
글을 시작하며
데이터 분석가의 커리어UP을 위한 엔지니어링 기술 소개 여정을, 지난 S3의 소개에 이어서 계속해서 오늘도 이어나가 보도록 하겠습니다.
최근 데이터 사이언스가 업계에서 매력적이라고 평가를 받으면서,
그리고 특히 대중들에게 데이터 사이언스가 매력적으로 느껴지게 된 이유는, 파이썬 프로그래밍 언어의 인기와 파이썬이 가지는 강력한 라이브러리 모음들이 있었기 때문이 아닐까라는 생각이 듭니다.
이렇게 사랑을 받는 만큼 데이터 사이언스 기술에 대한 발달과 컴퓨팅 기술은 점차 강력해지고 있고, 데이터 사이언티스트라면 파이썬을 가지고 실제 데이터 분석에 필요한 라이브러리(판다스, 사이파이, 넘파이, 사이킷런)를 자주 사용하게 된다.
하지만 요즘 시대에는 데이터 수집 및 저장 비용이 점차 낮아지면서,즉 날로날로 저장 기술이 더욱 뛰어 나지면서, 데이터사이언티스트들에게 "너희들이 원하는 데이터 이만큼 잘 수집했는데, 이제는 분석 잘하겠지?"라고 막대한 크기의 데이터셋을 분석해 달라는 요구가 쏟아지게 됩니다.
하지만 위 그림처럼 이 모든 라이브러리는 컴퓨터 메모리 RAM에 문제없이 저장되는 작은 크기의 데이터셋에 적합한데, 이러한 방대한 크기의 데이터셋을 인메모리 방식의 파이썬 라이브러리로 처리하게 된다면 성능저하 및 구현 불가를 절대 피할 수 없게 됩니다.

그래서 이러한 경우를 해결 하기 위해 제가 소개해드릴 기술이 "Dask"입니다.
Dask란 무엇인가?

Dask는 파이썬 오픈 데이터 과학 스택에 본질적인 확장성을 가지게 하고, 단일 코어의 한계를 뛰어 넘도록 하게 하는 것이 목표로 하고 있고,
