Training & Inference 1 (1/2)
강의 소개
이제 정말 본격적으로 학습과 추론 프로세스를 시작합니다.
앞서 정의한 데이터셋, 모델, Loss, Optimizer, Metric을 가지고 실제 파이토치가 모델의 파라미터를 업데이트 하는 과정과 방식을 조금 디테일하게 접근해보겠습니다. 각각의 요소들이 하는 일과, 그로 인해 발생할 수 있는 side effect들이 모델을 업데이트하는 과정을 하나하나 보도록 하겠습니다.
그리고, 모델을 추론하고 제출하는 것도 간략히 다루겠습니다.
마지막으로, Pytorch Lightning이 어떤 것인지 간략히 다루겠습니다.
아래와 같이 모델링이 끝난 이후이므로 이제 학습을 시작해야 한다.
학습 프로세스에 필요한 요소는 아래 세 개로 나눌 수 있다. Loss는 예측 결과와 실제 결과의 차이를 측정하고, aptimizer는 그 타이를 토대로 역전파 과정을 진행하여 얻은 gradient를 통해 weight를 업데이트하고, 마지막 Metric은 현재 모델의 성능을 평가한다.

Loss
다양한 loss가 있으며, 선택한 loss에 따라서 결과가 좌우된다. loss는 nn 패키지에 포함되어 있어서 동일하게 forward() 함수를 가지고 있어서 모델과 loss가 연결될 수 있다.

그렇다면 어떻게 연결되어 있는 것일까?
training 과정을 보면 input을 model에 넣고 output이 출력되는데, 이 model 역시 forward 과정에서 각 layer를 연결시켜 놓았음을 알고 있다. 따라서 input과 output이 연결되어 있다고 생각할 수 있다. 그 다음 loss도 forward()과정이 있으며 output과 label 사이의 특정 연산을 통해 구한 값이므로 이 역시 연결되어 있다고 볼 수 있다. 즉 input~loss까지 연결되어 있다고 볼 수 있다. 이 forward 과정에서 연산을 진행하며 각 gradient를 정의를 하며 지나간다. 따라서, 연결된 관계에서 bacward()를 하면 grad를 바탕으로 역순으로 진행하며 각 layer의 weight와 bias를 학습시켜줄 수 있다.
단, parameter는 nn.Parameters() 인스턴스로 되어 있어야 하며, requires_grad=True로 되어 있어야 학습이 된다.
지정된 loss에서 error를 만들어내는 과정에서 조금 도움을 줄 수 있다.
첫 번쨰로, imbalanced class 문제인 경우, 맞춘 확률이 높은 class에 대해선 낮은 가중치를, 적게 맞춘 class에 대해선 높은 가중치를 부여하여 학습을 조절할 수 있다.
두 번째로, 실제 class는 정확인 one-hot incoding처럼 딱딱 떨어지는게 아니라, 특정 class이지만 다른 class의 특징도 어느 정도 내포하고 있다. 따라서 0 1 0 0 이 아니라 0.05,0.05,0.05, 0.85 등과 같이 조금 osft하게 표현하여 일반화 성능을 높일 수 있다.

optimizer
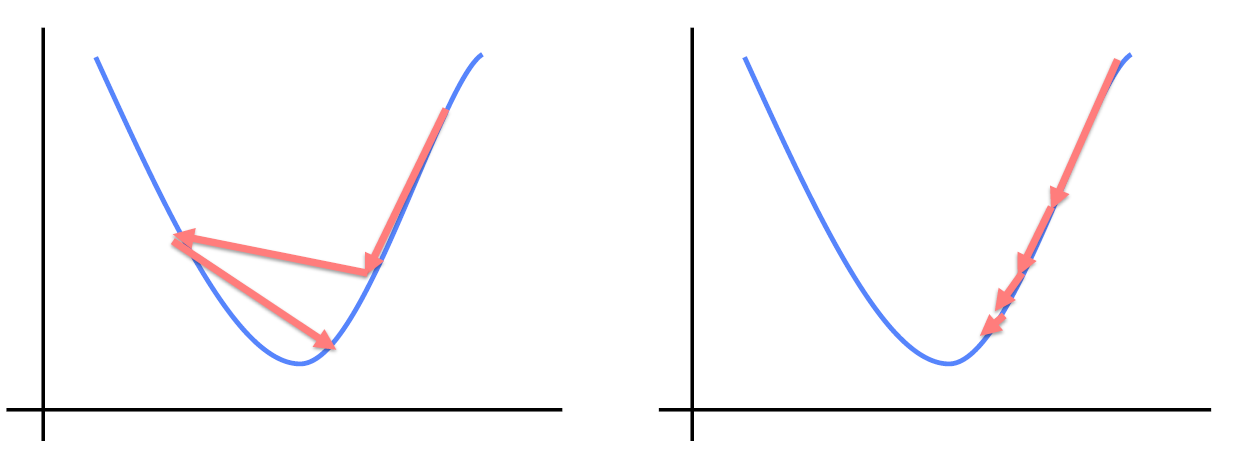
optimizer는 다양하게 있지만 일부를 제외하고는 학습률이 크게 영향을 미친다. 그렇다면 학습률은 어떻게 선택하면 좋을까?

