
📌목차
1. VGGNet 개요
2. VGGNet 구조와 이해✔️ 기억할용어
3 x 3 고정
5개의 Convolution layer와 3개의 Fully-Connected Layer
📕 VGGNet 개요
VGGNet은 옥스포드 대학의 연구팀 VGG에 의해 개발된 모델
- 2014년 이미지넷 이미지 인식 대회에서 준우승을 한 모델
- 여기서 말하는 VGGNet은 16개 또는 19개의 층으로 구성된 모델을 의미한다
- 따라서 VGG16, VGG19로 불림
📖 이전 모델과의 차이점
이전 모델 : VGG16, VGG19 이전에 개발된 모델
- 공통된 특징
- 5개의 Convolution layer와 3개의 Fully-Connected Layer로 구성
- ResNet과 다르게 병렬적으로 구성되지 않음
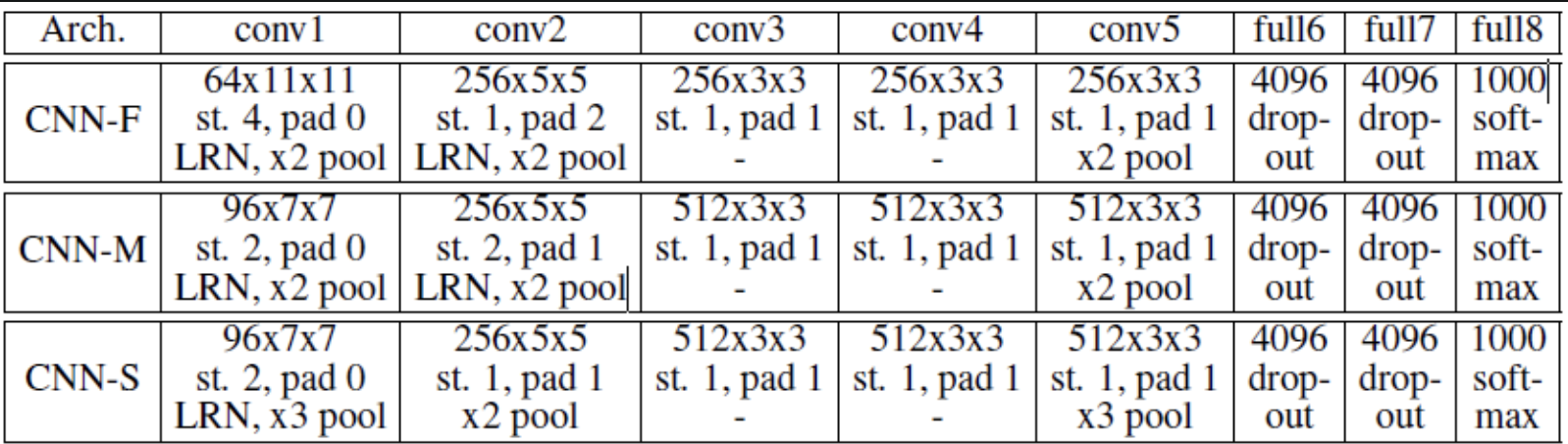
- VGG-F : 정확도보다
속도에 중점을 둔 모델
- 빠른이유 (1) 첫번째 레이어 : Filter 11,11 로 연산량이 적음- 빠른이유 (2) 첫번째 레이어 : stride 크기 4로 연산량이 적음
- VGG-M : 정확도와 속도 둘다 고려
- VGG-S : 속도보다
정확도에 중점을 둔 모델
- 느린이유 (1) 두번째 레이어 : stride 크기 1로 연산량 많음
📖 VGG-16 VGG-19 의 개발
논문명 : "Very deep convolutional networks for large-scale image recognition"
저자들이 논문의 개요에서 밝히고 있듯 이 연구의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지를 확인하고자 한 것이다. VGG 연구팀은 깊이의 영향만을 최대한 확인하고자 컨볼루션 필터커널의 사이즈는 가장 작은 3 x 3 으로 고정했다.
