학습 설명
PyTorch에서 Multi GPU를 사용하기 위해 딥러닝 모델을 병렬화 하는 Model Parallel의 개념과 데이터 로딩을 병렬화하는 Data Parallel의 개념을 학습합니다. 이를 통해 다중 GPU 환경에서 딥러닝을 학습할 때에 효율적으로 하드웨어를 사용할 수 있도록 하고, 더 나아가 딥러닝 학습 시에 GPU가 동작하는 프로세스에 대한 개념을 익힙니다.
이전에는 모델 구조를 단순화하고 GPU를 적게 소모하는 것을 고려했다면, 현재는 많은 GPU와 데이터를 활용하여 성능이 좋은 모델을 만드는 것에 촛점이 맞춰져 있다. 따라서 Multi-GPU를 어떻게 사용해야 하는가에 대한 고민이 필요하다.
고민에 앞서 개념 정리부터 시작해보도록 하자!
개념 설명
- Single vs Multi
- GPU vs Node : Node를 system이라고 부르며 이 경우 1대의 컴퓨터로 보면 된다. 즉, 1대의 node를 쓴다고 하면, 1대의 컴퓨터 안에 1대의 GPU를 쓴다고 이해하면 된다..
- Single Node Single GPU : 1대의 컴퓨터에 1개의 GPU
- Single Node Multi GPU : 1개의 컴퓨터에 여러 개의 GPU
- Multi Node Multi GPU : 서버실에 달려있는 GPU를 연상해보면 됨

보통 GPU를 사용할 경우 Sing Node Multi GPU 형태인데, GPU를 어떻게 하면 조금 더 잘 사용할지에 대한 다양한 고민이 필요한데, 아래 NVDIA처럼 이러한 처리를 지원하는 도구들을 제공해주고 있다.
Model Parallel
- 다중 GPU에 학습을 분산하는 두 가지 방법
- 모델 나누기 / 데이터 나누기
- 모델을 나누는 것은 생각보다 예전부터 사용(alexnet)
- 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
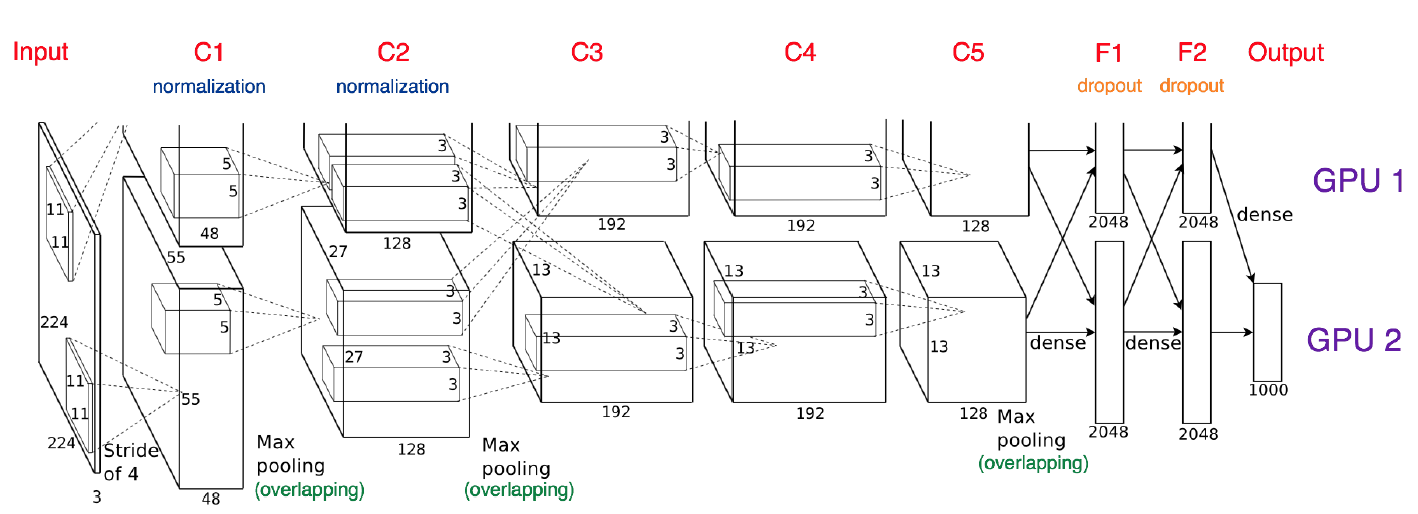
Model parallel(e.g. AlexNet)
C2-C3을 보면, 두 GPU간 데이터가 교차되는 부분이 있으며, 이 부분이 .to()를 통해 병렬적 처리를 지원하기 위함
모델 병렬화는 다음과 같이 있는데, 첫번째 케이스는 하나의 GPU가 작업이 끝나야 다른 GPU가 작업을 하므로, 병렬적으로 처리하는 의미가 없다. 이는 파이프라인이 안만들어졌기에 병렬화 효과가 없다.