오늘날 빅데이터 분석에서 대용량 데이터를 다루기 위한 분산 컴퓨팅 도구이면서
2014년 말에 "매튜 록린" 이라는 사람이 처음 개발하였습니다.
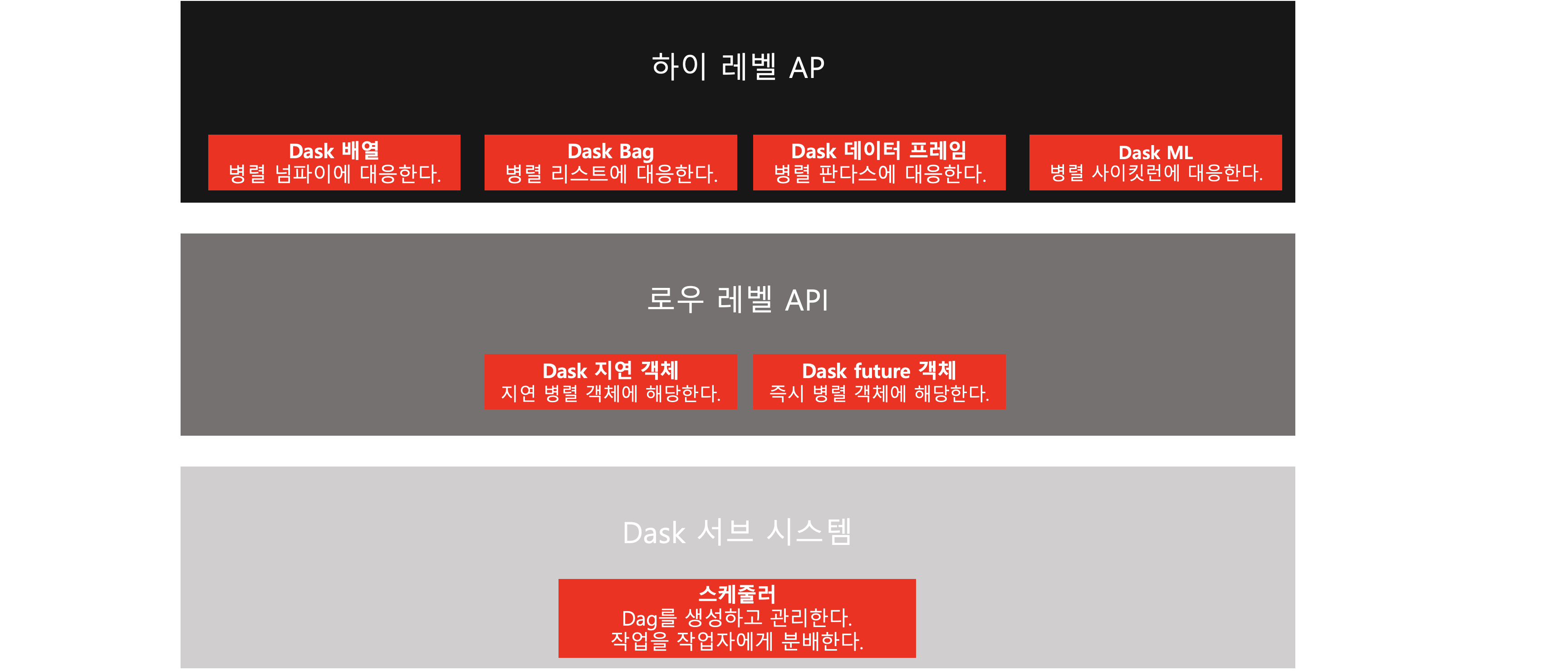
그리고 위 그림처럼 Dask는 여러 개의 서로 다른 컴포넌트와 API
즉 스케줄러, 로우레벨 API, 하이레벨 API의 세 개 계층으로 분류되어있습니다.
이러한 컴포넌트들과 계층들의 상호작용 방식들 덕분에 Dask는 더욱 강력해지는데,
간단하게 "CPU 코어와 컴퓨터 머신의 연산 실행을 조직하고 모니터링을 잘한다"라고 생각하면 된다.
사실 이렇게 Dask의 원초적인 구조를 설명드리게 되면 약간 이해하기 어려울 수 있어서,