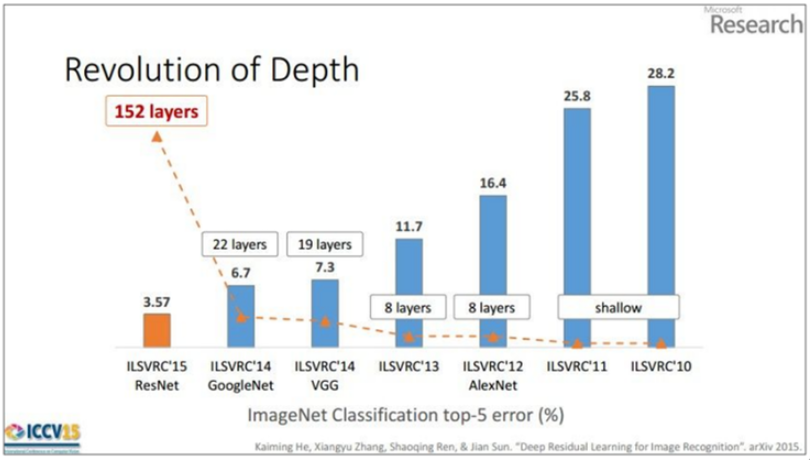
VGGNet 모델부터 시작해서 네트워크의 깊이가 깊어지기 시작하였다.
- 아래그림참고
- 2012년, 2013년 우승 모델들은 8개의 층으로 구성되었었으나, 2014년의 VGGNet(VGG19)는 19층으로 구성되었고, 또한 GoogLeNet은 22층으로 구성되었다. 그리고 2015년에 이르러서는 152개의 층으로 구성된 ResNet이 제안되었다.
- 네크워크가 깊어질 수록 성능이 좋아졌음을 위 그림을 통해 확인할 수 있다. VGGNet은 사용하기 쉬운 구조와 좋은 성능 덕분에 대회에서 우승을 거둔 조금 더 복잡한 형태의 GoogLeNet보다 더 인기를 얻었다.
📕 VGGNet 구조와 이해
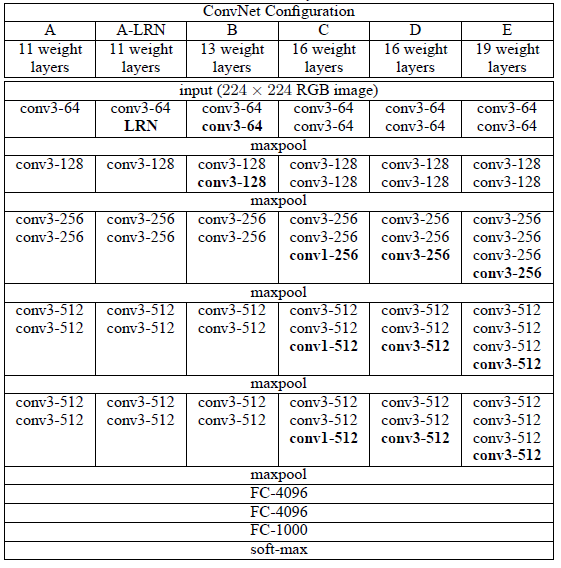
VGG 연구팀은 논문에서 총 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 성능을 비교하였다.
- 여러 구조를 만든 이유는 기본적으로 깊이의 따른 성능 변화를 비교하기 위하여
- 이중 D 구조가 VGG16이고 E 구조가 VGG19라고 보면 된다.
📖 LRN(Local Response Normalization) 미사용
VGG 연구팀은 AlexNet과 VGG-F, VGG-M, VGG-S에서 사용되던 Local Response Normalization(LRN)이 A 구조와 A-LRN 구조의 성능을 비교함으로 성능 향상에 별로 효과가 없다고 실험을 통해 확인했다. 그래서 더 깊은 B, C, D, E 구조에는 LRN을 적용하지 않는다고 논문에서 밝혔다.