고정된 lr를 부여할 경우, 다음과 왼쪽과 같이 빠르게 변화하지만 minima를 찾기는 어렵다. 하지만 우측처럼 움직이면 minima 근처에선 minima를 찾기 위해 조금씩 움직이며 더 근접할 수 있을 것이다. 이 같은 것을 scheduler라고 하며 torch.optim에는 다양한 scheduler가 존재한다.
가장 기본적으로, 고정된 step만큼 만큼 진핸하면 학습률을 줄이는 방식으로 구현된 stopLR이다.
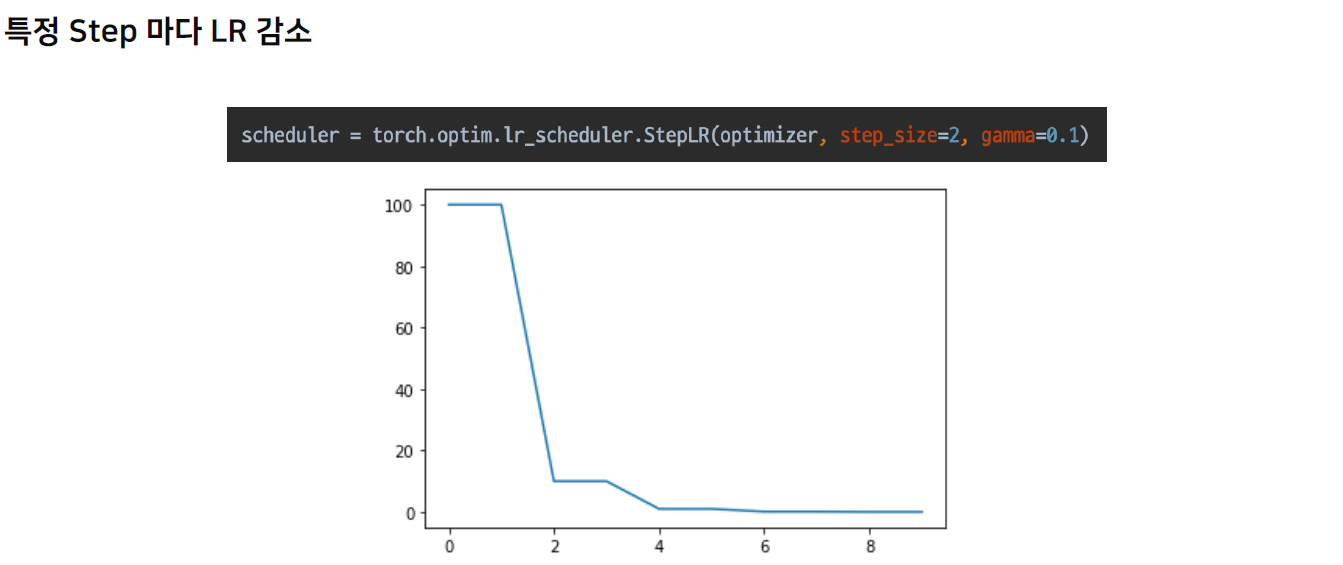
다음은, CosianAnnealingLR으로, 격하게 변화는 lr을 바탕으로 변화를 다양하게 줄 수 있는 장점이 있다. 따라서 lr이 크면 많이, lr이 작으면 적게 움직이게 할 수 있으며, local minima에 빠졌을 때 효과적으로 탈출할 수 있는 장점도 가지고 있다.