즉, 아래와 케이스와 같이, 파이프라인을 통해 두 GPU가 각기 다른 처리를 동시에 진행할 수 있도록 해야 한다.
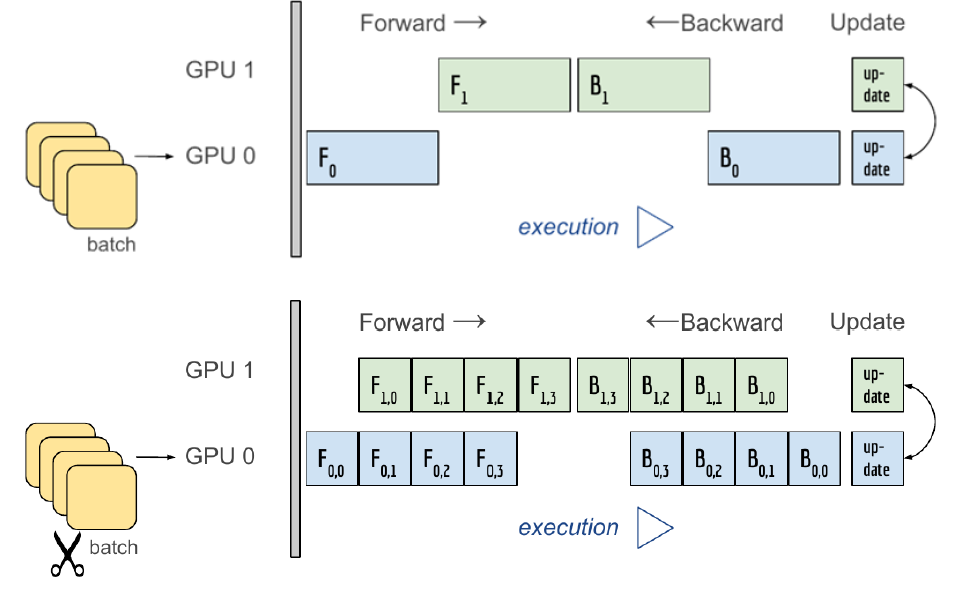
coda:0에서 처리한 것을 cuda:1으로 보내서 또 다른 처리를 하고, 마지막에 fc layer를 cude:1에서 처리한 것을 볼 수 있다. 단, 이렇게만 구현하면 병렬화가 제대로 안되어 병렬현상이 발생하므로, 앞에서와 같은 파이프라인 구축이 필요하다.

