[BoostCamp AI Tech / Day 15] (1강) Competition with AI Stages! // (2강) image classification
[boostcampAI P stage] week 4-5
P stage, image classification competition이 시작되었다. 따라서 강의 역시 대회를 위해 반드시 알아야 할 내용에 대해서 다루며, 오늘 강의는 (1) 전체적인 대회의 진행 순서와 (2) 데이터 EDA이다. 오늘은 강의을 정리하여 요약하려고 한다.
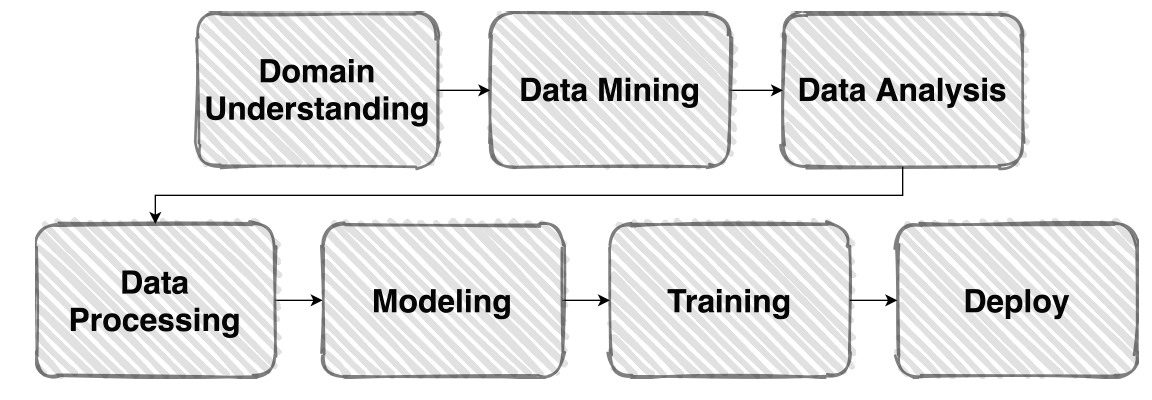
대회가 시작되면 가장 중요한 것은 무엇일까? 데이터 전처리, 모델링, 성능개선 등등 다 필수적이지만, 초기에 가장 중요한 것은 대회에 대한 Overview를 파악하는 것이다. 같은 classification, detection, segmentation 등 어떻게 보면 지금까지 했던 것과 비슷하지만, 실제로 overview를 보면 다른 문제임을 파악할 수 있다. 그 예로, classification 문제지만 동음이의어에 대한 처리를 통해 classification을 하는 문제도 있을 것이고, 단순 이진 부류 문제도 있을 것이다.
따라서, overview에서는 문제 정의를 해야 하며, 이 과정에서 필요한 input, output 개수, 솔루션 적용 방안도 고려해야 한다.
그 다음 과정으론 EDA인데, 이 과정에선 데이터에 대한 이해, 문제점, 목적, 대상, 배경, 의미 등에 대해 다양하게 탐색하며 데이터에 대한 모든 궁금한 것에 대해 조사한다. 또한, data의 불균형, 누락, 중복 등을 파악하여 성능을 개선하기 위한 다양한 방안을 마련하는 과정이다. 또한 모델 학습을 한 다음에도, 성능이 떨어지면 왜 떨어지는지, 오르면 왜 오르는지에 대해 데이터를 조사하는 이 과정도 결구 EDA이다.
즉, EDA는 순서로만 보면 앞에 있지만, 실제론 어느 과정에서라도 질문이 있으면 데이터에 대해 조사하는 하기에 EDA는 모든 과정 중간중간에 지속적으로 진행하게 된다.
이정도면 어느 정도 EDA에 대해서는 파악을 했다고 본다. 그렇다면 이번 P stage에서 진행하는 이미지 데이터에 대해서는, 데이터의 CH별 gray level을 구하여 비교할 수 있다. 그 이외에도 다양한 분석을 할 수 있으며, 모델 성능을 개선할 수 있다.
이처럼 초기 단계로 구분한 overview, eda지만 그 두 과정에서 앞으로의 진행 방향, 결과, 학습 등 모든 부분에 필요한 내용을 얻을 수 있다.
