련 데이터에 대해서 단어 집합(vocaburary) 생성 tokenizer = Tokenizer() tokenizer.fit_on_texts(x_train) # 단어 집합이 생성되는 동시에 각 단어에 고유한 정수 부여 # 이는 tokenizer.word_index를 출력하면 확인 가능 # 등장 횟수가 1회인 단어들은 자연어 처리에 배제 # 이 단어들이 이 데이터에서 얼마만큼의 비중을 차지하는지 확인 threshold = 2 total_cnt = len(tokenizer.word_index) rare_cnt = 0 # 등장 빈도수가 threshold 보다 작은 단어의 개수를 카운트 total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합 rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 빈도수의 총합 # 단어의 빈도수의 쌍을 key와 value로 받는다. for key, value in tokenizer.word_counts.items(): total_freq = total_freq + value # 단어의 등장 빈도수가 threshold 보다 작으면 if value < threshold: rare_cnt = rare_cnt + 1 rare_freq = rare_freq + value print('단어 집합(vocabulary)의 크기 :',total_cnt) print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt)) print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100) print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100) >단어 집합(vocabulary)의 크기 : 39992 등장 빈도가 1번 이하인 희귀 단어의 수: 19596 단어 집합에서 희귀 단어의 비율: 48.999799959991996 전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.7727599636329094 ># 단어가 약 39,000개 존재하는데, 등장 빈도가 1회인 단어들은 단어 집합에서 48%를 차지한다. # 하지만 실제 훈련 데이터에서 등장하는 빈도로 차지하는 비중은 1.7%로 매우 적다. # 아무래도 등장 빈도가 1회인 단어들은 자연어 처리에서 별로 중요하지 않을 듯 하다. # 그래서 해당 단어들은 정수 인코딩 과정에서 배제시킬 것임 # 전체 단어 개수 중 빈도수 2이하인 단어 개수는 제거 # 0번 패딩 토큰과 00V 토큰을 고려하여 +2 vocab_size = total_cnt - rare_cnt + 2 print("단어 집합의 크기 : ",vocab_size) > 단어 집합의 크기 : 20398 # 이제 단어 집합의 크기는 18,941개이다. 이를 토크나이저의 인자로 넘겨주면, 토크나이저는 텍스트 시퀀스를 숫자 시퀀스로 변환한다. # 이러한 정수 인코딩 과정에서 이보다 큰 숫자가 부여된 단어들은 OOV로 변환 tokenizer = Tokenizer(vocab_size,oov_token='OOV') tokenizer.fit_on_texts(x_train) x_train = tokenizer.texts_to_sequences(x_train) x_test = tokenizer.texts_to_sequences(x_test) # 패딩 # 서로 다른 길이의 샘플들을 동일하게 맞춰주는 패딩 작업을 진행 # 전체 데이터에서 가장 길이가 긴 리뷰와 전체 데이터의 길이 분포 확인 print('리뷰의 최대 길이 :',max(len(l) for l in x_train)) print('리뷰의 평균 길이 :',sum(map(len, x_train))/len(x_train)) plt.hist([len(s) for s in x_train], bins=50) plt.xlabel('length of samples') plt.ylabel('number of samples') plt.show()
def below_threshold_len(max_len,nested_list): cnt = 0 for s in nested_list: if len(s)<=max_len: cnt = cnt + 1 print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100)) # 훈련용 리뷰 99.99%가 60% 이하의 길이를 가진다. # 훈련용 리뷰의 길이를 60으로 패딩 max_len = 60 below_threshold_len(max_len,x_train) x_train = pad_sequences(x_train,maxlen=max_len) x_test = pad_sequences(x_test,maxlen = max_len) # BiLSTM으로 스팀 리뷰 감성 분류 import re from tensorflow.keras.layers import Embedding, Dense, LSTM, Bidirectional from tensorflow.keras.models import Sequential from tensorflow.keras.models import load_model from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint model = Sequential() model.add(Embedding(vocab_size,100)) model.add(Bidirectional(LSTM(100))) model.add(Dense(1,activation='sigmoid')) es = EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=10) mc = ModelCheckpoint('best_model.h5',monitor='val_acc',mode='max',verbose=1,save_best_only=True) model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc']) history = model.fit(x_train,y_train, epochs=200, callbacks=[es,mc], batch_size=256, validation_split=0.2) loaded_model = load_model('best_model.h5') print('테스트 정확도 : %.4f'%(loaded_model.evaluate(x_test,y_test)[1])) > 781/781 [==============================] - 4s 4ms/step - loss: 0.4661 - acc: 0.7781 테스트 정확도 : 0.7781 def sentiment_predict(new_sentence): new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣]','',new_sentence) new_sentence = mecab.morphs(new_sentence) # 토큰화 new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거 encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩 pad_new = pad_sequences(encoded, maxlen=max_len) # 패딩 score = float(loaded_model.predict(pad_new)) # 예측 if(score > 0.7): print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100)) elif score < 0.3: print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100)) else: print("{:.2f}% 확률로 판단 애매합니다.".format((1 - score) * 100)) sentiment_predict('좋다') > 84.72% 확률로 긍정 리뷰입니다.
참고 블로그 : https://wikidocs.net/94748

데이터 분석 유튜버 "거친코딩"입니다.