📒 배울내용
- Learning Decision Lists - 레이블링(O)
- Learning Unordered Rule Sets - 레이블링(O)
- Rule Learning for Subgroup Discovery - 레이블링(ㅁ)
- Association Rule Mining - 레이블링(X)
- 1번과 2번은 Predictive Models
- Predictive Models :미래에 무슨일이 일어날것인지 알고자 하는 모델- 과거 데이터를 분석해서 미래에 어떤일이 일어날지 예측하고자 함
- 3번과 4번은 Descriptive Models
- Descriptive Models :과거에 일어났던 일들에 대해 분석하는 모델- 과거에 무슨일이 일어났는지 분석
📕 1. Decision Lists
Decision Lists는 Seperate-and-Conquer 를 따른다.
결정트리는 Divide-and-Conquer를 따른다 했던것과 비교되는데,
의미를 해석하자면, 데이터를 걷어내면서 분류하기 때문이다.
📖 예시로 이해하기
-
아래에는 Positive로 Labeling 되어있는 행과 Negative로 Labeling 되어있는 행이 존재함
-
해당 테이블에서 각 컬럼별 레코드별 취할 수 있는 값 각각을 Literal 이라 한다.
- 예를 들어 "Lenght = 3", "Beak = yes" 등을 Literal 이라고 함 -
과정 이해하기
- 1. Literal을 전부 나열함
- 2. 하나의 클래스(POS,NEG)값만을 가지는 Literal을 채택
- 3. 해당 Literal이 커버하는 데이터는 전부 걷어냄
- 4. 1~3 반복

-
해당 과정을 종합하면 아래와 같음

📖 알고리즘으로 이해하기
알고리즘으로 살펴보면 아래와같음
- 입력 : 레이블링된 학습 데이터
- 출력 : Rule list
- Rule list 를 공집합으로 초기 선언 (아직 정해진 룰이 없음을 의미)
- 데이터셋 D에 데이터가 없어질때 까지 반복
- Rule을 하나 정하여 Rule list에 넣음
- 해당 Rule에 의해 커버되는 데이터는 제거

- 해당 Rule에 의해 커버되는 데이터는 제거
- 위 알고리즘에서 LearnRule 함수는 아래와 같음

📕 Unordered Rule Sets
위 Decision Lists와 비슷하지만 다르다.
애초에 이름도 List가 아닌 Set을 사용한 이유는 순서가 없기 때문이다.
Decision Lists 같은 경우에 아래와 같이 조건문으로 연결되어있는형태이다.
- 즉 순서가 있으며, 앞에 조건이 만족하지 않을경우 다음조건을 고려한다는 전제가 있다.
if Gills==yes:
Class = minus
elif Teeth==many:
Class = Plus
elif Length==4:
Class = minus
else:
Class = Plus 하지만 Unordered Rule Sets은 순서가 없으며
클래스별로 하나씩 집중해서 순차적으로 진행한다.
이 말의 의미는 Class = (Positive, Negative)라면
1. Positive에 대해 Rule 순차적으로 생성
2. Negative에 대해 Rule 순차적으로 생성
함을 의미
if Length == 3:
Class = Plus
if (Gills==no) & (Length==5):
Class = Plus
if (Gills==no) & (Teeth==many):
CLass = Plus
if (GIlls==yes):
Class = Minus
if (Length==4) & (Teeth==few):
CLass = minus 주의할점은 Unordered Rule Sets는 Homegeneity를 최대화하는것이 아닌
학습하고자 하는 클래스의 Empirical Probability (Precision)을 최대화 한다.📖 예시로 이해하기