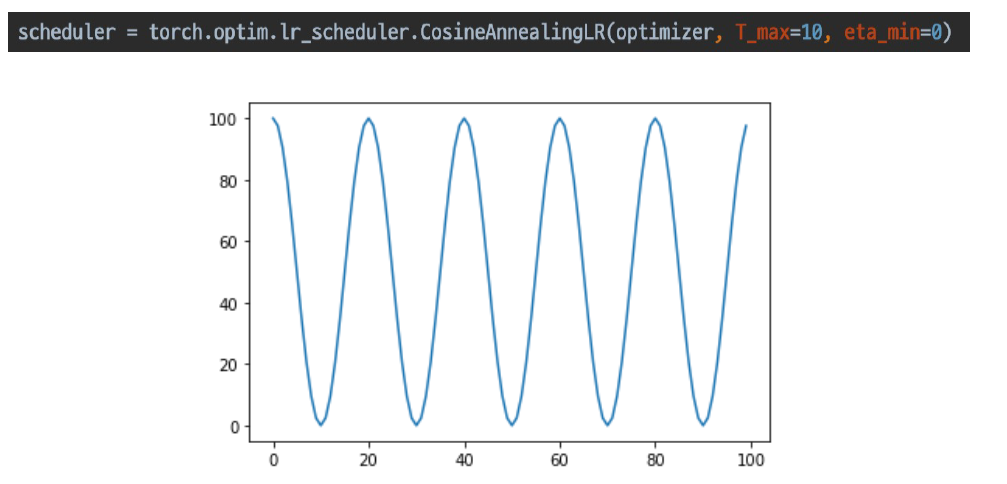
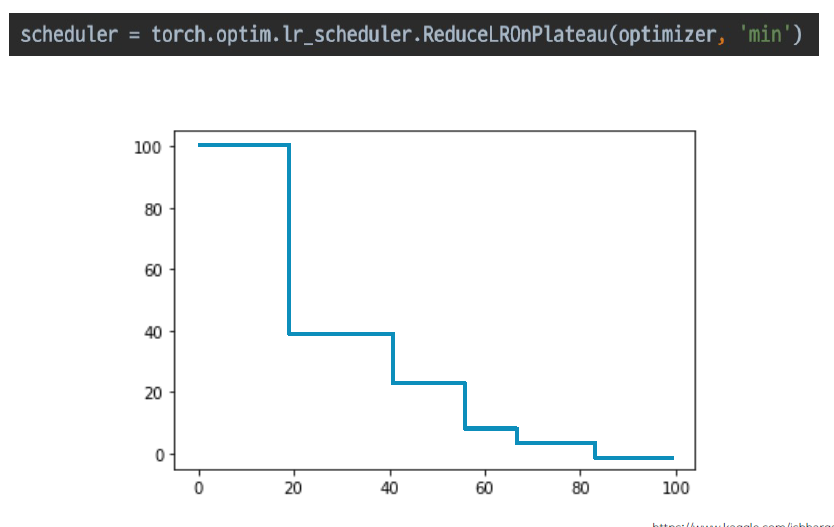
다음은, ReduceLROnPlateau로, 관찰된 성능이 몇 step이상 개선이 없는 경우 lr을 감소시켜가며 진행된다.
Metric
Metric은 학습에 직접적인 영향을 주진 않지만, 모델 평가에 객관적 지표로 사용되므로 어떻게 평가하는 것에 따라서 성능을 매우 다르게 볼 수 있다.
평가 지표로는 아래와 같이 다양하게 존재한다.
- Classification : accuracy, F1-score, Precision, recall, ROC&AUC
- Regression : MAE, MSE
- Ranking : MRR, NDCG, MAP
Training & Inference 2 (2/2)
강의 소개
이제 정말 본격적으로 학습과 추론 프로세스를 시작합니다.
앞서 정의한 데이터셋, 모델, Loss, Optimizer, Metric을 가지고 실제 파이토치가 모델의 파라미터를 업데이트 하는 과정과 방식을 조금 디테일하게 접근해보겠습니다. 각각의 요소들이 하는 일과, 그로 인해 발생할 수 있는 side effect들이 모델을 업데이트하는 과정을 하나하나 보도록 하겠습니다.
그리고, 모델을 추론하고 제출하는 것도 간략히 다루겠습니다.