Data Parallel
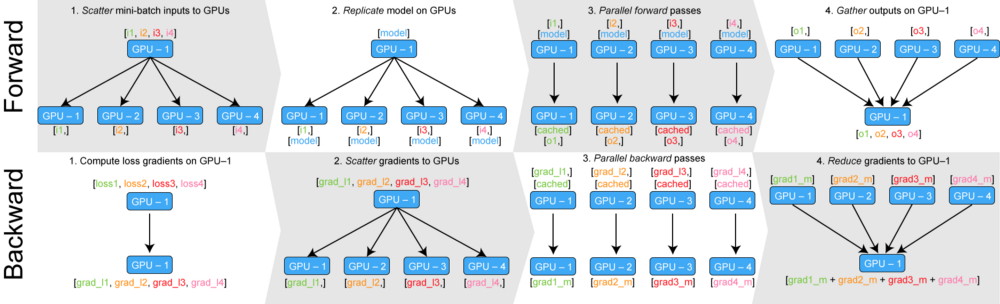
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- mini batch 수식과 유사한데 한번에 여러 GPU에서 수행
- 즉, 각 GPU로 보내진 mini batch들을 한번에 처리하고 최종엔 모아서 평균을 취함
- mini-batch inputs을 여러 GPU에 나눔
- 모델을 각 GPU에 복사
- 각 GPU 순전파 과정 진행
- 연산 결과를 한 GPU에 모음 (한 곳에 모아줄 경우 각각의 loss를 한 번에 구할 수 있음)
- 한 gpu에서 구한 4개의 로스를 기본으로 gradient 계산
- 이후 각 loss에 gradient를 각 GPU에 보냄
- backward
- 최종적으로 출력된 gardient를 첫 GPU에 모은 다음 평균을 내서 gradient를 update
- PyTorch에서는 아래 두 가지 방식을 제공
- DataParallel, DistributedDataParallel
- DataParallel - 단순히 데이터를 분배한 후 평균을 취함
- GPU 사용 불균형 문제 발생, Batch 사이즈 감소 (한 GPU가 병목), GIL(Global interpreter Lock)
- 각 GPU 성능이 동일할 떄 한 GPU가 많은 업무를 할당받으면, 같이 batch size를 지정해도 한 GPU만 처리를 늦어짐(병목현상 발생) 이 경우 처리가 늦어지는 GPU 때문에 전체 GPU의 batch size를 줄여야 함.
- DistributedDataParallel - 각 CPU마다 process 생성하여 개별 GPU에 할당
- 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄
- DataParallel과 달리, loss를 구하기 위해 각 gpu의 output을 모으는게 아니라, 각 GPU에서 forward, backward 둘 다 수행 후 최종 gradient만 하나로 모아서 평균을 취함
- 각 GPU에 CPU도 할당하여 각각이 Coordinator 역할을 수행하면 됨
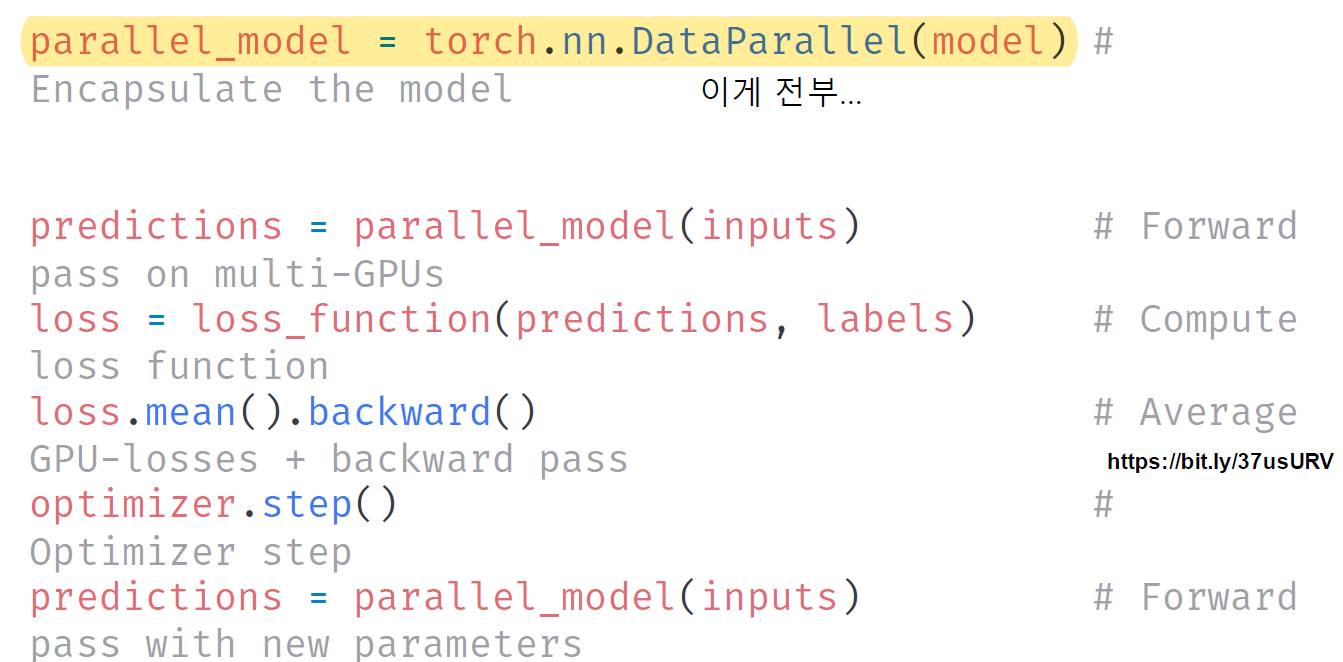
길어보이지만, Data Parallel은 강조한 한줄이 끝이다...
