
📜 PyTorch Tensor 이해하기
📕 파이토치(PyTorch)
- 페이스북이 초기 루아(Lua) 언어로 개발된 토치(Torch)를 파이썬 버전으로 개발하여 2017년도에 공개
- 초기에 토치(Torch)는 넘파이(NumPy) 라이브러리처럼 과학 연산을 위한 라이브러리로 공개
- 이후 GPU를 이용한 텐서 조작 및 동적 신경망 구축이 가능하도록 딥러닝 프레임워크로 발전시킴
- 파이썬답게 만들어졌고, 유연하면서도 가속화된 계산 속도를 제공
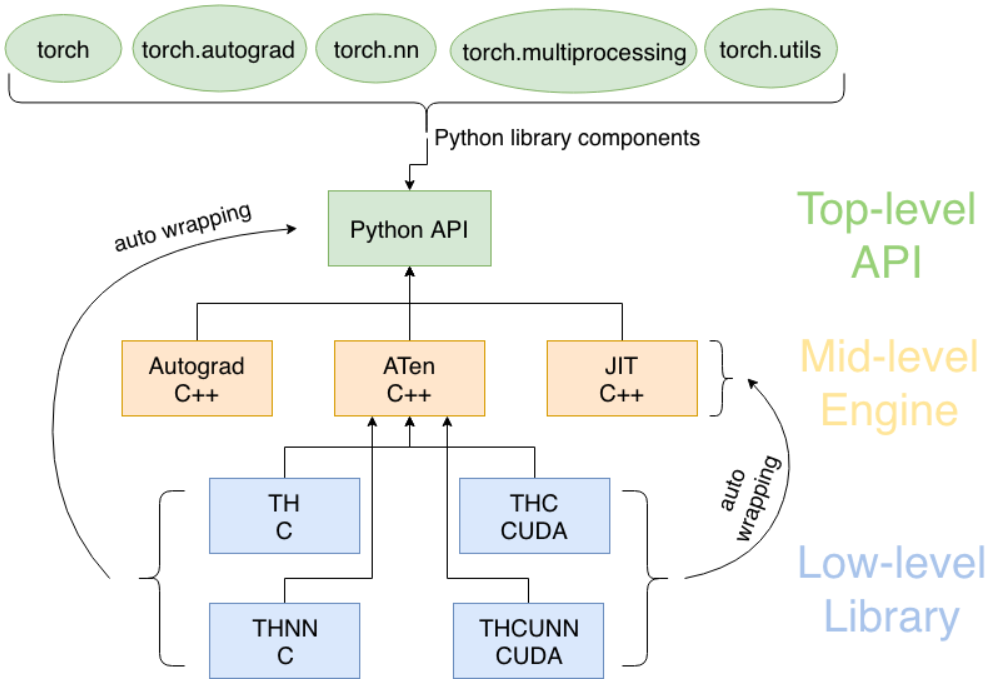
📖 파이토치의 구성요소
torch: 메인 네임스페이스, 텐서 등의 다양한 수학 함수가 포함torch.autograd: 자동 미분 기능을 제공하는 라이브러리torch.nn: 신경망 구축을 위한 데이터 구조나 레이어 등의 라이브러리torch.multiprocessing: 병럴처리 기능을 제공하는 라이브러리torch.optim: SGD(Stochastic Gradient Descent)를 중심으로 한 파라미터 최적화 알고리즘 제공torch.utils: 데이터 조작 등 유틸리티 기능 제공torch.onnx: ONNX(Open Neural Network Exchange), 서로 다른 프레임워크 간의 모델을 공유할 때 사용
📖 텐서
- 데이터 표현을 위한 기본 구조로 텐서(tensor)를 사용
- 텐서는 데이터를 담기위한 컨테이너(container)로서 일반적으로 수치형 데이터를 저장
- 넘파이(NumPy)의 ndarray와 유사
- GPU를 사용한 연산 가속 가능
📕 데이터정의
📖 데이터 정의
- torch 버전확인
import torch
torch.__version__
> '1.12.1+cu113' # 1.12.1 버전에 cuda는 11.3- 초기화 되지 않은 텐서 (말도안되는 이상값 들어있음)
torch.empty(a,b)
x = torch.empty(4,2) # (4,2) 크기의 텐서생성
print(x)
print(x.shape)
> tensor([[7.1685e-35, 0.0000e+00],
[5.0447e-44, 0.0000e+00],
[ nan, 0.0000e+00],
[1.3788e-14, 3.6423e-06]])
> torch.Size([4, 2])- 무작위로 초기화된 텐서 (이상값 X)
torch.rand(a,b)
x = torch.rand(4,2) # (4,2) 크기의 0~1 사이 랜덤값 텐서생성
print(x)
> tensor([[0.9879, 0.7454],
[0.0494, 0.3015],
[0.6462, 0.3983],
[0.8883, 0.9433]])- 사용자가 입력한 텐서
torch.tensor(리스트)
x = torch.tensor([1.6,2,4,5])
print(x)
> tensor([1.6000, 2.0000, 4.0000, 5.0000])- 0 / 1으로 채워진 텐서