크게 4가지의 장점 정도만 가진다라고 이해하면 될것 같습니다.
Dask의 장점
파이썬 분석 라이브러리들과의 확장성
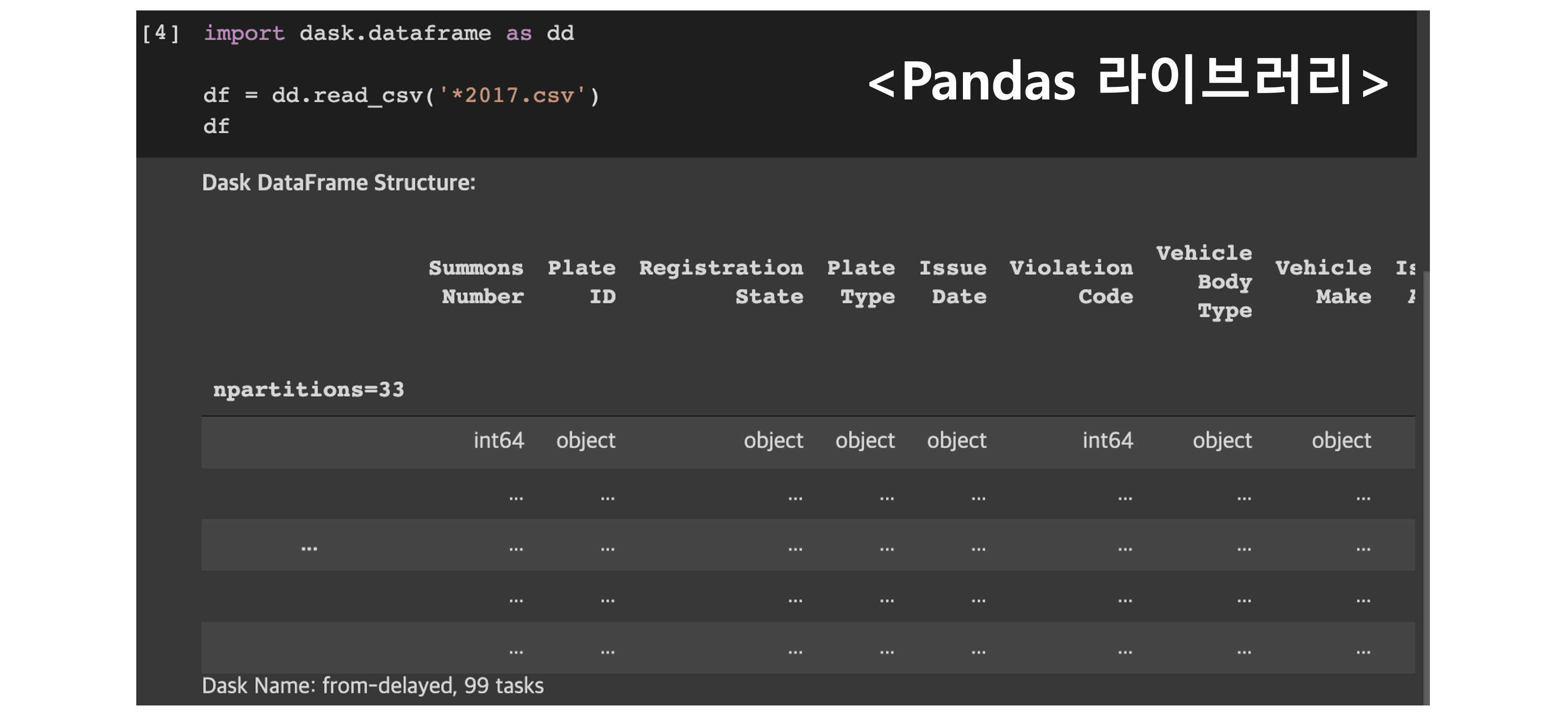
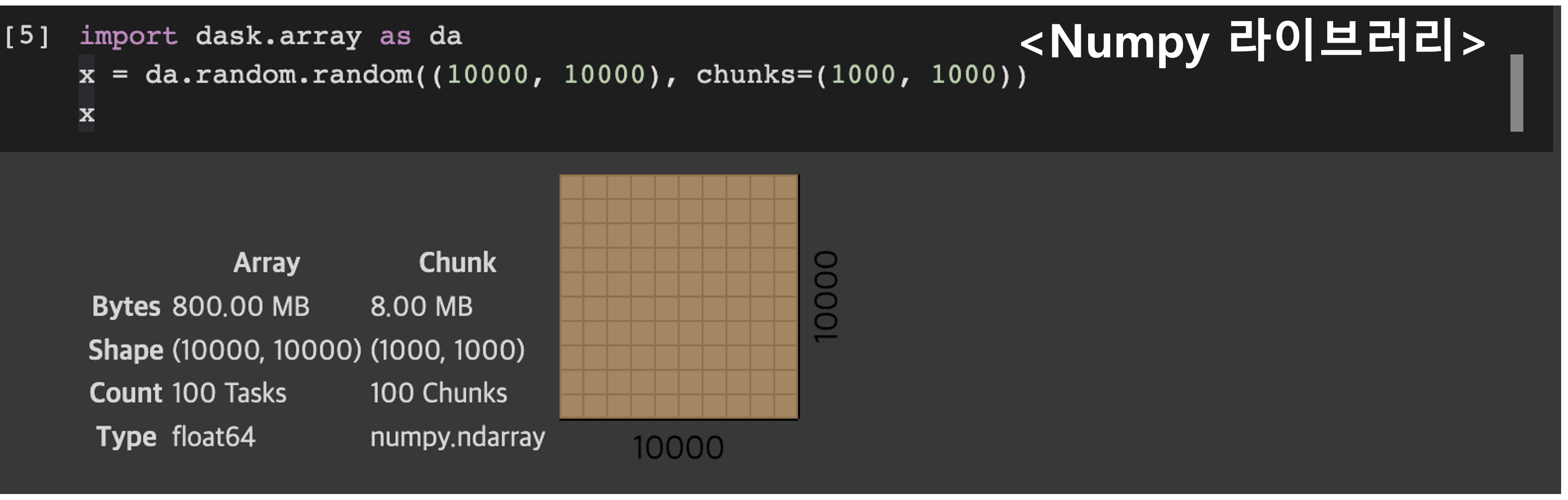
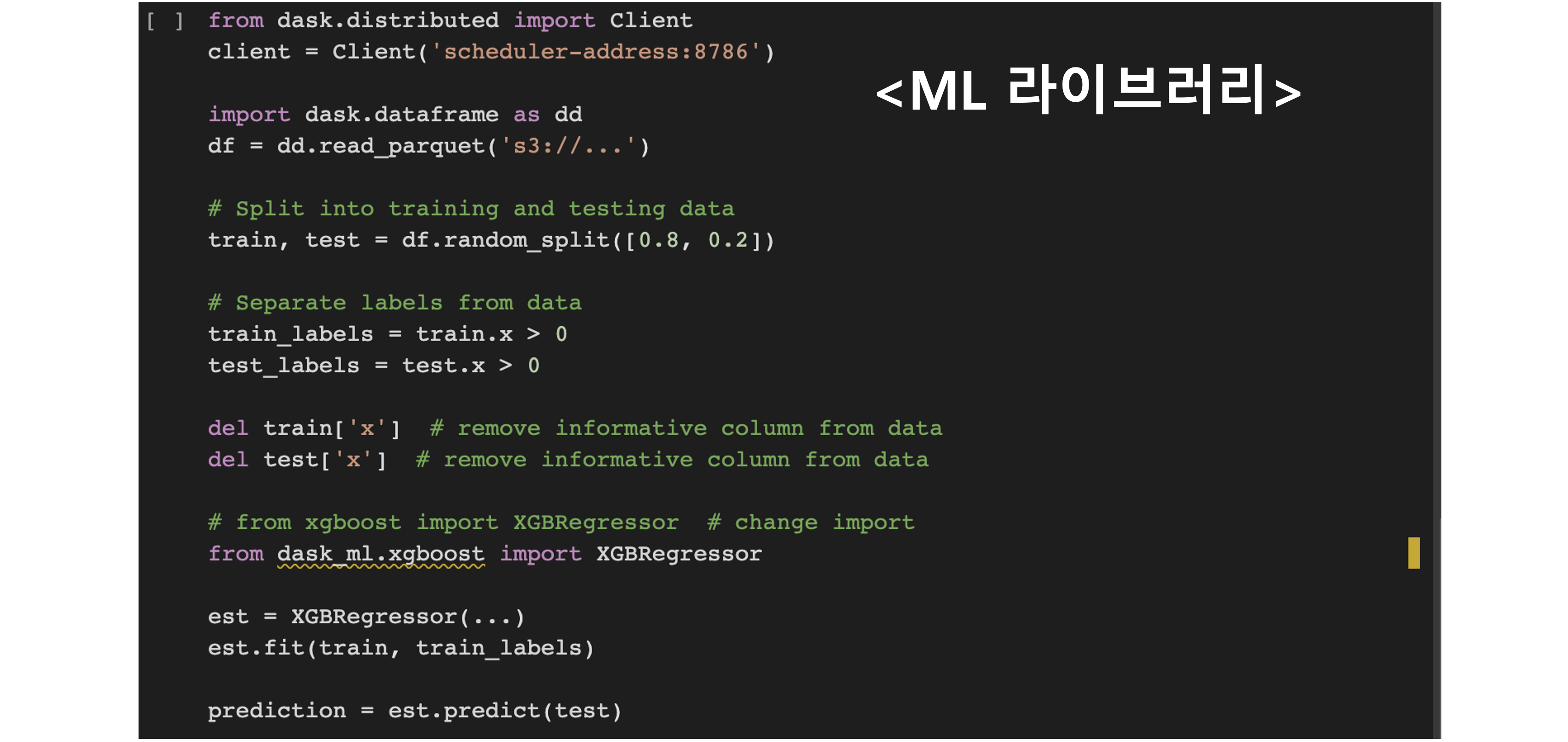
- 데이터분석 하시는 분들에게는 이미 Pandas, Numpy, Scikit-Learn등과 같은 라이브러리의 속성과 메서드가 익숙한데, Dask는 이러한 라이브러리의 특징을 그대로 상속받아서 사용하기 때문에, 만약 기존 코드에서 Dask로 전환한다고 하더라도 큰 코드 리팩토링 과정 없이 빠른 피벗이 가능합니다.