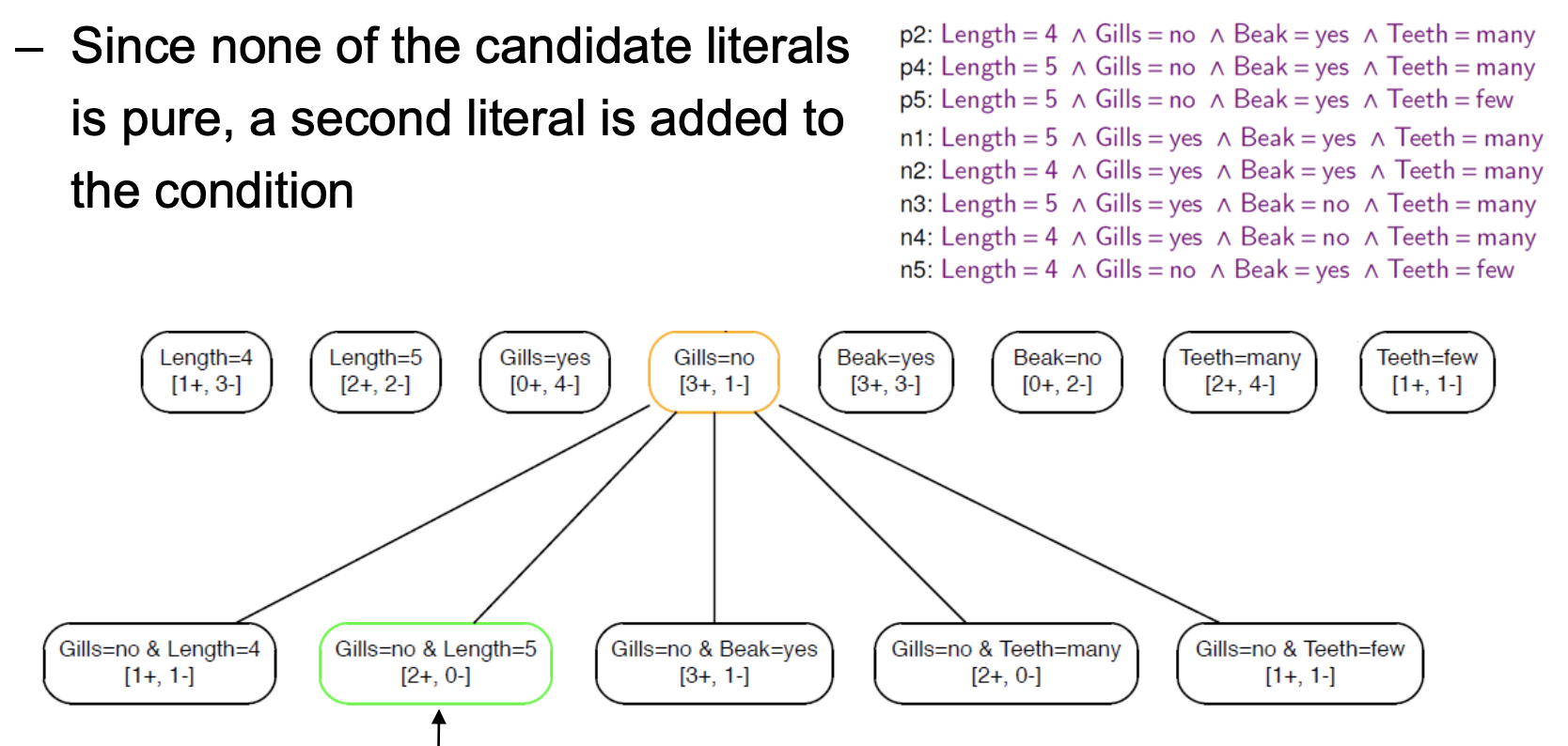