마지막으로, Pytorch Lightning이 어떤 것인지 간략히 다루겠습니다.
Inference.Process
- Training 준비
- Training 프로세스 이해
- More: Gradient Accumulation
- Inference 프로세스 이해
- Validation
- Checkpoint
7강까지 전처리를 완료한 데이터로 데이터셋을 만든 다음 모델을 학습을 시키는데 그 과정에서 필요한 도구들에 대해서 알아봤다면 이제는 그 프로세스에 대한 이해 공부할 예정이다.
Model.train()
모델 학습을 시작하면 weight가 requires_grad=True로 되어있는데 굳이 train mode로 바꿔줘야 하는 가에 대해 의문이 들 수 있는데, 바꿔줘야 한다. 아래 자료는 torch의 api 문서 내용으로, training mode와 evaluation mode에서는 Dropout이나 BatchNorm과 같은 효과들이 다르게 적용되어야 하는데, 이 모드 변경을 통해 조절할 수 있다. 따라서 반드시 train 모드로 변경하여 학습을 진행해야 한다.

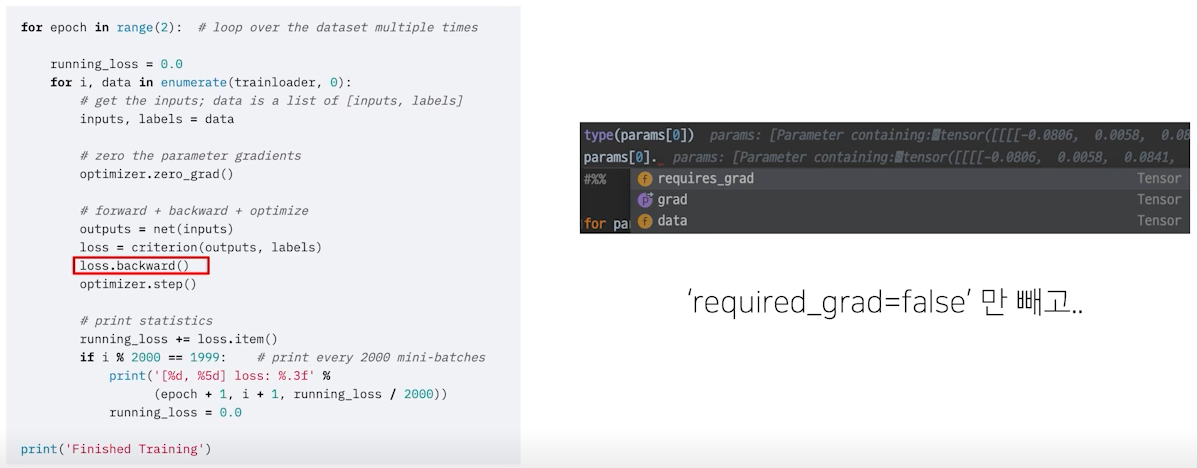
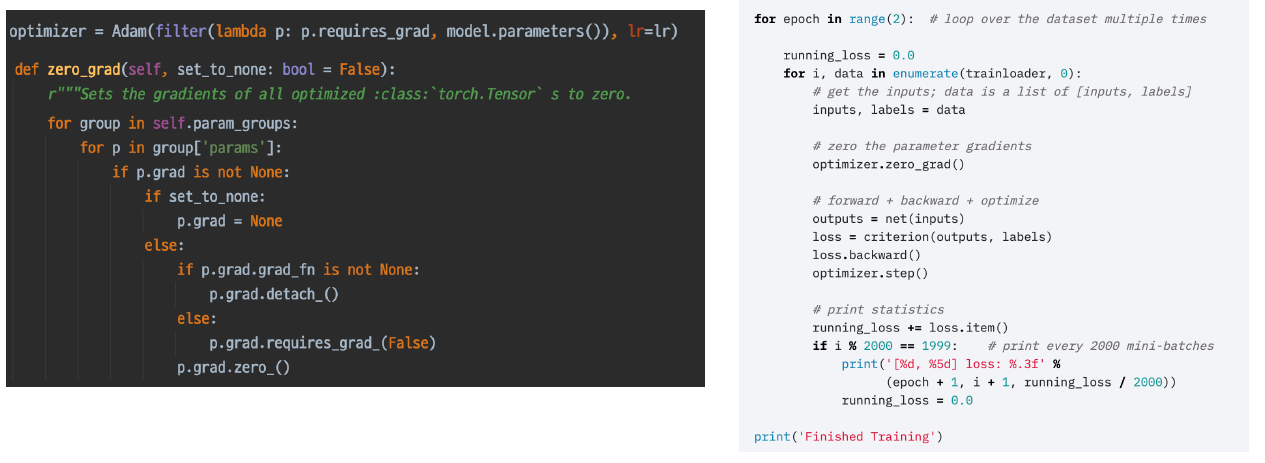
optimizer.zero_grad()
학습 프로세스는 epoch만큼 for loop을 돌리고, 전체 데이터에 대해 dataloader에서 batch_size 만큼씩 inputs과 labels를 반복적으로 뽑아서 학습을 진행하는데, 이 때 만나는 것은 optmizer.zero_grad()이다.