torch.ones / torch.zeros
x = torch.zeros(4,2,dtype=torch.long)
y = torch.ones(3,2,dtype=torch.float)
print(x)
print(x.type())
print(y)
print(y.type())
> tensor([[0, 0],
[0, 0],
[0, 0],
[0, 0]])
> torch.LongTensor
> tensor([[1., 1.],
[1., 1.],
[1., 1.]])
> torch.FloatTensor
- '같은크기'를 가지는 무작위 텐서 생성
torch.randn_like
# x는 (4,2) shape를 가진다 가정한다.
x = torch.randn_like(x,dtype=torch.float)
print(x)
print(x.type())
print(x.size()) # 텐서의 shape을 알려준다.
> tensor([[-0.6504, 2.9375],
[-0.1826, -0.0519],
[ 0.3183, 1.0060],
[ 0.6136, 0.7064]])
> torch.FloatTensor
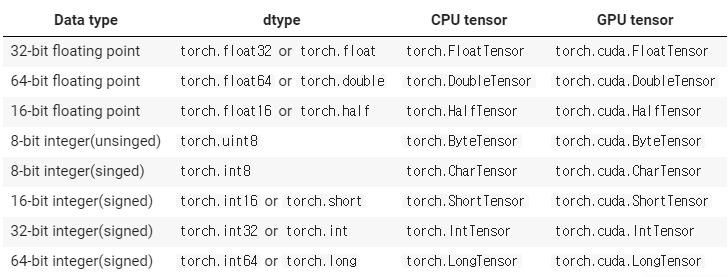
> torch.Size([4, 2])데이터타입 종류는 다음과같으며 서로 캐스팅 가능
✍ 중간정리
데이터 생성
- 초기화되지않음 : torch.empty()
- 초기화됨 : torch.rand()
- 사용자입력 : torch.tensor()
- 0으로 채움 : torch.zeros()
- 1로 채움 : torch.ones()
- 같은크기를 가지는 무작위텐서 : torch.randn_like(대상 텐서)
함수
- x.type() : 텐서의 타입 알려줌 (큰 종류만, torch.FloatTensor)
- x.dtype : 텐서의 타입 알려줌 (자세히, torch.float32)
- x.shape : 텐서의 shape 알려줌
- x.size() : 텐서의 shape 알려줌
📕 GPU와 CPU
📖 .device
데이터.device 로 데이터가 할당된 공간확인가능
# 데이터생성
x = torch.randn(3,2)
print(x)
print(x.device)
# 데이터생성 결과
> tensor([[ 1.6014, -0.3771],
[-0.6839, -0.9717],
[ 0.1215, -0.9383]])
> device(type='cpu') 📖 이동
.to(device,타입)를 사용하여 데이터를 CPU, GPU 어디든지 이동가능
# device 할당 (cuda 또는 cpu로)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# gpu로 변환
x = x.to(device, torch.double)
print(x)
print(x.device)
