강의 소개
모델 최적화 강의에 오신걸 환영합니다!
이번 시간에는 첫 시간인 만큼 딥러닝 모델 최적화에 대한 전반적인 소개와 강의 내용에 대한 전반적인 소개를 합니다.
어떻게 하면 같은 성능을 유지하면서 더 작고 더 빠른 모델을 만들 수 있을까요?
어떤 기법을 사용해야 딥러닝 모델 최적화를 잘 할 수 있는지 함께 알아봅시다.
-
경량화의 목적
- On device AI
- Smart Phone, Watch, other IoT Devices 에 적용
- 소형 기기에 적용되기 위해 다양한 제약사항이 존재
- Power usage(Battery)
- RAM Memory
- Storage
- Computing Power
- AI on clode(or server)
- 베터리, 저장 공간, 연산능력 등의 제약사항을 둘어드나 latency와 throughput 제약 존재
- latency : 요청에 대해 소요되는 시간, throughtput : 단위 시간당 처리 요청 수
- 같은 자원으로 더 적은 latency와 더 큰 throughput을 구현하는 것이 목표
- 베터리, 저장 공간, 연산능력 등의 제약사항을 둘어드나 latency와 throughput 제약 존재
- Computation as a key component of AI Progress
- AI 모델 학습에 사용되는 데이터가 커짐에 따라 연산량이 대폭 증가
- 연산량 측정 방법
- FLOPs(Counting operations)
- 제대로 논문에 공개되지 않으면 GPU times을 측정
- GPU times
- FLOPs(Counting operations)
- On device AI
-
경량화
- 모델의 연구와 별개로 산업에 적용되기 위해 거쳐야하는 과정
- 요구 조건(하드웨어 종류, latency 제한, 요구 troughput, 성능)들 간의 trade-off를 고려하여 모델 경량화/최적화 수행
-
경량화,최적화의 종류
- 네트워크 구조 관점
- 효율적 모델 구조 디자인(+AutoML;Neural Architecture Search(NAS))
- 모델을 찾는 네트워크를 정의하고, 해당 네트워크가 architecture를 제시하고, 그 모델로 학습을 시킨 다음, 해당 모델의 accuracy로 네트워크를 재학습
- 이 과정을 반복적으로 수행하여 최적화된 architecture를 찾음
- Pruning - 중요도가 낮은 파라미터를 줄여 모델 사이즈를 줄이는 것
- 좋은 중요도를 정의
- L2 norm이나 loss gradient 등이 크면 좋은 중요도라 판단
- structured/unstructured pruning으로 나뉨
- 좋은 중요도를 정의
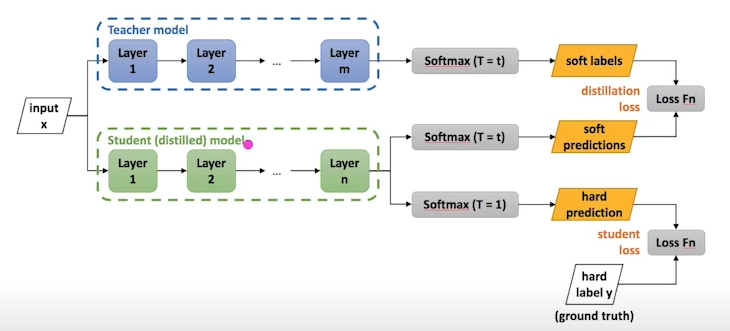
- Distillation - 학습된 큰 네트워크를 작은 네트워크 학습 보조로 사용하는 방법
- input x가 들어왔을 때, Student model은 원래 학습하는 대로 진행하여 loss를 계산하고, 같은 input에 대해 Teacher model이 구한 결과를 kl divergence를 활용하여 추가로 loss를 계산한 다음, 두 loss를 합하여 모델 weight를 업데이트
- Teacher의 지식을 student에 전달하는 방식
- Matrix/Tensor Decomposition - 하나의 Tensor를 작은 Tensor들의 operation들의 조합(합,곱)으로 표현하는 것
- 효율적 모델 구조 디자인(+AutoML;Neural Architecture Search(NAS))
- 하드웨어 관점
-
Quantization - floating point 32를 foingting point 16이나 int 16과 같이 더 작은 크기의 데이터 타입으로 변환하여 연산을 수행하는 방법
- 단 이 경우, float32로 계산한 결과와 조금 차이가 발생하는, Quantization Error가 발생하지만, 해당 error에 대해서도 robust하게 동작을 하는 것이 경험적으로 밝혀져 있어서 보편적으로 적용되는 방법론
-
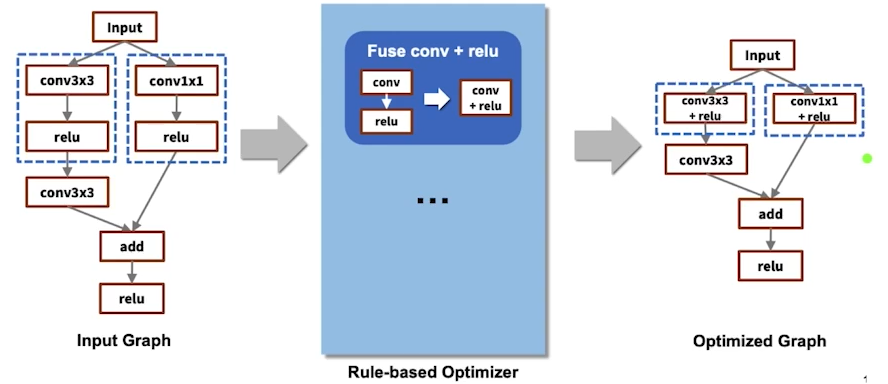
Compiling - 학습이 완료된 Network를 deploy하려는 Target hardward에서 inference가 가능하도록 compile 하는 방법 (일반적으로 최적화 동반)
- 사실상 속도에 가장 큰 영향을 미치는 기법
- 제조사마다 compile library를 제공
- Compile 과정에서, layer fusion(graph optimization) 등의 최적화가 수행됨
- 아래 예로 들면, Conv lyaer와 relu가 하나로 합쳐짐
- 단, Framework와 harware backends 사이에 수많은 조합이 있음
- 동일 회사의 hw임에도 Layer fusion의 조합에 따라 성능 차이가 발생
- 따라서, AutoML로 graph의 좋은 fusion을 찾아내기도 함.
-
- 네트워크 구조 관점

DL, NLP Engineer to be....