위에서 언급한대로 각 과정은 연결되어 있어서 각 연산마다 gradient 값을 계산하여 갖고 있는데, 만약 그 값의 초기 값이 이전 학습의 gradient로 되어 있으면 이전 학습의 loss도 현재 고려되는 것으로 학습이 정상적으로 이뤄지지 않는다. 따라서 이전 학습의 loss로 update한 weight를 가지고 다시 현재 loss에 대해 weight를 학습시키려면 학습 시작마다 gradient 값을 0으로 변경해준 다음 gradient를 저장해야 한다.
물론 이 경우는 일반적이며, 방법론에 따라 gradient를 다르게 조작할 수 있다.
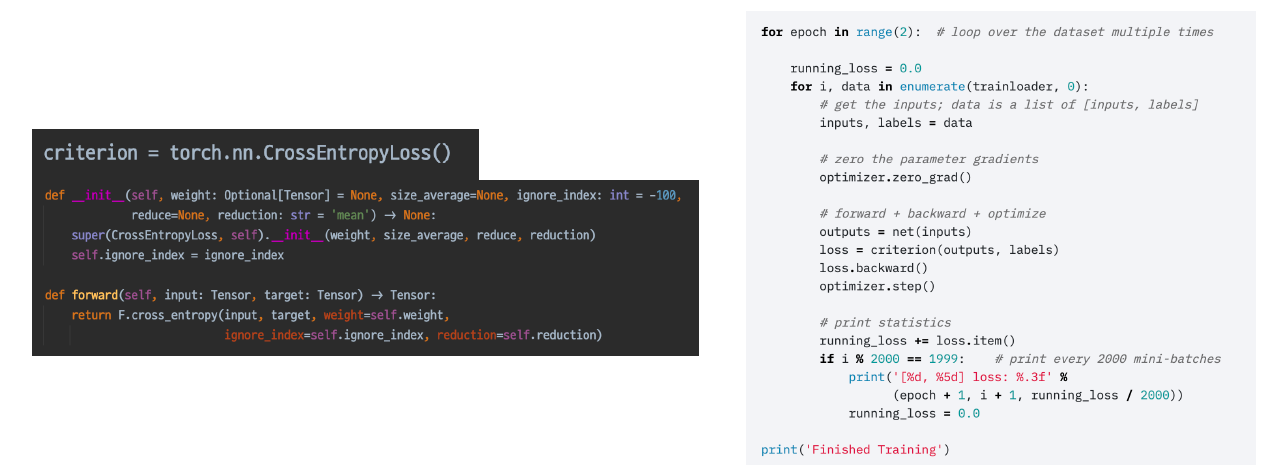
Loss=criterion(outputs, labels)
7강 내용에서 자세히 얘기했듯이, nn.Module을 상속받아서 forward 함수로 구현되어 있어서 input부터 loss까지 연결되어 있으며, 이 값을 토대로 역전파 과정이 진행된다.