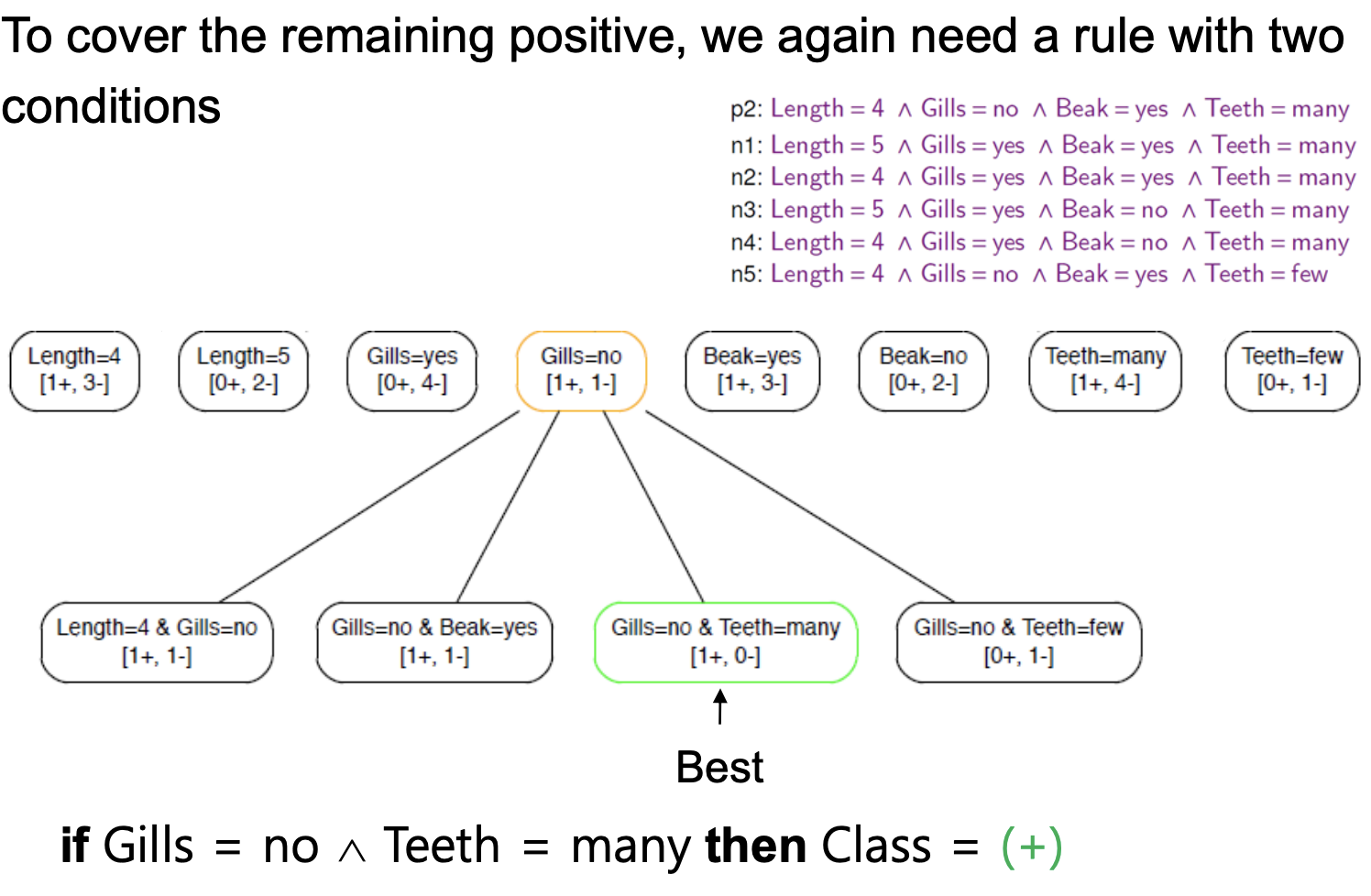
📖 알고리즘으로 이해하기