단일 컴퓨터 머신으로 큰 데이터셋을 효과적으로 작업 가능
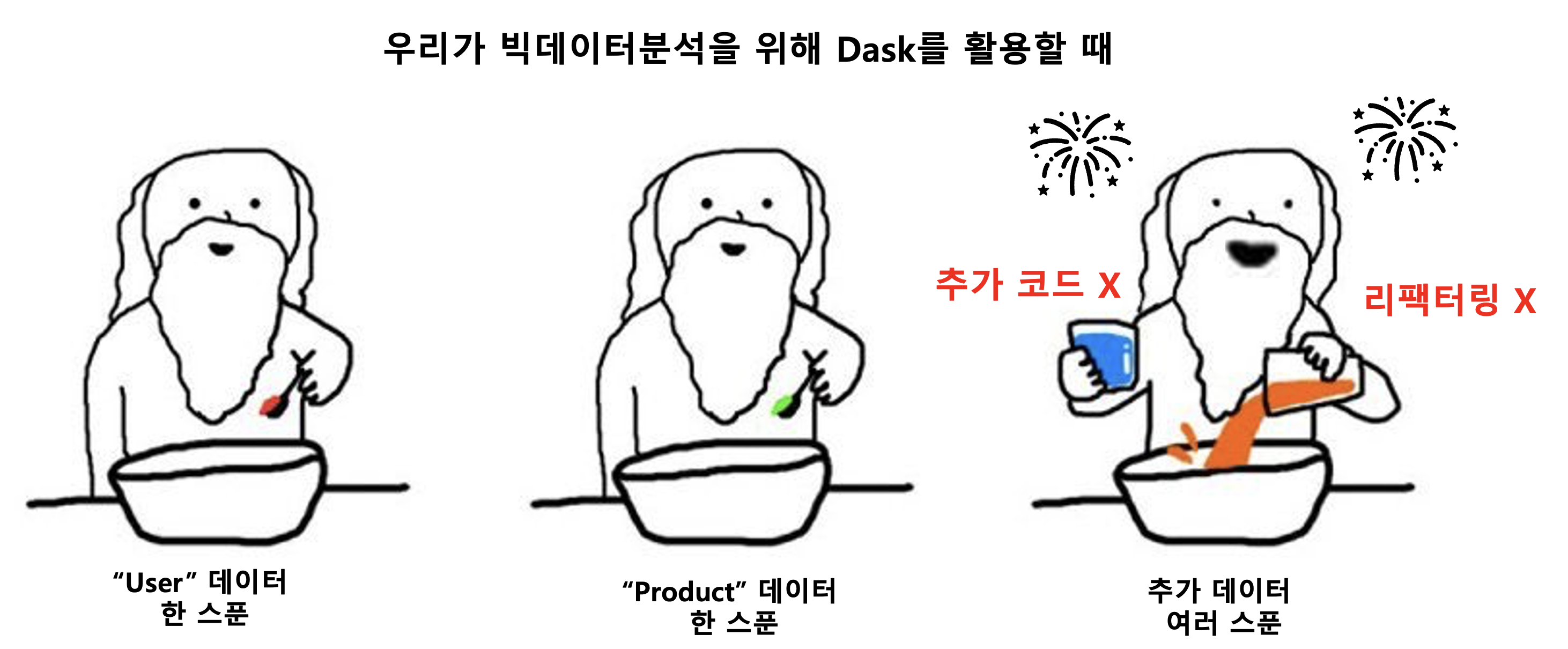
- 데이터가 갑자기 더욱 커든지 관계없이, 기존 코드를 리팩터링 하거나, 추가로 코드를 작성하지 않고 Dask의 내장된 작업 스케줄러를 통해서 해결할 수 있다.