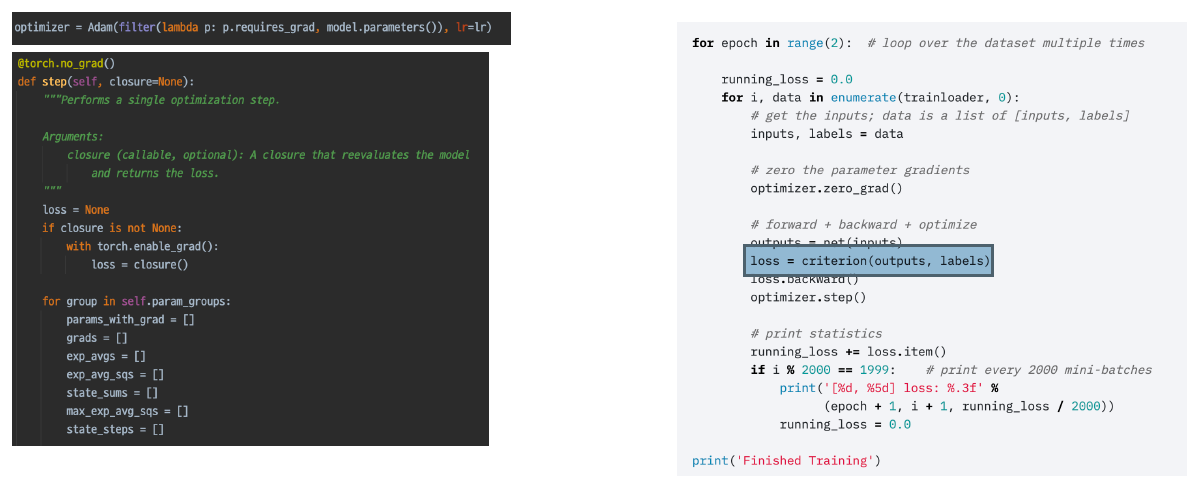
optimizer.step()
하지만 사실 loss가 하는 역할은 손실비용을 계산하여 gradient를 업데이트하는 것는 것 뿐이며, 그 업데이트된 값을 파라미터에 적용하는 것은 optimizer다. loss를 토대로 backward()가 되었기에, 각 parameter들은 grad가 특정값을 가진 채로 업데이트되어 있으며, step()을 할 경우 업데이트가 수행된다. 업데이트에 대한 방법은 optimizer에서 정의한 방법을 따른다.
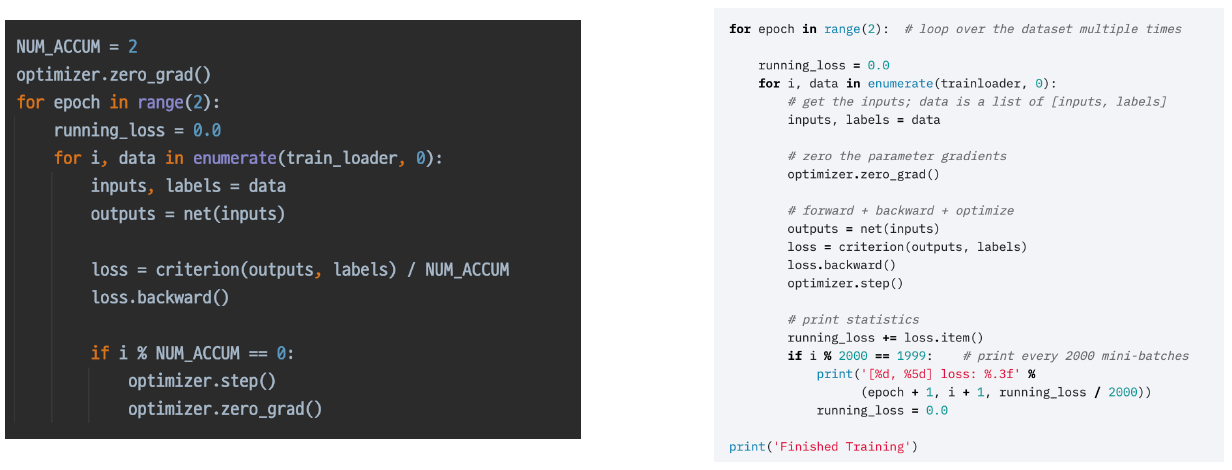
More:Gradient Accumulation
이전까지 일반적인 방법이며, 이것을 토대로 다른 방법을 적용해볼 수 있다.
고정된 batch size로 작업을 하는데, GPU 메모리는 한정적이다. 따라서 batch가 가지고 있는 데이터를 토대로 학습을 진행하는데, 특정 task의 경우 batch size가 매우 중요한 경우가 있다. 따라서 많은 큰 batch를 한 번에 담아야 하는데 GPU 메모리 부족으로 그럴 수 없는 경우가 있다. 그럴 때 사용하는 것이 gradient acccumulation 기법이다.
