
📜 Speech Processing 다루기
가끔식 들어와작성할예정..
📕 MFCC(Mel-Frequency Cepstral Coefficient)
매우 설명잘해주신 블로그 참고하였습니다.
MFCC 란?
'음성데이터'를 '특징벡터' (Feature) 화 해주는 알고리즘
📖 알아야 할 것
- 오디오 신호
- 시간(가로축)에 따른 음압(세로축)의 표현 = time domain
- Spectrum
- 주파수(가로축)에 따른 음압(세로축)의 표현 = Frequency domain
- Spectrum을 사용하면 각 주파수의 대역별 세기를 알 수 있으니
신호에서 어떤 주파수가 강하고 약한지를 알 수 있게 됨
- FFT(Fast Fourier Trasnform)
- 신호를 주파수 성분으로 변환하는 알고리즘
- 기존의 이산 푸리에 변환(DFT)을 보다 빠르게 수행
- Mel Spectrum
- 뭔말인지 모르겠음.
- Cepstral 분석
- 주파수에 대한 정보를 가진 Spectrum에서 소리의 고유한 특징을 추출할 때 사용하는 방법
📖 MFCC 추출과정
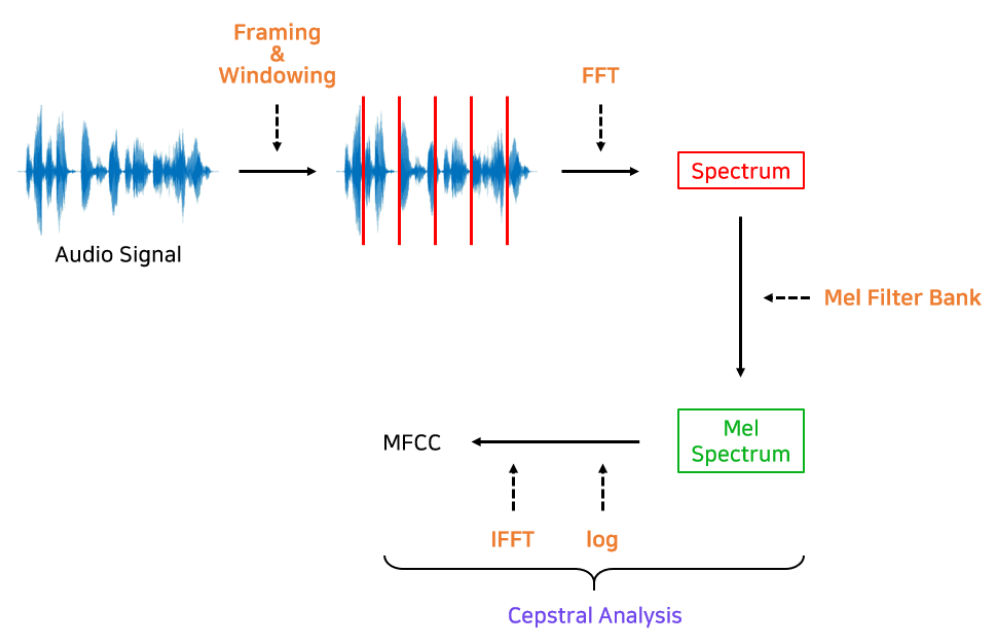
- 오디오 신호를 프레임별(보통 20ms - 40ms)로 나눔
- FFT를 적용해 Spectrum을 구함
- Spectrum에 Mel Filter Bank를 적용해 Mel Spectrum을 구함
- Mel Spectrum에 Cepstral 분석을 적용해 MFCC를 구함
📕 librosa
음성파일을 전처리하기위한 파이썬 라이브러리
librosa document
📖 librosa.load
y, sr = librosa.load('파일명.wav',sr=값)
wav 데이터 로드시 사용
- y : 음성데이터의 time series
- sr (sampling rate) : 샘플링 속도
- 연속적 신호에서 단위시간(주로 초)당 샘플링 횟수를 의미
- 이산적인 신호를 만들기 위함
- default 값 : 22050Hz
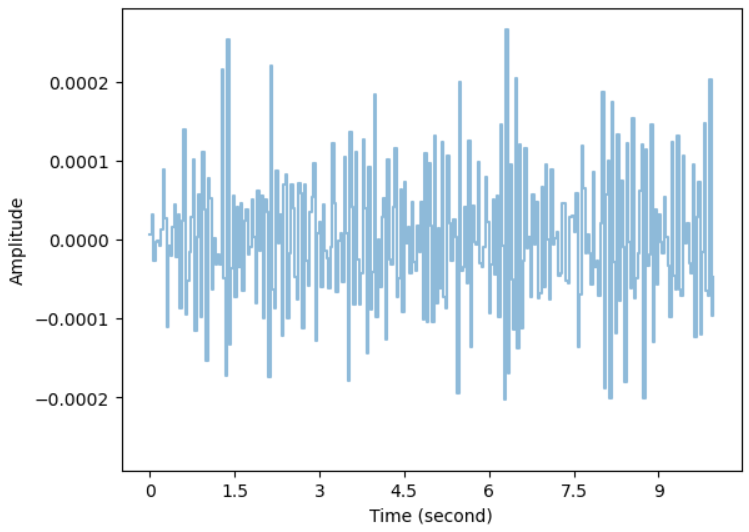
📖 librosa.display.waveshow
librosa.display.waveshow(y, sr, alpha=값)
wav 데이터 플롯시 사용
plt.figure()
librosa.display.waveshow(y, sr, alpha=0.5)
plt.xlabel("Time (second)")
plt.ylabel("Amplitude")sr=30 사용했을경우 플로팅 결과
📖 librosa.feature.mfcc
librosa.feature.mfcc(y=값, sr=값, n_mfcc=값)
MFCC 구할때 사용
- n_mfcc는 return 될 feature 수 지정
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=CFG['N_MFCC'])
mfcc.shape
> (128, 1)
인공지능 4년차 개발자입니다.