반면, Distributed Data Parallell은 다음과 같이 몇가지 과정이 피룡하다.
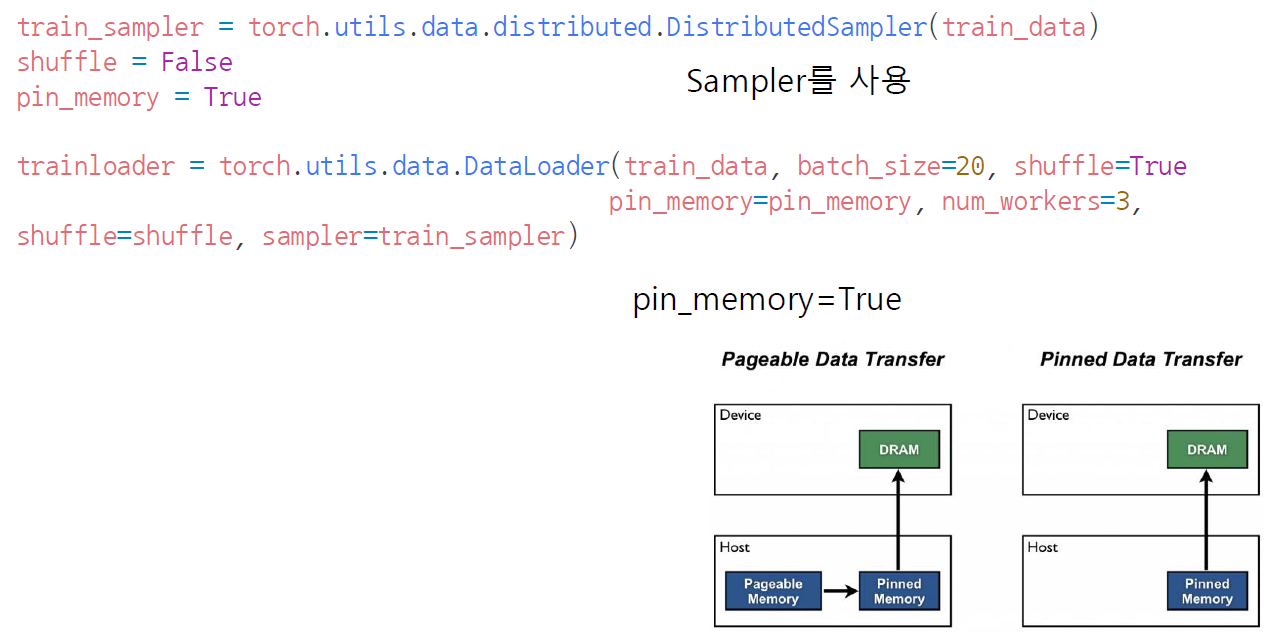
1. sampler 사용, shuffle=False, pin_memory = True(dram, 즉 메모리에 값을 바로바로 올릴 수 있도록 절차를 간소화하게 데이터를 저장하는 방식)
2. Dataloader에 이 조건들을 적용, num_workers는 GPU x 4개 정도가 일반적임