# gpu로 옮긴 결과 : device='cuda:0' 이 생김.
> tensor([[ 1.6014, -0.3771],
[-0.6839, -0.9717],
[ 0.1215, -0.9383]], device='cuda:0')
> cuda:0📕 텐서 연산
📖 기본연산
torch는 수학의 기본적인 연산 전부 내포하고 있다,
기본연산
torch.abs(a) torch.min(a) torch.max(a) torch.mean(a) torch.std(a) # 표준편차 torch.prod(a) # 곱 torch.ceil(a) # 올림 torch.floor(a) # 내림
📖 행렬연산
torch.matmul(x,y)
- 행렬곱시 matmul 사용
- 단순 * 연산은 element wise 곱이다.
x = torch.tensor([[1,2,3],[4,5,6]],dtype=float)
y = torch.randn_like(x,dtype=float)
y_t = y.T
print(x.shape)
print(y.shape)
print(y_t.shape)
> torch.Size([2, 3])
> torch.Size([2, 3])
> torch.Size([3, 2])
# element-wise product
print(x*y)
> tensor([[ 1.4303, -0.8309, -0.1673],
[ -3.0072, -10.9429, 1.8235]], dtype=torch.float64)
# 행렬연산
print(torch.matmul(x,y_t))
> tensor([[ 0.4321, -4.2172],
[ 3.3092, -12.1266]], dtype=torch.float64)📖 그 외 알아 둘 연산
x.type(torch.float)
타입변환하는 함수
타입을 확인하는데도 쓰이지만, 타입변환에도 쓰인다.
x = torch.tensor(1)
print(x.dtype)
> torch.int64
x = x.type(torch.float)
print(x.dtype)
> torch.float32torch.unique(텐서)
집합을 구하는 역할 수행
x = torch.tensor([1,2,3,4,1,2,3,1])
x_set = torch.unique(x)
print(x)
print(x_set)
> tensor([1, 2, 3, 4, 1, 2, 3, 1])
> tensor([1, 2, 3, 4])torch.clamp(텐서,범위1,범위2)
범위값안에 있도록함, 벗어날경우 해당값으로 지정함
x = torch.tensor([1,2,3,4,1,2,3,1])
x_clamp = torch.clamp(x,1.5,2.5)
print(x)
print(x_clamp)
> tensor([1, 2, 3, 4, 1, 2, 3, 1])
> tensor([1.5000, 2.0000, 2.5000, 2.5000, 1.5000, 2.0000, 2.5000, 1.5000])데이터.max(dim=0)
- 데이터.max(dim=0) : 열기준 argmax
- 데이터.max(dim=1) : 행기준 argmax
- 데이터.min(dim=0) : 열기준 argmin
- 데이터.min(dim=1) : 행기준 argmin
x = torch.rand(3,4)
arg = x.max(dim=0)
print(x)
print(arg)
> tensor([[0.7002, 0.5021, 0.8545, 0.2372],
[0.0192, 0.5245, 0.7978, 0.5102],
[0.1585, 0.4971, 0.7144, 0.5225]])
> torch.return_types.max(
> values=tensor([0.7002, 0.5245, 0.8545, 0.5225]),
> indices=tensor([0, 1, 0, 2]))데이터.argmax(축 번호)
- 데이터.argmax(0) : axis=0 기준으로 argmax 수행
- 데이터.argmax(1) : axis=1 기준으로 argmax 수행
x = torch.rand(4,2)
print(x)
print(x.argmax(0))
print(x.argmax(1))
> tensor([[0.2154, 0.5701],
[0.2725, 0.8342],
[0.3470, 0.2540],
[0.2194, 0.9083]])
> tensor([2, 3])
> tensor([1, 1, 0, 1])📚 내용 출처 (모든내용)
현재 보고 계씬 내용은 이수안 교수님이 강의하신 내용과 pytorch document 를 참고하여 적어놓은것입니다.

인공지능 4년차 개발자입니다.