📖 Probability Smoothing
아래그림에서 처음에 'Length=3'인 Literal을 택한거보다
'Gills=no' Literal에서 한번더 Literal을 추가한형태가 더많은 Positive를 걸러낼 수 있음.
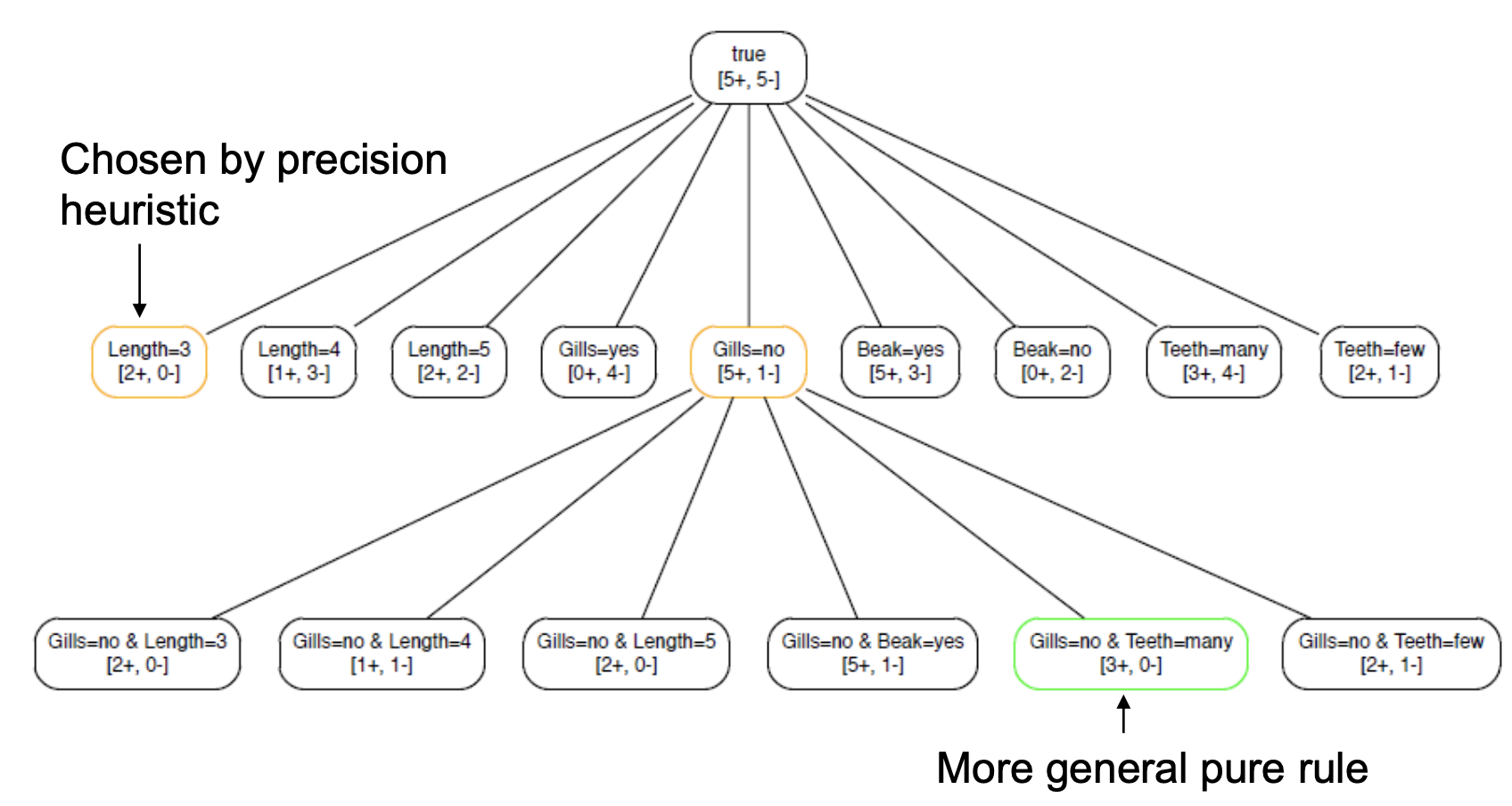
위처럼 기존의 Greedy 방식 같은 문제점을 해결하기 위해 Beam Search와 같은 방식을 사용
- 이때 사용되는게 Laplace Correction이다.

문제점
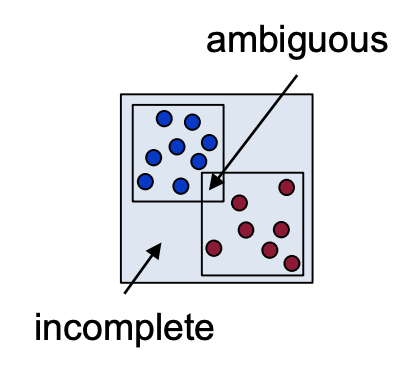
- 두 클래스의 Rule 사이 겹치는 부분에 테스트 데이터가 들어올경우 클래스를 지정할 수 가 없음.
- 두 클래스의 Rule에 속하지 않는 영역의 속하는 데이터의 경우에도 클래스를 지정할 수가 없음
- 위 1,2 번 모두 더 많은 학습데이터의 클래스로 간주하는 방법을 사용