파이썬 객체 병렬화를 위한 일반적 프레임워크

- Dask의 특이한 점 중 하나는 대부분 파이썬 객체들을 확장할 수 있는 고유 능력을 가지고 있다. 예를 들면, Dask 배열에 쓰이는 넘파이 배열, Dask 데이터 프레임에 쓰이는 판다스 데이터프레임, Dask Bag에 사용되는 파이썬 리스트가 있다.
위 그림처럼 missing_count_pct는 판다스의 시리즈 객체인데, 기존의 Dask 데이터프레임과 결합하여 연산을 진행하고 있다는 점이다.
쉽게 말해서 판다스 라이브러리와 Dask 라이브러리를 섞어서 쓸 수 있다는 것이다.
저렴한 유지관리 비용

- 라이브러리 자체가 매우 가벼우면서, 설치, 제거, 유지관리가 매우 용이하다.
- 단순히 설치할 때도 pip 또는 conda 패키지 관리자로 Dask에 종속된 패키지들을 쉽고 빠르게 설치 할 수 있다.
Apache Spark와의 차이점?
- Dask를 오늘 처음 들었거나, 이미 관심을 가지고 계신분들은 보통 "아파치 스파크같은 녀석들하고 뭐가 다른건가?" 라는 의문이 드실겁니다. 명확한 차이점은 다음과 같습니다.
자바 전문지식 요구

- 스파크는 파이썬을 포함해 여러 언어를 지원하지만, 자바 라이브러리라는 측면에서 자바 전문지식이 없는 사용자에게 다소 어려울 수 있습니다.
자바 가상 머신(JVM)에 큰 의존성

- 스파크는 아파치 하둡용 맵리듀스 처리 엔진에 대한 인메모리 대안으로 자바 가상 머신(JVM)에 크게 의존합니다.
파이썬 라이브러리 늦은 업데이트

- 파이썬에서도 파이스파크(pyspark)라는 API가 있긴 하지만, 스파크에 제출된 모든 파이썬 코드는 방금 말씀드렸던 JVM을 반드시 통과하게 되고, 스파크의 기능이 업데이트가 되어도 파이스파크에 반영되기 까지는 보통 몇 번의 릴리즈 주기가 지나야 한다.
디버깅의 어려움

- PySpark를 경험해보신 분이라면 아시겠지만, 파이스파크 코드를 미세하게 조정하거나 디버깅이 매우 어렵습니다.
높은 러닝 커브

- 파이스파크를 처음 접하는 새로운 사용자는 기존의 판다스나 사이킷런 작업 경험과 지식을 바탕으로 하지 않고 스파크 방식으로 수행하는 방법을 새로 익혀야 한다.
결국 파이스파크 사용자는 스파크를 최대한 잘 활용하려면 코드를 파이썬이 아닌 스칼라나 자바로 전환해야 하긴 합니다.
글을 마치며
결론적으로 스파크 그 자체로는 상당히 훌륭하고 좋은 기술인 것은 분명하지만, Dask의 짧은 학습 곡선, 유연성, 그리고 친숙한 API 덕분에 Dask는 파이썬 기술 스택을 가진 데이터 사이언티스트들에게 더욱 매력적인 솔루션이라고 말할 수 있고, 당장이라도 빠르게 현업에 적용해볼 수 있는 기술이 아닐까 싶습니다.
계속해서 좋은 데이터 분석가가 되기 위한 커리어UP에 대해서 말씀드리고 있는데,
제가 생각하는 좋은 데이터 분석가란, 많은 기술에 익숙하고 잘한다라기 보다는,
우리 팀 상황에 맞게 어떤 문제 상황 및 개선 상황에 직면했을 때
그 상황에 가장 적합한 돌파구를 찾는 것이라고 생각이 듭니다.
그러기 위해서는 여러 기술에 대한 충분한 대안 및 이해도가 반드시 수반된다고 생각이 듭니다.
