
📌목차
1. Squeezenet 개요✔️ 기억할용어
Fire Module
📕 Squeezenet 개요
논문명 : 2016 - SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
논문 이름 그대로 AlexNet보다 50배 적은 파라미터 수로 AlexNet과 동일한 정확도를 지닌 모델임
Squeezenet은 파라미터 수는 줄이면서 정확도는 어느정도 유지하기 위해 3가지 전략을 사용하였다.
📖 3가지 전략
1) 3x3 Filter 를 1x1 Filter로 대체
- 1x1 Convolution을 사용함으로써 특성맵의 갯수를 줄일 수 있음
- 특성맵의 갯수란 필터의 수를 의미
- 특성맵의 갯수가 줄어들면 학습파라미터 수가 줄어듦
- 따라서, 1x1 Convolution을 사용하면 연산량이 줄어든다.
- 자세한 내용은 GoogleNet 참고
2) 3x3 Filter로 입력되는 입력채널의 수를 감소
- GoogleNet에서 1x1 Convolution 과 3x3 Convolution을 동시에 진행하여 Concatenate 한것과 동일하다.
- 아래 그림처럼, 중간에서 1x1 Conv와 3x3 Conv을 동시에 진행하여 Concatenate 하게 된다. 이때, 3x3 Conv의 채널수는 초기입력 128이 아닌 64이므로 학습파라미터의 양이 상당히 작다.
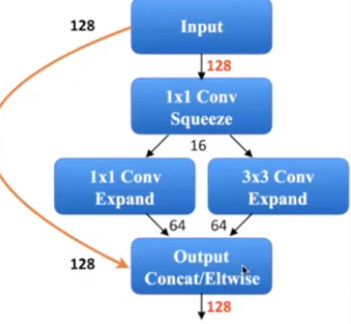
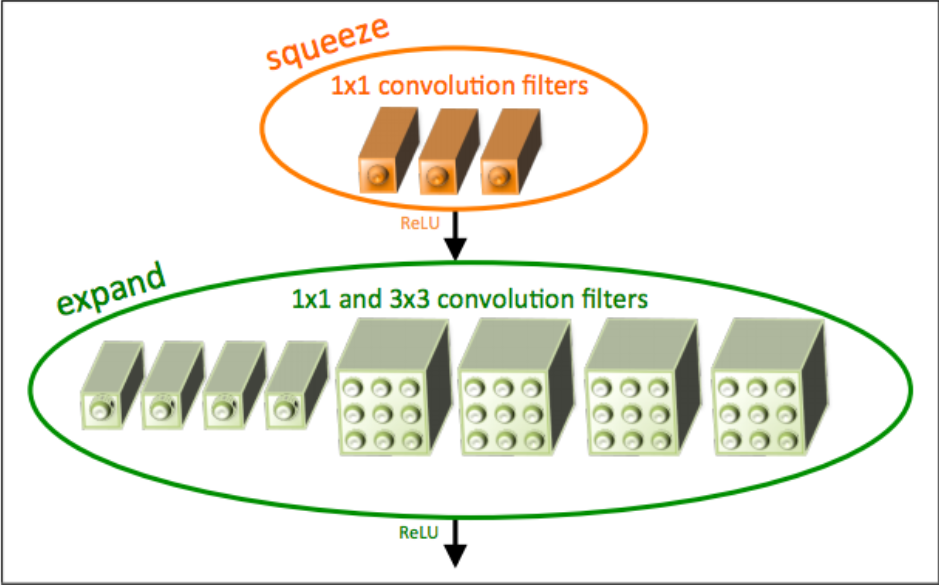
논문에서 1번과 2번과정을 합쳐서 Fire Module이라 명명하였고 구조는 아래와 같다.
3) Pooling Layer를 최대한 늦게 수행
- Pooling layer를 거치는 목적자체가 Feature map의 크기를 줄임으로써 연산속도를 향상시키기 위함이다. 하지만, Feature map의 크기를 줄이게되면 정확도가 떨어지게된다. 따라서 Squeezenet은 Pooling layer를 드물게 사용하였다.
📚 Reference

인공지능 4년차 개발자입니다.