아래와 같이 batch를 n개가 쌓일 때마다 gradient를 업데이트 해주는 방식으로 하는 것이다. 이렇게 한다면 작은 batch_size로 큰 batch_size로 학습하는 것과 유사한 효과를 낼 수 있다.
Inference 프로세스 이해
검증 시 model.eval()로 모드 변경을 해주며, 이 역할은 model.train()과 동일하다.
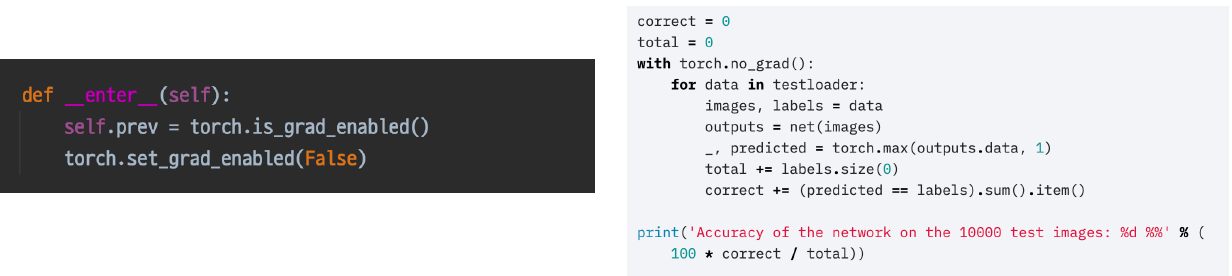
with torch.no_grad():
추론 시 학습을 시키고 싶지 않을 때 아래와 같이 with.torch.no_grad()를 하면 학습 과정에 대한 gradient를 계산하지 않는다는 의미이다. 이 과정에선 torch.is_grad_enabled()가 False로 변경된다.
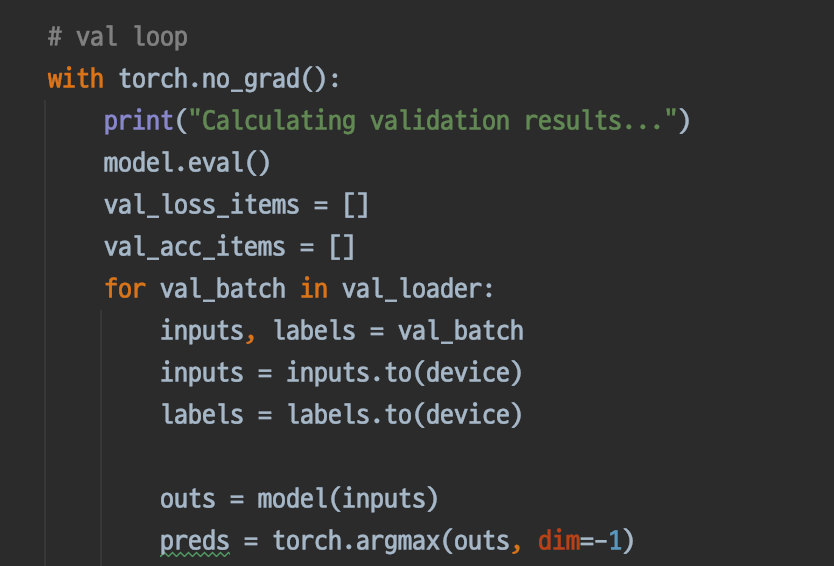
Validation 확인
검증은 단순히, 추론을 통해 나온 ouput이 어떤 식으로 나온지 확인하면 된다.