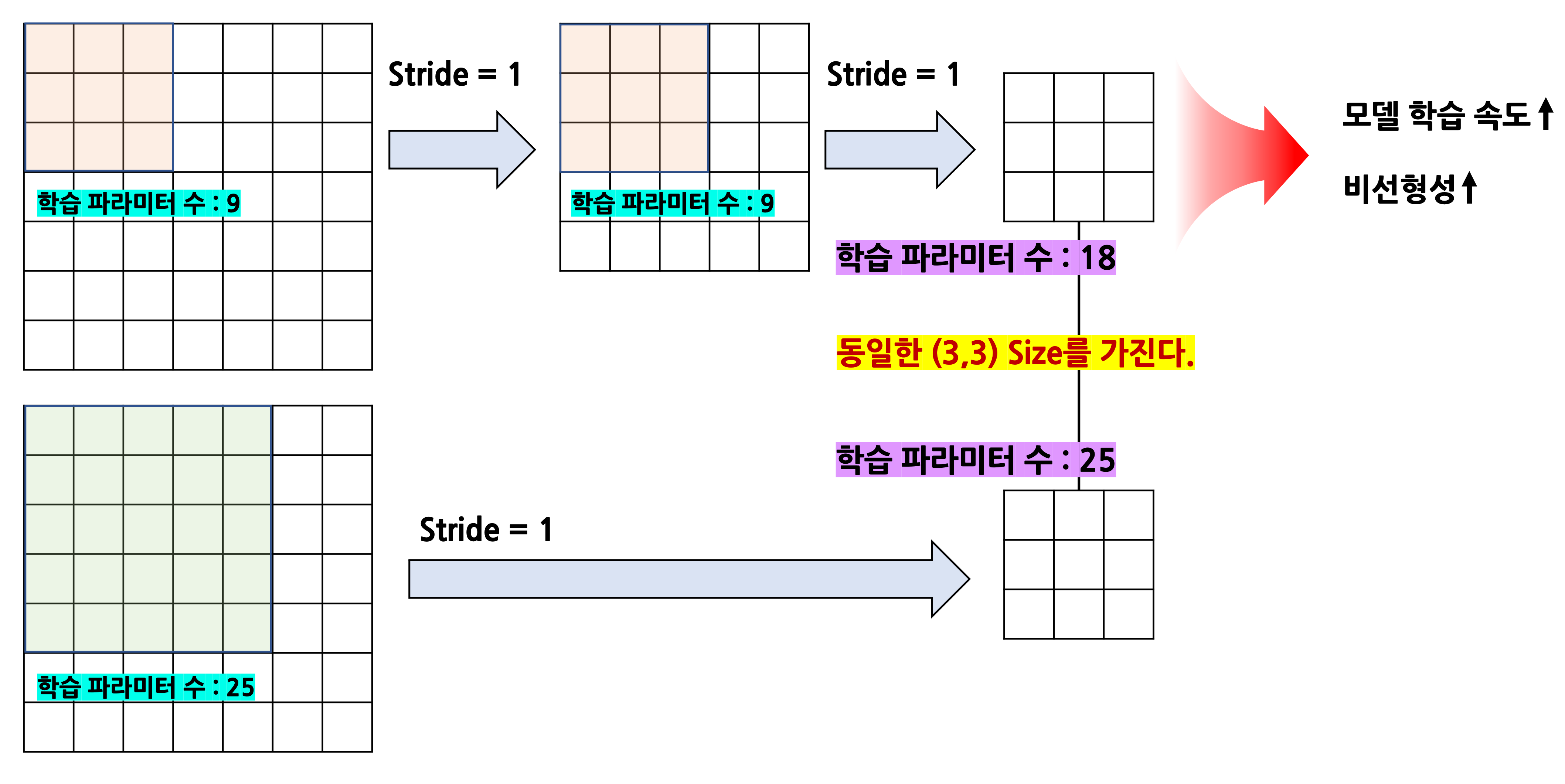
📖 컨볼루션의 이해 ( 5 x 5 한번 == 3 x 3 두번 ? )
VGGNet의 구조를 깊이 들여다보기에 짚고 넘어가야 할 것
- 5 x 5 (stride 1) 한번 == 3 x 3 (stride 1) 두번 ?
- 위 두개는 결과적으로 동일한 사이즈의 특성맵(Feature map)을 생성한다.
- (1) 5 x 5 의 경우 : (7-5+2x0)/1+1 == 3
- (2) 3 x 3 의 경우
- (7-3+2x0)/1+1 = 5
- (5-3+2x0)/1+1 = 3동일한 크기의 Feature map을 생성하지만 둘의 차이점은?
- 학습 파라미터 차이 (학습속도차이)
- 비선형성 (Feature의 유용성)
- 3 x 3 필터를 여러번사용하는게 학습파라미터도 줄이고 비선형성을 증대시킨다.
