테스트코드
- End-to-end tests: 최종 사용자의 흐름에 대한 테스트이며 외부로부터 요청부터 응답까지 기능이 잘 작동하는지에 대한 테스트
- Intergration tests: 코드의 주요 흐름들을 통합적으로 테스트하며 주요 외부 의존성(데이터베이스...)에 대해서 테스트
- Unit tests: 도메인 모델과 비즈니스 로직 테스트, 작은 단위의 코드 및 알고리즘 테스트
Array, LinkedList
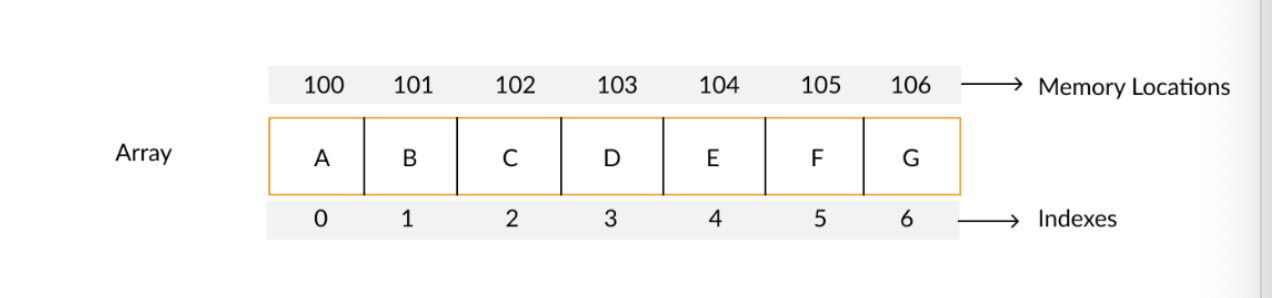
Array
- 입력된 데이터들이 메모리 공간에서 연속적으로 저장되어 있는 자료 구조
- index를 통한 접근이 용이하다
- 배열의 중간에 삽입 및 삭제: O(n)
- 배열의 끝 삽입 및 삭제: O(1)
Linked list
- 여러 개의 노드들이 순차적으로 연결된 형태를 갖는 자료구조 (첫 번째 노드 : head, 마지막 노드: tail)
- 각 노드는 데이터와 다음 노드를 가리키는 포인터로 이루어져 있다.
- 배열과 다르게 메모리를 연속적으로 사용하지 않는다.
- 삽입 삭제에 용이
- Tree 구조의 근간이 되는 자료구조
- 임의 접근이 불가능하여, 처음부터 탐색을 진행해야 한다.
AWS S3, EC2
_ EC2는 인스턴스로 클라우드 기반의 서버에 접근하는 녀석이고, S3는 데이터를 저장하는 데 사용된다. EC2는 클라우드에서 다양한 애플리케이션을 작동하는 데 솔루션이 될 수 있다. 하지만 정적 데이터를 필요로 할 수 있다. S3는 웹사이트 호스팅 데이터처럼 정적 데이터에 대해 scalable한 스토리지를 제공한다. S3는 서버의 세션 데이터와 같이 동적인 데이터에 대해서는 이상적이지 않을 수 있다. EC2는 적은 노력으로 클라우드 환경에서 서버를 작동하게 해주는 녀석이고, S3는 대량의 정적 데이터를 저장하도록 설계되었고, 데이터 백업을 용이하게 한다.
정렬 알고리즘
n개의 숫자가 입력으로 주어졌을 때, 이를 사용자가 지정한 기준에 맞게 정렬하여 출력하는 알고리즘
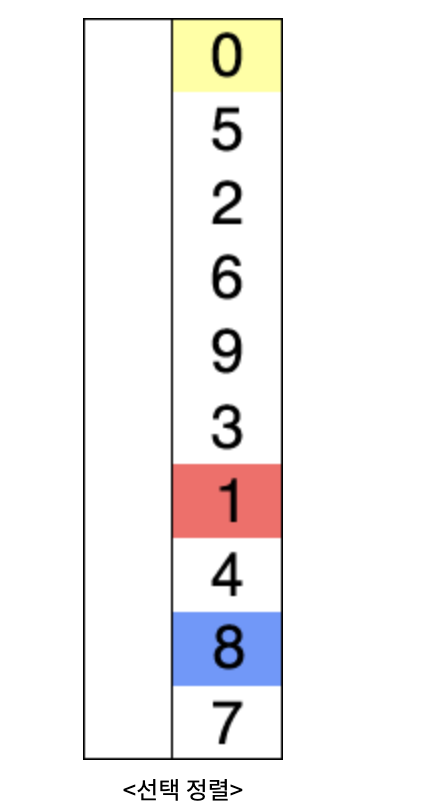
선택 정렬
전체 비교를 진행하므로 시간복잡도는 O(n^2)이다. 공간복잡도는 단 하나의 배열에서만 진행하므로 O(n)이다.
삽입 정렬
현재 위치에서 그 이하의 배열들을 비교하여 자신이 들어갈 위치를 찾아 그 위치에 삽입하는 배열 알고리즘
버블 정렬
매번 연속된 두 개의 인덱스를 비교하여 정한 기준의 값을 뒤로 넘겨 정렬하는 방법
합병 정렬
분할 정복 방식으로 설계된 알고리즘. 분할 정복은 큰 문제를 반으로 쪼개 문제를 해결해나가는 방식으로 분할은 배열의 크기가 1보다 작거나 같을 때까지 반복한다. 합병은 두 개의 배열을 비교하여 기준에 맞는 값을 다른 배열에 저장해 나간다.
퀵 정렬
pivot point라고 기준이 되는 값을 하나 설정하고 이 값을 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽으로 옮기는 방식으로 정렬을 진행한다. 이를 반복하여 배열의 크기가 1이 되면 배열이 모두 정렬이 된 것이다.