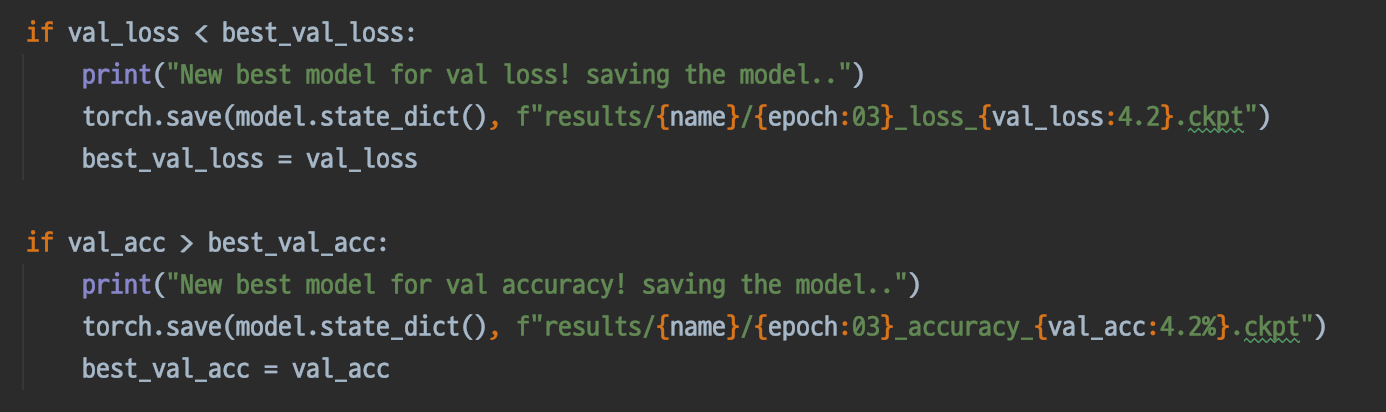
CheckPoint
validation 과정에서 해볼 수 있는 건, 잘 훈련된 결과물을 저장하는 것이다. 코드는 아래와 같으며, validation 단계에서 진행하는 이유는, validation data는 training에 fit 되어 있지 않기 때문이다.
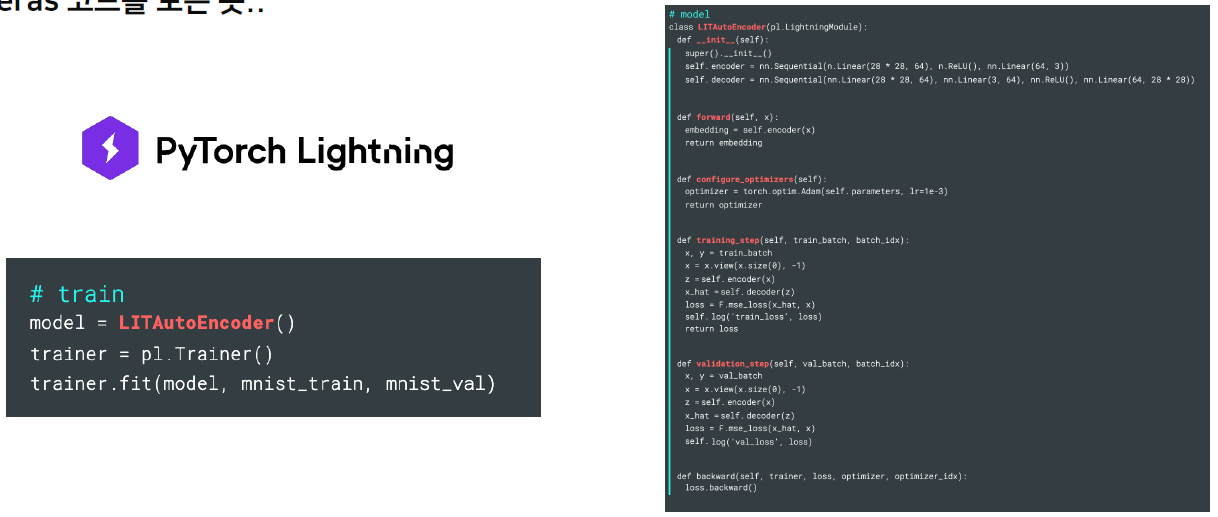
학습을 진행하는 단계에서는 이러한 과정들을 모두 익히는게 중요하지만, 현업에서는 생산성이 매우 중요하다. 따라서 그 배경에 만들어진 것이 Pytorch Lightining이다
Pytorch Lightining
기존까지 우측과 같이 코드를 작성하며 모델을 만들어서 학습을 시켰다면, Pytorch Lightining은 왼쪽과 같이, 마치 tensorflow를 사용하는 것처럼 간편하게 fit 하나로 할 수 있다. 하지만 이것은 개발 관점이고, 전 과정을 이해한 다음 사용해야 Pytorch Lightining의 함축 코드를 이해할 수 있을 것이다.