📖 VGG 구조 (D, 16 기준)
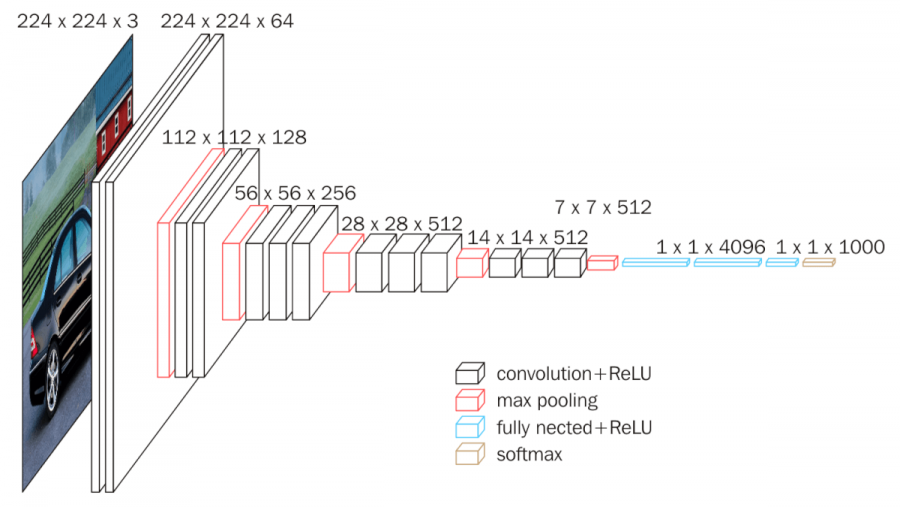
입력
- 224 x 224 x 3(RGB) 이미지
stride = 1 , padding = 1, Convolution 뒤 ReLU 사용 (마지막 16층 제외) 은 고정이므로 언급치않음
입력 레이어 (Convolution)
컨볼루션
- Kernel : (3,3,3) x 64
- output shape : (224,224,64)
- (224-3+2*1) / 1 + 1 = 224
두번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,64) x 64
- output shape : (224,224,64)
- (224-3+2*1) / 1 + 1 = 224
- max-pooling
- Size : (2, 2)
- stride : 2
- output shape : (112,112,64)
- (224-2) / 2 + 1 = 112
세번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,64) x 128
- output shape : (112,112,128)
- (112-3+2*1) / 1 + 1 = 112
네번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,128) x 128
- output shape : (112,112,128)
- (112-3+2*1) / 1 + 1 = 112
- max-pooling
- Size : (2, 2)
- stride : 2
- output shape : (56,56,128)
- (112-2) / 2 + 1 = 56
다섯번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,128) x 256
- output shape : (56,56,256)
- (56-3+2*1) / 1 + 1 = 56
여섯번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,256) x 256
- output shape : (56,56,256)
- (56-3+2*1) / 1 + 1 = 56
일곱번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,256) x 256
- output shape : (56,56,256)
- (56-3+2*1) / 1 + 1 = 56
- max-pooling
- Size : (2, 2)
- stride : 2
- output shape : (28,28,256)
- (56-2) / 2 + 1 = 28
여덟번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,256) x 512
- output shape : (28,28,512)
- (28-3+2*1) / 1 + 1 = 28
아홉번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,512) x 512
- output shape : (28,28,512)
- (28-3+2*1) / 1 + 1 = 28
열번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,512) x 512
- output shape : (28,28,512)
- (28-3+2*1) / 1 + 1 = 28
- max-pooling
- Size : (2, 2)
- stride : 2
- output shape : (14,14,512)
- (28-2) / 2 + 1 = 14
열한번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,512) x 512
- output shape : (14,14,512)
- (14-3+2*1) / 1 + 1 = 14
열두번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,512) x 512
- output shape : (14,14,512)
- (14-3+2*1) / 1 + 1 = 14
열세번째 레이어 (Convolution)
- 컨볼루션
- Kernel : (3,3,512) x 512
- output shape : (14,14,512)
- (14-3+2*1) / 1 + 1 = 14
- max-pooling
- Size : (2, 2)
- stride : 2
- output shape : (7,7,512)
- (14-2) / 2 + 1 = 7
열네번째 레이어 (Fully connected layer)
- Flatten
- 입력 : (7,7,512)
- 출력 : 25088
- Fully Connected
- 입력 : 25088
- 출력 : 4096
- ReLU
학습시 Dropout이 적용된다.
열다섯번째 레이어 (Fully connected layer)
- Fully Connected
- 입력 : 4096
- 출력 : 4096
- ReLU
학습시 Dropout이 적용된다.
열여섯번째 레이어 (Fully connected layer)
- Fully Connected
- 입력 : 4096
- 출력 : 1000
- softmax
학습시 Dropout이 적용된다.
Softmax 를 통과하여 1000개의 클래스로 분류한다.
📚 Reference
매우 도움되는 사이트 : https://bskyvision.com/421
